软件逆向-2024年KCTF水泊梁山-WriteUp-反混淆
推荐 原创【软件逆向-2024年KCTF水泊梁山-WriteUp-反混淆】此文章归类为:软件逆向。
2024年KCTF水泊梁山-WriteUp-反混淆
签名:水泊梁山.zZhouQing
日期:2024年8月30日
今天正式成年,开心。想起之前答应坛友 mb_mgodlfyn 说在赛期结束前会提供一份反混淆代码,其实我这俩天一直没关注这个问题,怕他被气到,于是有了本篇随笔,希望各位看的愉快。O(∩_∩)O
首先,这道题内容一般,所以我会结合《加密与解密(第四版)》的内容讲一些基础的东西。帮助没有基础的朋友过渡一下。幸运地是,我也正好忘记掉这道题是如何编写的了。(相信你会学明白的,因为我也是个小菜)
程序内存布局
可以看到,程序是添加混淆了的,有着俩个区段,分别为 obf 和 obf。(其中一个用于存储数据,一个用于执行代码)

混淆
可以看到,程序的混淆与栈相勾连。但是,我们的经验可以告诉我们,这个混淆似乎仅仅只是做了指令变形,而无代码乱序的功能。这对于反混淆来说,是一个非常重要的消息。
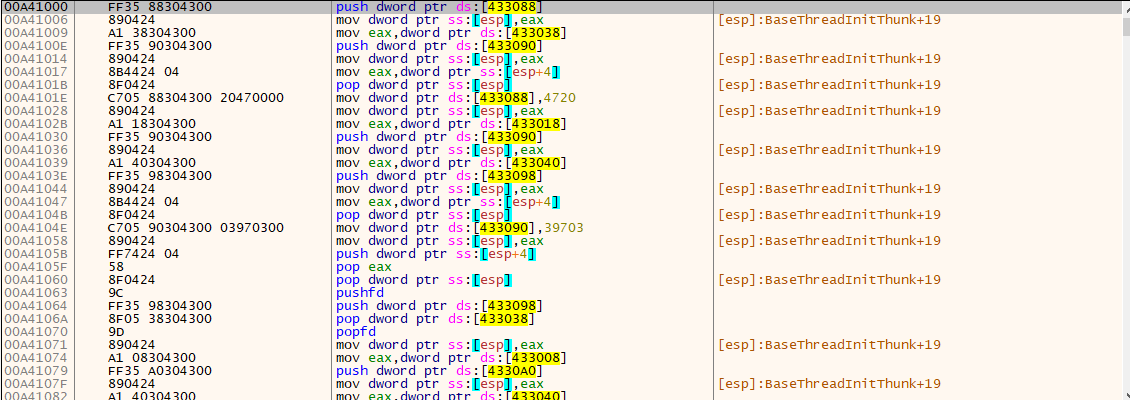
反混淆
我们已经知道了混淆并无代码乱序的功能(代码乱序会使线性扫描算法出现错误),于是,我们对应的反汇编算法既可以是 线性扫描算法,也可以是 递归行进算法。出于方便,这里使用线性扫描算法。
机器码层的特征码匹配
这一技术,应该常见于早期的 花指令 对抗,混淆通过添加基于固定模式生成的花指令达到抵御静态分析的效果,而反混淆(机器码层的特征码匹配)则将混淆中的固定模式转化为字节形式的模板,通过特征匹配,将对应的代码删除,达到反混淆的目的。
; pushf ; jb loc_3 ;loc_1: jmp loc_2 ; _ONE_BYTE_JUNKCODE_ ;loc_2: call loc_4 ; _TWO_BYTE_JUNKCODE_ ;loc_3: jb loc_1 ; _ONE_BYTE_JUNKCODE_ ;loc_4: add esp,4 ; popf ; jmp loc_5 ; _ONE_BYTE_JUNKCODE_ ;loc_5: .... S = 9C720AEB01??E805000000????72F4??83C4049DEB01?? R = 9090909090909090909090909090909090909090909090
在这里,由于技术过于古老,反混淆效果不太好,我仅作一个示例。发现程序具有如下特征,提取特征码,编写脚本进行反混淆。
// asm pushfd push dword ptr ds:[433098] pop dword ptr ds:[433038] popfd // machine 9C FF 35 98 30 43 00 8F 05 38 30 43 00 9D // sig 9C FF 35 ?? ?? ?? ?? 8F 05 ?? ?? ?? ?? 9D // patch 90 90 90 90 90 90 90 90 90 90 90 90 90 90 // script MAX_REF_COUNT 为 5000 所以需要多次运行脚本 findall 00A41000, "9C FF 35 ?? ?? ?? ?? 8F 05 ?? ?? ?? ?? 9D" i = 0 loop: memset ref.addr(i),90,E i++ cmp i, ref.count() jne loop
由于使用的是 memset 命令来去除花指令,而该命令作用后,并不会将修改结果保存到 补丁 当中。所以,这里使用 scylla(x64dbg 配套插件)来保存修改后的程序。
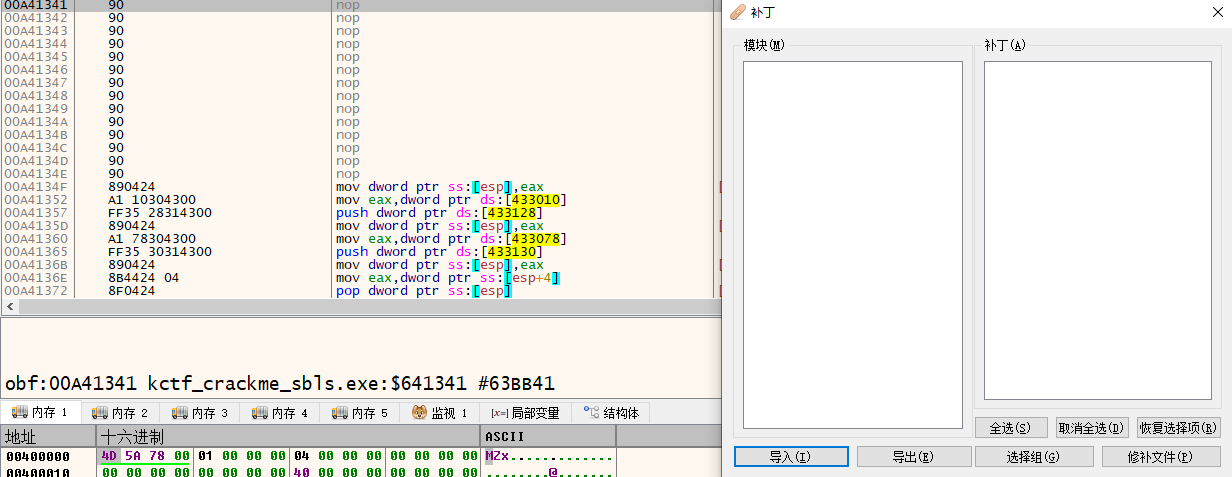
