Android安全-初窺ARM平坦化還原
推荐 原创【Android安全-初窺ARM平坦化還原】此文章归类为:Android安全。
前言
上周在看DASCTF的題發現難得有一道安卓( 題目名:RealeazyRealeazy ),興致勃勃地打開IDA卻發現了這可悲的控制流平坦化,當場直接自閉…
之後分析了下發現這ollvm應該算是比較簡單的那類( 只有間接跳轉 + 最普通的平坦化,貌似沒有虛假分支/虛假塊 ),於是決定好好地學習下怎麼還原。
一開始是想按「使用unidbg还原标准ollvm的fla控制流程平坦化」一樣使用Unidbg來還原,後面發現分支的情況用Unidbg不太好處理。
最後還是決定用Unicorn的模擬執行來還原,具體思路&實現完全參考「[原创]ARM64 OLLVM反混淆」。
還原思路
利用Unicorn來模擬執行,從而獲取程序的執行流程,主要有以下步驟:
- 識別&保存函數所有的真實塊,有兩種識別思路,要麼通過真實塊的特徵,要麼通過非真實塊的特徵,看哪種特徵比較明顯,對本例來說真實塊有個明顯的特徵就是
mov pc, r0這樣的間接跳轉。 - 模擬執行並保存執行路徑,遇到分支時就手動修改寄存器的值來遍歷( 本例沒有虛假分支,不用考慮太多,直接2條分支都執行就可以 )。
模擬執行過程中遇到bl、blx這樣的函數調用時可以直接跳過( 通過修改PC來實現 ),因為我們關注的只有執行流程,同理遇到一些Unicorn無法解析的指令時也是直接跳過就可以( 只要不是真實塊的頭/尾指令就可以 ) - 根據上述得出的執行流來patch。
具體實現
collect_blocks
首先是收集各種塊的邏輯,通過capstone來遍歷so文件,offset和end分別是某函數的起始、結束地址,block_list用來保存所有塊( 以塊的起始地址作為鍵,而值是包含當前塊各種信息的block_item )。
如何判斷塊的結尾?通過觀察so文件可以知道,一個塊要麼以mov pc, r0結束,要麼以b XXX結束,而前者更是真實塊的特徵。
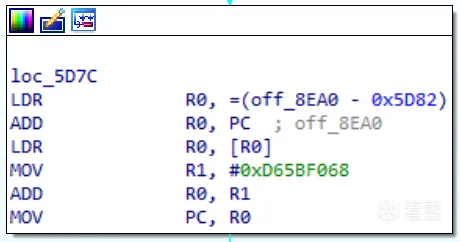
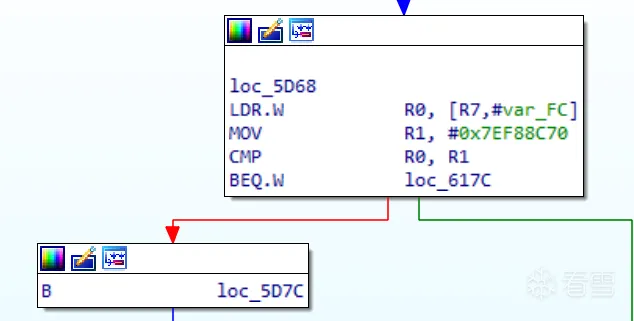
除了真實塊外,預處理塊也是以mov pc,r0結尾,顯然需要將其排除在外,不能讓其保存在real_blocks中。這裡我使用了IDA Python來提前找出所有預處理器的起始地址,實現思路是遍歷找出那些入度為n且出度為1 的塊( 很簡單但對本例很有效 )。
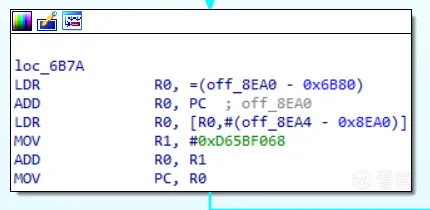
IDA Python script for finding preprocessor
123456789101112131415161718192021222324252627282930313233343536373839404142434445importida_xrefimportidcimportida_segmentdefget_all_cref_to(addr):all_xref=[]ref=ida_xref.get_first_cref_to(addr)whileref !=0xffffffff:all_xref.append(ref)ref=ida_xref.get_next_cref_to(addr, ref)returnall_xrefdefget_all_cref_from(addr):all_xref=[]ref=ida_xref.get_first_cref_from(addr)whileref !=0xffffffff:all_xref.append(ref)ref=ida_xref.get_next_cref_from(addr, ref)returnall_xrefdefis_preproc(addr):all_xref_to=get_all_cref_to(addr)all_xref_from=get_all_cref_from(addr)# 多個入度(具體取值要看情況) && 一個出度returnlen(all_xref_to) >5andlen(all_xref_from)==1preproc_addr_list=[]defget_preprocessor(seg):globalpreproc_addr_listprint("====================================")addr=seg.start_eaend_addr=seg.end_eawhileaddr < end_addr:ifis_preproc(addr):preproc_addr_list.append(addr)addr=idc.next_head(addr)defmain():get_preprocessor(ida_segment.get_segm_by_name('.mytext'))get_preprocessor(ida_segment.get_segm_by_name('.text'))print(preproc_addr_list)main()
具體實現代碼如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | def collect_blocks(offset, end, ret_addr): global block_list # 保存所有塊 global real_blocks # 保存真實塊 global ret_blocks # 保存ret 塊 global md block_list = {} real_blocks = [] ret_blocks = [] md = Cs(CS_ARCH_ARM, CS_MODE_THUMB) md.detail = True preproc_flag = False ins_str = "" is_new = True for dasm in md.disasm(sodata[offset:end], offset): # 這裡是數據, 不用保存為block if dasm.address >= 0x612E and dasm.address < 0x617C: continue ins_str += f"{hex(dasm.address)}:\t{dasm.mnemonic}\t{dasm.op_str}\n" # 在塊的起如地址保存對應信息 if is_new: is_new = False block_item = {} block_item["start_addr"] = dasm.address block_item["capstone"] = dasm # 判斷當前地址是否預處理器的起始地址 if is_preproc(dasm.address): preproc_flag = True if is_block_end(dasm): is_new = True block_item["end_addr"] = dasm.address block_item["ins_str"] = ins_str ins_str = "" block_list[block_item["start_addr"]] = block_item # 初步獲取real_blocks, 這個特徵僅針對本例 if dasm.mnemonic == "mov" and dasm.op_str == "pc, r0": if preproc_flag: preproc_flag = False else: real_blocks.append(block_item["start_addr"]) # 手動添加arm的ret block (從IDA裡找出度為0的那塊) ret_blocks.append(ret_addr)def is_block_end(dasm): if dasm.mnemonic == "mov" and dasm.op_str == "pc, r0": return True if dasm.mnemonic == "b": return True return Falsedef is_preproc(addr): # 由IDA Python得出 preprocessor_addrs = [27514, 3200, 5784, 10490, 15456, 17002, 19836, 20578, 22440] return addr in preprocessor_addrs |
init_unicorn
初始化Unicorn的模擬執行環境,這裡我們不需要考慮傳參之類的東西。hook_code是指令hook的回調函數,也是最關鍵的邏輯所在,後面會重點介紹。hook_mem_access是內存訪問異常時的回調,對本例的用處不大。
這裡設置.data節是因為程序的間接條跳依賴於其中的數據,若不添加程序將無法執行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | def init_unicorn(filename): global mu global sodata if isinstance(sodata, bytearray): sodata = bytes(sodata) mu = Uc(UC_ARCH_ARM, UC_MODE_THUMB) mu.mem_map(0x80000000, 0x1000 * 8) # 初始化stack mu.mem_map(0, 4 * 1024 * 1024) mu.mem_write(0, sodata) mu.reg_write(UC_ARM_REG_SP, 0x80000000 + 0x1000 * 4) mu.hook_add(UC_HOOK_CODE, hook_code) mu.hook_add(UC_HOOK_MEM_UNMAPPED, hook_mem_access) # 設置.data節 data_section = get_section(filename, '.data') DATA_MEM_OFFSET = data_section.header["sh_addr"] DATA_FILE_OFFSET = data_section.header["sh_offset"] DATA_SIZE = data_section.header["sh_size"] mu.mem_write(DATA_MEM_OFFSET, sodata[DATA_FILE_OFFSET:DATA_FILE_OFFSET+DATA_SIZE]) |
start_emu
正式開始模擬執行,會模擬執行若干次,每次會從某真實塊出發,直到找到另一個真實塊/結束塊為至。
用queue來保存模擬執行的順序以及對應的上下文,保存上下文是因為分支要走兩條路,當走完一條分支時通過恢復上下文來達到一種回溯的效果,從而繼續走第二條分支。通過這種方法就能遍歷完所有可能的真實塊,但對於有虛假分支的情況,這樣做可能會導致死循環,但反過來想也是一種檢測虛假分支的思路。
itt是本例的真實塊裡的分支指令,具體處理的邏輯在hook_code中,這裡提前判斷的目的是為了手動控制分支的走向。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 | def start_emu(offset): global is_success global flow if offset in real_blocks: real_blocks.remove(offset) queue = [(offset, None)] # 保存執行流, 最終patch就是靠它 flow = {} is_success = False while len(queue) != 0: env = queue.pop() pc = env[0] set_context(env[1]) item = block_list[pc] # 代表對應的路徑已被記錄, 無需重複 if pc in flow: continue flow[pc] = [] # 分支, 例如 0x62D6, 0x5FA2 if item["ins_str"].find("itt") != -1: ctx = get_context() p1 = find_path(pc, 0) if p1 != None: queue.append((p1, get_context())) flow[pc].append(p1) set_context(ctx) p2 = find_path(pc, 1) if p1 != p2: queue.append((p2, get_context())) flow[pc].append(p2) else: p = find_path(pc) if p != None: queue.append((p, get_context())) flow[pc].append(p) |
find_path
find_path的返回值是某真實塊的起始地址( 通過block_list能獲取該塊的所有信息 )。
在報錯時直接跳過導致報錯的指令( 通常是由於Unicorn不兼容某些指令所導致的報錯 ),可以直接跳過的原因是我們只關注會影響執行流的指令,其他無需理會。
要特別注意的是,本例是Thumb Mode,因此模擬執行的地址必須|1,否則會導致一連串奇怪的事情( 一開始沒留意被坑了很久…… )。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | def find_path(start_addr, branch = None): global real_blocks global mu global g_start_addr global branch_control global list_trace global dst_addr global is_success branch_control = branch g_start_addr = start_addr list_trace = {} dst_addr = 0 is_success = False try: mu.emu_start(start_addr | 1, start_addr + 0x10000) print("============= emu end =============") except UcError as e: pc = mu.reg_read(UC_ARM_REG_PC) if pc != 0: #mu.reg_write(UC_ARM64_REG_PC, pc + 4) # Thumb指令, 長度可能是2/4, 因此要動態獲取 _size = get_ins_size(pc) return find_path(pc + _size, branch) else: print("ERROR: %s pc:%x" % (e,pc)) if is_success: return dst_addr return None |
hook_code
最關鍵的邏輯,主要分成以下幾部分:
- 判斷當前地址是否屬於
real_blocks或ret_blocks,是則將該地址保存到dst_addr然後停止本次模擬執行。 - 判斷當前指令是否函數調用,是則修改PC的值以此跳過該函數調用,記得要
|1,這點特別坑!!! - 判斷