Dbg 将程序停在 EP (EntryPoint)的位置,scylla 依次点击 Dump -> PE Rebuild。
可以看到,经过修改后的程序能够正常运行,同时程序的硬盘占用大大减小。
由于这里仅出于演示目的,我并未考虑将那样特征的汇编删去有何后果,很有可能是不会正常运行的。但,反混淆,就应该多尝试,甚至不需要程序能够正常运行,毕竟时间有限,能将关键代码显现出来即可。
汇编层的特征码匹配
这一技术,常见于早期 VM 对抗的 handle 匹配或是常见密码学的特征匹配。我看到坛友 tacesrever 就是通过这一方式来反混淆的,但是效果不佳。
这里举个例子,我们将这样的特征匹配为 VADD_Q。
mov rax, [rbp+0] add [rbp+8], rax pushfq pop qword ptr [rbp+0] 可以发现,这段程序做了个 add 指令,然后保存了 rflags。 总的来说,它是一个 add 类型的 handle。
当然,这一技术不仅仅是化简程序的流程,还可以用来还原本题的 CF(控制流:control flow)。IDA 打开经过第一次修改的程序 kctf_crackme_sbls_dump.exe。
可以看到,有个立即数 sub_A41F0D,IDA 转过去发现,正是下一个基本块。而 dword_4AA610 与 0Ah 进行异或,值是 0042A9E0 ,IDA 转过去发现,是 _alloca_probe 函数。
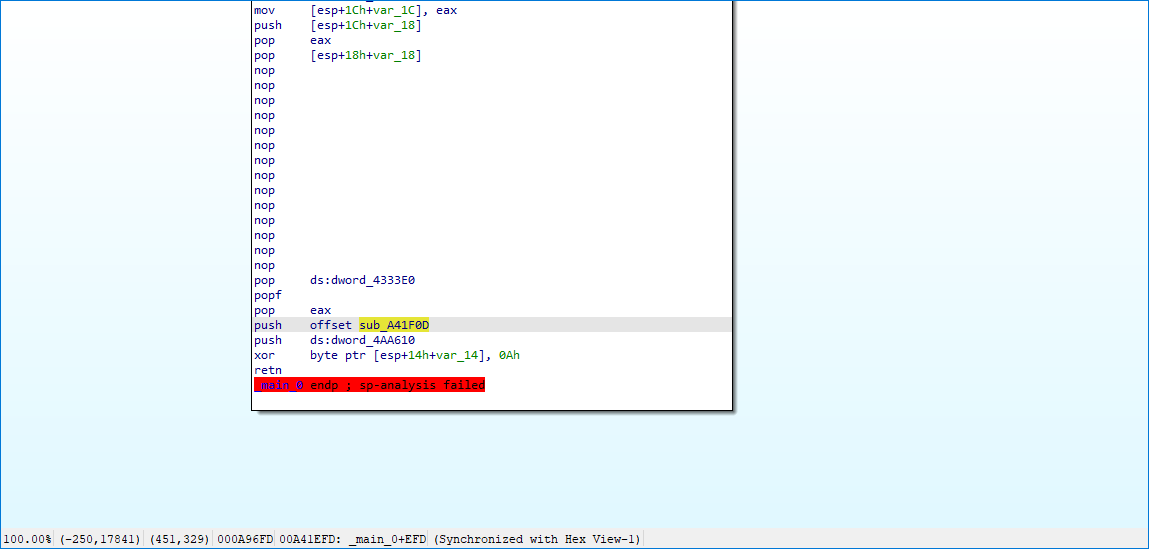
看样子我们可以知道了,混淆对 Call Imm 的指令做了变形,导致 IDA 的控制流分析失败了。利用 python 编写个简单的脚本还原即可。还记得上文提到的 线性扫描算法 吗?就是从一个 base 开始死循环反汇编,脚本自己会异常打印日志的。
from capstone import *
CODE = open(r"f:\新建文件夹\样本\dmp\kctf_crackme_sbls_00A41000.bin", mode='rb').read()
md = Cs(CS_ARCH_X86, CS_MODE_32)
md.detail = True
def MdDisasmLiteOne(md:Cs,eipCode,obfBase):
for v in md.disasm(eipCode, obfBase,1):
return v
def PrintIns(ins:CsInsn):
print("0x%x:\t%s\t%s" %(ins.address, ins.mnemonic, ins.op_str))
return
base = 0x00400000
obfBase = 0x000A41000
eipBlockAddress = obfBase-base
eipCode = CODE[eipBlockAddress:eipBlockAddress+16]
currentBlockList = []
ins = MdDisasmLiteOne(md=md,eipCode=eipCode,obfBase=obfBase)
scriptInsList = []
def ReadDword(addr):
fov = addr - base
v = CODE[fov:fov +4]
v = int.from_bytes(v,"little")
return v
def PrintScriptInsList(scriptInsList:list):
for i in scriptInsList:
print(i + ";")
def PrintScriptInsListOne(scriptInsList:list):
v = ""
for i in scriptInsList:
v += i + ";"
print(v)
def WriteScriptInsList(scriptInsList:list):
fo = open("reverseCFG.txt", "w")
fo.write("")
fo = open("reverseCFG.txt", "a")
for i in scriptInsList:
fo.write(i + "\r\n")
def WriteScriptInsListOne(scriptInsList:list):
fo = open("reverseCFG.txt", "w")
v = ""
for i in scriptInsList:
v += i + ";"
fo.write(v)
try:
while 1:
# PrintIns(ins=ins)
currentBlockList.append(ins)
if ins.mnemonic == "ret":
nextBlockIpIns:CsInsn = currentBlockList[len(currentBlockList) - 4]
if nextBlockIpIns.mnemonic == "push":
nextBlockIp = nextBlockIpIns.operands[0].imm
callImmIns:CsInsn = currentBlockList[len(currentBlockList) - 3]
callImmEnPoint = 0
callImmEn = 0
callImmKey = 0
callImm = 0
if callImmIns.mnemonic == "push":
callImmEnPoint = callImmIns.operands[0].mem.disp
callImmEn = ReadDword(callImmEnPoint)
callImmKeyIns:CsInsn = currentBlockList[len(currentBlockList) - 2]
if callImmKeyIns.mnemonic == "xor":
callImmKey = callImmKeyIns.operands[1].imm
callImm = callImmEn ^ callImmKey
# print(hex(callImm))
# print(hex(nextBlockIp))
# scriptInsList.append("asm {},nop,1".format(hex(callImmIns.address)))
scriptInsList.append("asm {},nop,1".format(hex(callImmKeyIns.address)))
scriptInsList.append("asm {},nop,1".format(hex(ins.address)))
scriptInsList.append("asm {},\"call {}\",1".format(hex(nextBlockIpIns.address),hex(callImm)))
scriptInsList.append("asm {},\"jmp {}\",1".format(hex(callImmIns.address),hex(nextBlockIp)))
nextfov = nextBlockIp-base
eipCode = CODE[nextfov:nextfov+16]
ins = MdDisasmLiteOne(md=md,eipCode=eipCode,obfBase=nextBlockIp)
# PrintIns(ins=ins)
continue
nextip = ins.address+ins.size
nextfov = nextip-base
eipCode = CODE[nextfov:nextfov+16]