branch_control是否有值,是則代表需要處理分支的情況,當branch_control為0時執行False分支( 根據條件修改對應寄存器 ),以下圖為例,False分支是不執行紅框部分的那條分支,這點在最後的patch時會用到。
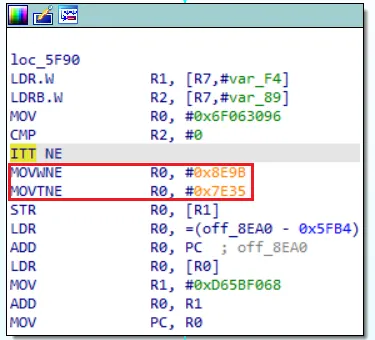
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 | def hook_code(uc, address, size, user_data): global is_success global mu global branch_control global g_start_addr global list_trace global dst_addr global end global md if is_success or address > end: mu.emu_stop() return ban_ins = ["bl", "blx"] if address in [0x5ED6]: # for debug print("debug addr: ", hex(address)) for ins in md.disasm(sodata[address:address+size], address): print(">>> Tracing instruction at 0x%x, instruction size = 0x%x" % (address, size)) print(">>> 0x%x:\t%s\t%s\t%d" % (ins.address, ins.mnemonic, ins.op_str, ins.size)) print_regs() if address in real_blocks: if address in list_trace: print("have fake block?") uc.emu_stop() else: list_trace[address] = 1 if address != g_start_addr: is_success = True dst_addr = address print(f"find: {hex(address)}") uc.emu_stop() return if address in ret_blocks: print(f"end_block: {hex(address)} ") mu.emu_stop() return flag_pass = False for b in ban_ins: if ins.mnemonic.find(b) != -1: flag_pass = True break # 內存操作 (對本例用處不大) if ins.op_str.find("[") != -1: # R7是棧底寄存器, 通常用來取局部變量 if ins.op_str.find("[r7") != -1 and ins.op_str.find("0xf4") != -1: print() if ins.op_str.find("[sp") != -1: flag_pass = True for op in ins.operands: if op.type == ARM_OP_MEM: reg_name = ins.reg_name(op.value.base) addr = mu.reg_read(reg_ctou(reg_name)) if addr >= 0x80000000 and addr < 0x80000000 + 0x10000 * 8: flag_pass = False if flag_pass: print(f"[pass] addr: {hex(ins.address)} size: {ins.size}") # 關鍵點: 要 |1 uc.reg_write(UC_ARM_REG_PC, (ins.address + ins.size) | 1) # uc.reg_write(UC_ARM_REG_PC, address + size) return if branch_control == None: return # ollvm 分支 # branch_control == 1代表條件成立, 如 cmp r1,r2、beq XXX -> r1 == r2 (目的是方便後續的patch) next_dasm = get_dasm(ins.address + ins.size, 4) if next_dasm.mnemonic == "itt" and next_dasm.op_str == "ne": if ins.mnemonic == "cmp": ops = ins.op_str.split(", ") reg = reg_ctou(ops[0]) if ops[1].startswith("#"): cmp_num = int(ops[1][1:], 16) else: assert ops[1].startswith("r") cmp_num = mu.reg_read(reg_ctou(ops[1])) if branch_control == 0: mu.reg_write(reg, cmp_num) else: mu.reg_write(reg, cmp_num + 1) elif ins.mnemonic == "tst": # tst r2, r3 ---> r2 & r3 , 改變z標誌 regs = [reg_ctou(x) for x in ins.op_str.split(", ")] if branch_control == 0: mu.reg_write(regs[0], 0) mu.reg_write(regs[1], 0) else: mu.reg_write(regs[0], 1) mu.reg_write(regs[1], 1) # 例: cmp r2, r3, cmp是r2 - r3, 當結果<0時, blt、bmi都會執行 elif next_dasm.mnemonic == "itt" and next_dasm.op_str == "lt" or \ next_dasm.mnemonic == "itt" and next_dasm.op_str == "mi" or \ next_dasm.mnemonic == "itt" and next_dasm.op_str == "lo": if ins.mnemonic == "cmp": ops = ins.op_str.split(", ") reg = reg_ctou(ops[0]) if ops[1].startswith("#"): cmp_num = int(ops[1][1:], 16) else: assert ops[1].startswith("r") cmp_num = mu.reg_read(reg_ctou(ops[1])) if branch_control == 0: mu.reg_write(reg, cmp_num + 1) else: mu.reg_write(reg, cmp_num - 1) # gt 是大於 elif next_dasm.mnemonic == "itt" and next_dasm.op_str == "gt": if ins.mnemonic == "cmp": ops = ins.op_str.split(", ") reg = reg_ctou(ops[0]) if ops[1].startswith("#"): cmp_num = int(ops[1][1:], 16) else: assert ops[1].startswith("r") cmp_num = mu.reg_read(reg_ctou(ops[1])) if branch_control == 0: mu.reg_write(reg, cmp_num - 1) else: mu.reg_write(reg, cmp_num + 1) # eq 是等於 elif next_dasm.mnemonic == "itt" and next_dasm.op_str == "eq": if ins.mnemonic == "cmp": ops = ins.op_str.split(", ") reg = reg_ctou(ops[0]) if ops[1].startswith("#"): cmp_num = int(ops[1][1:], 16) else: assert ops[1].startswith("r") cmp_num = mu.reg_read(reg_ctou(ops[1])) if branch_control == 0: mu.reg_write(reg, cmp_num - 1) else: mu.reg_write(reg, cmp_num) elif next_dasm.mnemonic == "itt": raise Exception("ollvm branch new type") |
start_patch
start_emu結束後的flow如下圖所示,很容易可以看到其中的規律,利用BFS來遍歷簡直再合適不過。
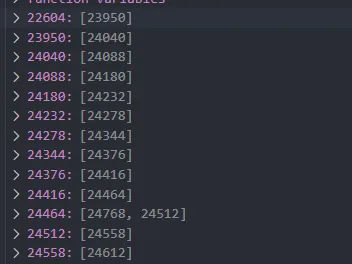
對於無分支的真實塊,可以直接通過b指令來跳轉,也可像我這樣修改r0來跳轉,因為本例本身就是將r0賦給pc來實現間接跳轉的,同時需要將一些字節patch為nop以防被干擾。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | def start_patch(flow, start_addr): global block_list global sodata sodata = bytearray(sodata) visited = {} queue = [start_addr] while len(queue) != 0: current_addr = queue.pop() if current_addr in visited or current_addr == None: continue visited[current_addr] = 1 next_blocks = flow[current_addr] rb_end_addr = block_list[current_addr]["end_addr"] rb_start_addr = block_list[current_addr]["start_addr"] # 1. 無分支的情況 if len(next_blocks) == 1: queue.append(next_blocks[0]) # 對本例, patch地址固定為真實塊最後指令地址 - 10 patch_addr = rb_end_addr - 10 next_start_addr = queue[-1] patch_nop(patch_addr, 10) if next_start_addr != None: asm_bytes = ks_asm(KS_ARCH_ARM, KS_MODE_THUMB, f"mov r0, #{hex(next_start_addr)}") patch_bytes(patch_addr, asm_bytes) print(f"{hex(patch_addr)} ---> {hex(next_start_addr)}") else: ret_block_addr = ret_blocks[0] asm_bytes = ks_asm(KS_ARCH_ARM, KS_MODE_THUMB, f"mov r0, #{hex(ret_block_addr)}") patch_bytes(patch_addr, asm_bytes) print(f"{hex(patch_addr)} ---> ret block: {hex(ret_block_addr)}") # 2. 有分支的情況 else: queue.append(next_blocks[0]) queue.append(next_blocks[1]) b0 = next_blocks[0] # branch_control為0的分支, False分支 b1 = next_blocks[1] # branch_control為1的分支, True分支 # patch_addr = rb_end_addr - 28 patch_addr = get_branch_pa(rb_start_addr) # find "itt" addr patch_branch(patch_addr, b0, b1) print(f"{hex(patch_addr)} --->\n\t1. {hex(b0)}\n\t2. {hex(b1)}") |
分支是像cmp r0,0; itt ne這樣的組合,只需將itt nepatch成bne addr1; b addr2就可以。傳入的addr就是itt ne的地址。
對於條件跳轉如beq、bne等,其跳轉的地址 = 目標地址 - 當前地址 - 4;而無條件跳轉直接跳到對應的絕對地址就可以。
條件跳轉後面跟的地址是b1_addr,這是True分支的真實塊的地址,這樣的處理是為了對應上述hook_code對分支的處理,兩者是有聯系的,不能隨便來。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | def patch_branch(addr, b0, b1): dasm = get_dasm(addr, 4) assert dasm.mnemonic == "itt" print(f"{hex(addr)}:\t{dasm.mnemonic}\t{dasm.op_str}") patch_nop(addr, 28 + 2) b1_addr = b1 - addr - 4 b0_addr = b0 branch_true_bytes = ks_asm(KS_ARCH_ARM, KS_MODE_THUMB, f"b{dasm.op_str} #{hex(b1_addr)}", addr) branch_false_bytes = ks_asm(KS_ARCH_ARM, KS_MODE_THUMB, f"b {hex(b0_addr)}", addr + len(branch_true_bytes)) patch_bytes(addr, branch_true_bytes) patch_bytes(addr + len(branch_true_bytes), branch_false_bytes) |