ins = MdDisasmLiteOne(md=md,eipCode=eipCode,obfBase=nextip)
except:
WriteScriptInsList(scriptInsList)
print("over") 由于生成的去混淆脚本内容较长,这里不贴出了。

这一个脚本还不足以还原完整的 CF ,因为 Call 指令分为四种类型。(这里并未使用 intel 指令语法)
- call imm
- call [mem]
- call reg
- call [reg+offset]
提取三次汇编特征,编写三个脚本就能还原,有了第一次的经验,复制粘贴一下就行了。经过三次修复,IDA 已经能够正常显示 CFG 了。
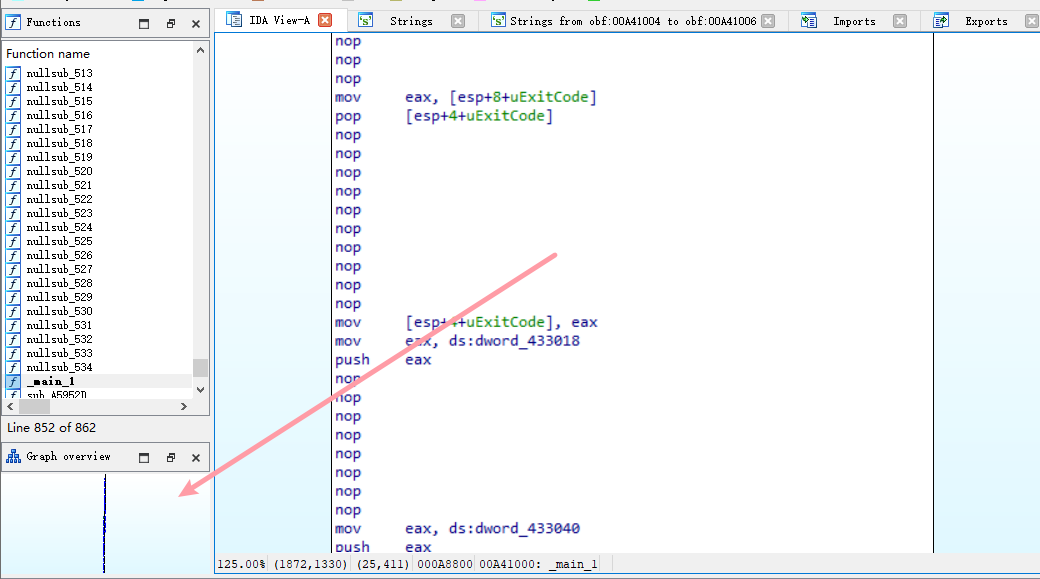
本想写到这里便停下的,不过,看到 tacesrever 通过汇编匹配来还原原始的汇编指令,我也写个脚本来做个简单的化简好了。IDA 将程序 main 函数反编译后,可以发现这样形式的全局变量。这个全局变量有俩次读,一次写的操作。
r sub_xxx+offset push ds:dword_43CC68 r sub_xxx+offset push ds:dword_43CC68 w sub_xxx+offset mov ds:dword_43CC68,4BFD4h
而读操作却是这样的,这样的汇编指令可以直接化简为 push eax。看样子。这样的全局变量可以直接删除了。
push ds:dword_4AA100 mov [esp], eax
又浏览了几个全局变量,发现还有这样形式的,这样的全局变量似乎是参与运算了,保留即可。
编写脚本,做第六次反混淆操作,依旧是套用第二次的模板。(第一次为机器码匹配)
from capstone import *
CODE = open(r"f:\新建文件夹\样本\dmp\kctf_crackme_sbls_00A41000.bin", mode='rb').read()
md = Cs(CS_ARCH_X86, CS_MODE_32)
md.detail = True
def MdDisasmLiteOne(md:Cs,eipCode,obfBase):
for v in md.disasm(eipCode, obfBase,1):
return v
def PrintIns(ins:CsInsn):
print("0x%x:\t%s\t%s" %(ins.address, ins.mnemonic, ins.op_str))
return
def GetInsStr(ins:CsInsn):
return "%s %s" %(ins.mnemonic, ins.op_str)
base = 0x00400000
obfBase = 0x000A41000
eipBlockAddress = obfBase-base
eipCode = CODE[eipBlockAddress:eipBlockAddress+16]
currentBlockList = []
ins = MdDisasmLiteOne(md=md,eipCode=eipCode,obfBase=obfBase)
scriptInsList = []
def ReadDword(addr):
fov = addr - base
v = CODE[fov:fov +4]
v = int.from_bytes(v,"little")
return v
def PrintScriptInsList(scriptInsList:list):
for i in scriptInsList:
print(i + ";")
def PrintScriptInsListOne(scriptInsList:list):
v = ""
for i in scriptInsList:
v += i + ";"