完整腳本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 | from capstone import *from capstone.arm import *from unicorn import *from unicorn.arm_const import *from keystone import *from elftools.elf.elffile import ELFFiledef get_section(filename, sectionName): file = open(filename, 'rb') elf_file = ELFFile(file) for section in elf_file.iter_sections(): if section.name == sectionName: return section# capstone寄存器 -> unicorn寄存器def reg_ctou(reg_name):# if reg_name == "sp": return UC_ARM_REG_SP if reg_name == "pc": return UC_ARM_REG_PC reg_idx = int(reg_name[1:]) if reg_idx >= 0 and reg_idx <= 12: return UC_ARM_REG_R0 + reg_idx raise Exception("reg_ctou: have new type?")def is_block_end(dasm): if dasm.mnemonic == "mov" and dasm.op_str == "pc, r0": return True if dasm.mnemonic == "b": return True return Falsedef hook_mem_access(uc, type, address,size,value,userdata): pc = uc.reg_read(UC_ARM_REG_PC) print('pc:%x type:%d addr:%x size:%x' % (pc, type, address, size)) #uc.emu_stop() return True def is_preproc(addr): # 由IDA Python得出 preprocessor_addrs = [27514, 3200, 5784, 10490, 15456, 17002, 19836, 20578, 22440] return addr in preprocessor_addrsdef get_context(): global mu return mu.context_save()def set_context(context): global mu if context == None: return mu.context_restore(context)def print_regs(): global mu msg = "" for i in range(8): msg += f"r{i}:{hex(mu.reg_read(UC_ARM_REG_R0 + i))}\t" msg += f"sp:{hex(mu.reg_read(UC_ARM_REG_SP))}\tpc:{hex(mu.reg_read(UC_ARM_REG_PC))}" print(msg)def get_ins_size(addr): for ins in md.disasm(sodata[addr:addr+4], addr): return ins.sizedef get_dasm(addr, size): global md global sodata for dasm in md.disasm(sodata[addr:addr+size], addr): return dasmdef hook_code(uc, address, size, user_data): global is_success global mu global branch_control global g_start_addr global list_trace global dst_addr global end global md if is_success or address > end: mu.emu_stop() return ban_ins = ["bl", "blx"] if address in [0x5ED6]: # for debug print("debug addr: ", hex(address)) for ins in md.disasm(sodata[address:address+size], address): print(">>> Tracing instruction at 0x%x, instruction size = 0x%x" % (address, size)) print(">>> 0x%x:\t%s\t%s\t%d" % (ins.address, ins.mnemonic, ins.op_str, ins.size)) print_regs() if address in real_blocks: if address in list_trace: print("have fake block?") uc.emu_stop() else: list_trace[address] = 1 if address != g_start_addr: is_success = True dst_addr = address print(f"find: {hex(address)}") uc.emu_stop() return if address in ret_blocks: print(f"end_block: {hex(address)} ") mu.emu_stop() return flag_pass = False for b in ban_ins: if ins.mnemonic.find(b) != -1: flag_pass = True break # 內存操作 (對本例用處不大) if ins.op_str.find("[") != -1: # R7是棧底寄存器, 通常用來取局部變量 if ins.op_str.find("[r7") != -1 and ins.op_str.find("0xf4") != -1: print() if ins.op_str.find("[sp") != -1: flag_pass = True for op in ins.operands: if op.type == ARM_OP_MEM: reg_name = ins.reg_name(op.value.base) addr = mu.reg_read(reg_ctou(reg_name)) if addr >= 0x80000000 and addr < 0x80000000 + 0x10000 * 8: flag_pass = False if flag_pass: print(f"[pass] addr: {hex(ins.address)} size: {ins.size}") # 關鍵點: 要 |1 uc.reg_write(UC_ARM_REG_PC, (ins.address + ins.size) | 1) # uc.reg_write(UC_ARM_REG_PC, address + size) return if branch_control == None: return # ollvm 分支 # branch_control == 1代表條件成立, 如 cmp r1,r2、beq XXX -> r1 == r2 (目的是方便後續的patch) next_dasm = get_dasm(ins.address + ins.size, 4) if next_dasm.mnemonic == "itt" and next_dasm.op_str == "ne": if ins.mnemonic == "cmp": ops = ins.op_str.split(", ") reg = reg_ctou(ops[0]) if ops[1].startswith("#"): cmp_num = int(ops[1][1:], 16) else: assert ops[1].startswith("r") cmp_num = mu.reg_read(reg_ctou(ops[1])) if branch_control == 0: mu.reg_write(reg, cmp_num) else: mu.reg_write(reg, cmp_num + 1) elif ins.mnemonic == "tst": # tst r2, r3 ---> r2 & r3 , 改變z標誌 regs = [reg_ctou(x) for x in ins.op_str.split(", ")] if branch_control == 0: mu.reg_write(regs[0], 0) mu.reg_write(regs[1], 0) else: mu.reg_write(regs[0], 1) mu.reg_write(regs[1], 1) # 例: cmp r2, r3, cmp是r2 - r3, 當結果<0時, blt、bmi都會執行 elif next_dasm.mnemonic == "itt" and next_dasm.op_str == "lt" or \ next_dasm.mnemonic == "itt" and next_dasm.op_str == "mi" or \ next_dasm.mnemonic == "itt" and next_dasm.op_str == "lo": if ins.mnemonic == "cmp": ops = ins.op_str.split(", ") reg = reg_ctou(ops[0]) if ops[1].startswith("#"): cmp_num = int(ops[1][1:], 16) else: assert ops[1].startswith("r") cmp_num = mu.reg_read(reg_ctou(ops[1])) if branch_control == 0: mu.reg_write(reg, cmp_num + 1) else: mu.reg_write(reg, cmp_num - 1) # gt 是大於 elif next_dasm.mnemonic == "itt" and next_dasm.op_str == "gt": if ins.mnemonic == "cmp": ops = ins.op_str.split(", ") reg = reg_ctou(ops[0]) if ops[1].startswith("#"): cmp_num = int(ops[1][1:], 16) else: assert ops[1].startswith("r") cmp_num = mu.reg_read(reg_ctou(ops[1])) if branch_control == 0: mu.reg_write(reg, cmp_num - 1) else: mu.reg_write(reg, cmp_num + 1) # eq 是等於 elif next_dasm.mnemonic == "itt" and next_dasm.op_str == "eq": if ins.mnemonic == "cmp": ops = ins.op_str.split(", ") reg = reg_ctou(ops[0]) if ops[1].startswith("#"): cmp_num = int(ops[1][1:], 16) else: assert ops[1].startswith("r") cmp_num = mu.reg_read(reg_ctou(ops[1])) if branch_control == 0: mu.reg_write(reg, cmp_num - 1) else: mu.reg_write(reg, cmp_num) elif next_dasm.mnemonic == "itt": raise Exception("ollvm branch new type") def find_path(start_addr, branch = None): global real_blocks global mu global g_start_addr global branch_control global list_trace global dst_addr global is_success branch_control = branch g_start_addr = start_addr list_trace = {} dst_addr = 0 is_success = False try: mu.emu_start(start_addr | 1, start_addr + 0x10000) print("============= emu end =============") except UcError as e: pc = mu.reg_read(UC_ARM_REG_PC) if pc != 0: #mu.reg_write(UC_ARM64_REG_PC, pc + 4) # Thumb指令, 長度可能是2/4, 因此要動態獲取 _size = get_ins_size(pc) return find_path(pc + _size, branch) else: print("ERROR: %s pc:%x" % (e,pc)) if is_success: return dst_addr return Nonedef patch_nop(addr, size): global sodata nop_bytes = bytearray(b'\x00\xbf') for i in range(size): sodata[addr + i] = nop_bytes[i % 2]def patch_bytes(addr, bytes: bytearray): for i in range(len(bytes)): sodata[addr + i] = bytes[i]def ks_asm(arch, mode, code, addr = 0): ks = Ks(arch, mode) encoding, count = ks.asm(code, addr) return bytearray(encoding)def patch_branch(addr, b0, b1): dasm = get_dasm(addr, 4) assert dasm.mnemonic == "itt" print(f"{hex(addr)}:\t{dasm.mnemonic}\t{dasm.op_str}") patch_nop(addr, 28 + 2) b1_addr = b1 - addr - 4 b0_addr = b0 branch_true_bytes = ks_asm(KS_ARCH_ARM, KS_MODE_THUMB, f"b{dasm.op_str} #{hex(b1_addr)}", addr) branch_false_bytes = ks_asm(KS_ARCH_ARM, KS_MODE_THUMB, f"b {hex(b0_addr)}", addr + len(branch_true_bytes)) patch_bytes(addr, branch_true_bytes) patch_bytes(addr + len(branch_true_bytes), branch_false_bytes)# 獲取分支的patch address (從addr向下查找, 直到itt指令)def get_branch_pa(addr): global md global sodata for dasm in md.disasm(sodata[addr:end], addr): # print(f"{hex(addr)}:\t{dasm.mnemonic}\t{dasm.op_str}") if dasm.mnemonic == "itt": return dasm.address raise Exception("cant find itt????")def start_patch(flow, start_addr): global block_list global sodata sodata = bytearray(sodata) visited = {} queue = [start_addr] while len(queue) != 0: current_addr = queue.pop() if current_addr in visited or current_addr == None: continue visited[current_addr] = 1 next_blocks = flow[current_addr] rb_end_addr = block_list[current_addr]["end_addr"] rb_start_addr = block_list[current_addr]["start_addr"] # 1. 無分支的情況 if len(next_blocks) == 1: queue.append(next_blocks[0]) # 對本例, patch地址固定為真實塊最後指令地址 - 10 patch_addr = rb_end_addr - 10 next_start_addr = queue[-1] patch_nop(patch_addr, 10) if next_start_addr != None: asm_bytes = ks_asm(KS_ARCH_ARM, KS_MODE_THUMB, f"mov r0, #{hex(next_start_addr)}") patch_bytes(patch_addr, asm_bytes) print(f"{hex(patch_addr)} ---> {hex(next_start_addr)}") else: ret_block_addr = ret_blocks[0] asm_bytes = ks_asm(KS_ARCH_ARM, KS_MODE_THUMB, f"mov r0, #{hex(ret_block_addr)}") patch_bytes(patch_addr, asm_bytes) print(f"{hex(patch_addr)} ---> ret block: {hex(ret_block_addr)}") # 2. 有分支的情況 else: queue.append(next_blocks[0]) queue.append(next_blocks[1]) b0 = next_blocks[0] # branch_control為0的分支, False分支 b1 = next_blocks[1] # branch_control為1的分支, True分支 # patch_addr = rb_end_addr - 28 patch_addr = get_branch_pa(rb_start_addr) patch_branch(patch_addr, b0, b1) print(f"{hex(patch_addr)} --->\n\t1. {hex(b0)}\n\t2. {hex(b1)}")def load_file(filename): global sodata with open(filename, mode = "rb") as f: sodata = f.read()def save_file(filename): with open(filename, mode="wb") as f: f.write(sodata)def collect_blocks(offset, end, ret_addr): global block_list # 保存所有塊 global real_blocks # 保存真實塊 global ret_blocks # 保存ret 塊 global md block_list = {} real_blocks = [] ret_blocks = [] md = Cs(CS_ARCH_ARM, CS_MODE_THUMB) md.detail = True preproc_flag = False ins_str = "" is_new = True for dasm in md.disasm(sodata[offset:end], offset): # 這裡是數據, 不用保存為block if dasm.address >= 0x612E and dasm.address < 0x617C: continue ins_str += f"{hex(dasm.address)}:\t{dasm.mnemonic}\t{dasm.op_str}\n" # 在塊的起如地址保存對應信息 if is_new: is_new = False block_item = {} block_item["start_addr"] = dasm.address block_item["capstone"] = dasm # 判斷當前地址是否預處理器的起始地址 if is_preproc(dasm.address): preproc_flag = True if is_block_end(dasm): is_new = True block_item["end_addr"] = dasm.address block_item["ins_str"] = ins_str ins_str = "" block_list[block_item["start_addr"]] = block_item # 初步獲取real_blocks, 這個特徵僅針對本例 if dasm.mnemonic == "mov" and dasm.op_str == "pc, r0": if preproc_flag: preproc_flag = False else: real_blocks.append(block_item["start_addr"]) # 手動添加arm的ret block (從IDA裡找出度為0的那塊) ret_blocks.append(ret_addr)def init_unicorn(filename): global mu global sodata if isinstance(sodata, bytearray): sodata = bytes(sodata) mu = Uc(UC_ARCH_ARM, UC_MODE_THUMB) mu.mem_map(0x80000000, 0x1000 * 8) # 初始化stack mu.mem_map(0, 4 * 1024 * 1024) mu.mem_write(0, sodata) mu.reg_write(UC_ARM_REG_SP, 0x80000000 + 0x1000 * 4) mu.hook_add(UC_HOOK_CODE, hook_code) mu.hook_add(UC_HOOK_MEM_UNMAPPED, hook_mem_access) # 設置.data節 data_section = get_section(filename, '.data') DATA_MEM_OFFSET = data_section.header["sh_addr"] DATA_FILE_OFFSET = data_section.header["sh_offset"] DATA_SIZE = data_section.header["sh_size"] mu.mem_write(DATA_MEM_OFFSET, sodata[DATA_FILE_OFFSET:DATA_FILE_OFFSET+DATA_SIZE])def start_emu(offset): global is_success global flow if offset in real_blocks: real_blocks.remove(offset) queue = [(offset, None)] # 保存執行流, 最終patch就是靠它 flow = {} is_success = False while len(queue) != 0: env = queue.pop() pc = env[0] set_context(env[1]) item = block_list[pc] # 代表對應的路徑已被記錄, 無需重複 if pc in flow: continue flow[pc] = [] # 分支, 例如 0x62D6, 0x5FA2 if item["ins_str"].find("itt") != -1: ctx = get_context() p1 = find_path(pc, 0) if p1 != None: queue.append((p1, get_context())) flow[pc].append(p1) set_context(ctx) p2 = find_path(pc, 1) if p1 != p2: queue.append((p2, get_context())) flow[pc].append(p2) else: p = find_path(pc) if p != None: queue.append((p, get_context())) flow[pc].append(p)def run(offset, end_addr, ret_addr): global end global flow end = end_addr collect_blocks(offset = offset, end = end, ret_addr = ret_addr) init_unicorn("libBlackMamBa.so") start_emu(offset) start_patch(flow, offset)if __name__ == "__main__": offset_list = [0x584c, 0xC90, 0x1700, 0x2968, 0x50A4, 0x42DC] # 0x3CD0 end_list = [0x6b90, 0x16AE, 0x2910, 0x3C76, 0x57BE, 0x4D92] # 0x4280 ret_list = [0x6B58, 0x1666, 0x28E0, 0x3C3C, 0x578E, 0x4D54] # 0x4250 load_file("libBlackMamBa.so") for i in range(len(offset_list)): run(offset_list[i], end_list[i], ret_list[i]) save_file("patch3.so") |
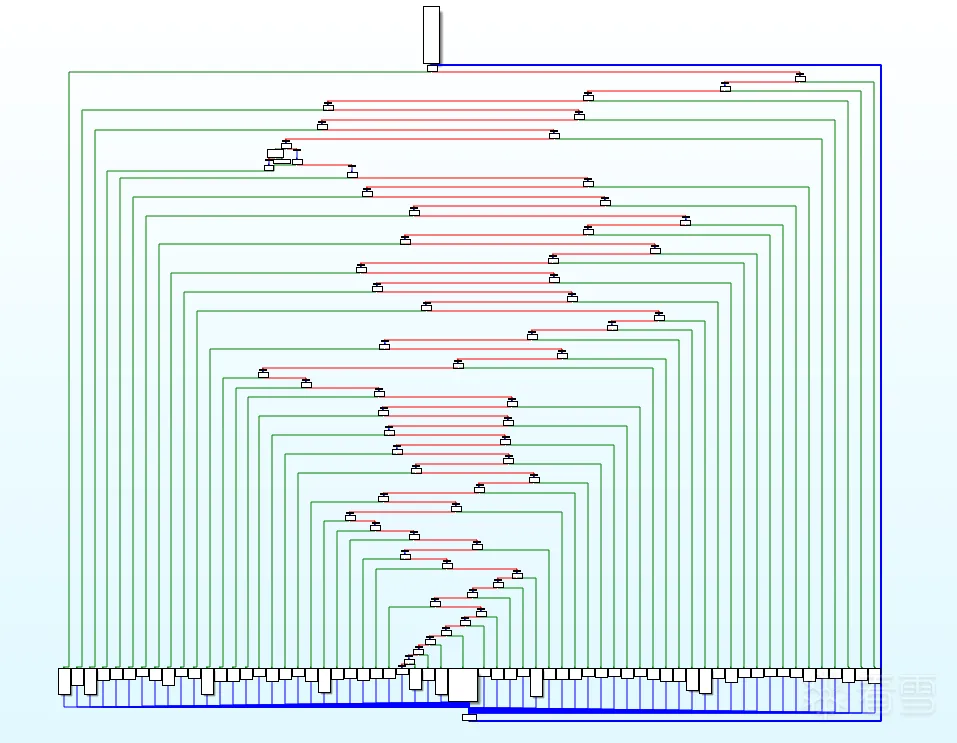
最後附上一張還原的效果圖,以及上述如果有誤的話還望指出!!

參考
更多【Android安全-初窺ARM平坦化還原】相关视频教程:www.yxfzedu.com
相关文章推荐
- Android安全-HoneyBadger系列二 Android App全量监控也来了 - Android安全CTF对抗IOS安全
- Android安全-HoneyBadger系列一 开篇,虚拟机调试器来了 - Android安全CTF对抗IOS安全
- 编程技术-为无源码的DLL增加接口功能 - Android安全CTF对抗IOS安全
- CTF对抗-Realworld CTF 2023 ChatUWU 详解 - Android安全CTF对抗IOS安全
- Android安全-frida源码编译详解 - Android安全CTF对抗IOS安全
- 软件逆向- PE格式:新建节并插入代码 - Android安全CTF对抗IOS安全
- 加壳脱壳- UPX源码学习和简单修改 - Android安全CTF对抗IOS安全
- 二进制漏洞-win越界写漏洞分析 CVE-2020-1054 - Android安全CTF对抗IOS安全
- Pwn-2022长城杯决赛pwn - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——Codemeter服务端 - Android安全CTF对抗IOS安全
- Pwn-沙箱逃逸之google ctf 2019 Monochromatic writeup - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——AxProtector壳初探 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——暴露站点服务(Ingress) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——部署数据库站点(MySql) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——部署web站点环境(PHP+Nginx) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——安装NFS驱动 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——kubeadm安装Kubernetes - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(四) - Android安全CTF对抗IOS安全
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全CTF对抗IOS安全
- 2-wibu软授权(三) - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 学习-【Azure 架构师学习笔记】-Azure Storage Account(5)- Data Lake layers
- 人工智能-高校为什么需要大数据挖掘平台?
- 数码相机-立体相机标定
- java-java计算
- python-前端面试题
- git-IntelliJ IDEA 2023.2.1 (Ultimate Edition) 版本 Git 如何合并多次的本地提交进行 Push
- 音视频-中文编程软件视频推荐,自学编程电脑推荐,中文编程开发语言工具下载
- node.js-npm install:sill idealTree buildDeps
- 编辑器-vscode 访问本地或者远程docker环境
- git-IntelliJ IDEA 2023.2.1 (Ultimate Edition) 版本 Git 如何找回被 Drop Commit 的提交记录