print(v)
def WriteScriptInsList(scriptInsList:list):
fo = open("reverseCFG_6.txt", "w")
fo.write("")
fo = open("reverseCFG_6.txt", "a")
for i in scriptInsList:
fo.write(i + "\r\n")
def WriteScriptInsListOne(scriptInsList:list):
fo = open("reverseCFG_6.txt", "w")
v = ""
for i in scriptInsList:
v += i + ";"
fo.write(v)
GlobalVariantTable = {}
def GetInsFromInsOffset(ins:CsInsn,offset):
if offset < 0:
return None
else:
for i in range(0,offset):
nextip = ins.address + ins.size
nextfov = nextip-base
eipCode = CODE[nextfov:nextfov+16]
ins = MdDisasmLiteOne(md=md,eipCode=eipCode,obfBase=nextip)
return ins
# push dword ptr ds:[0x00433088]
def FindGlobalVariantIsInvail(baseIns:CsInsn):
globalVariantAddress = baseIns.operands[0].mem.disp
globalVariantIsInvail = True
ins = baseIns
point = 0
itba = []
sil = []
while point < 200:
basePoint = point
# str = GetInsStr(ins=ins)
if ins.mnemonic == "push":
if ins.operands[0].mem.disp == globalVariantAddress:
# PrintIns(ins=ins)
itba.append(ins)
point +=1
if ins.mnemonic == "mov":
if ins.operands[0].mem.disp == globalVariantAddress:
# PrintIns(ins=ins)
itba.append(ins)
if ins.mnemonic == "pop":
if ins.operands[0].mem.disp == globalVariantAddress:
# PrintIns(ins=ins)
itba.append(ins)
ins = GetInsFromInsOffset(ins,point - basePoint + 1)
opsize = len(ins.operands)
if opsize > 1:
if ins.operands[1].mem.disp == disp:
PrintIns(ins=ins)
globalVariantIsInvail = False
point += 1
for ins in itba:
ins:CsInsn = ins
if ins.mnemonic == "push":
dins = GetInsFromInsOffset(ins,1)
if GetInsStr(dins) == "mov dword ptr [esp], eax":
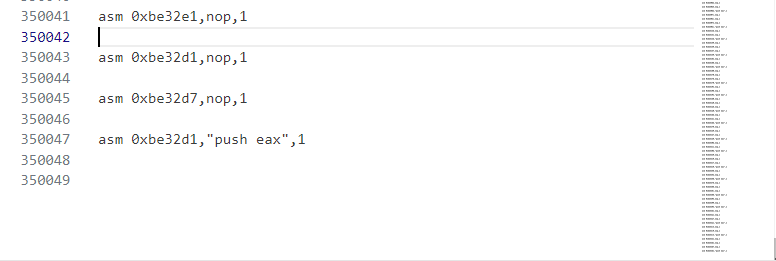
sil.append("asm {},nop,1".format(hex(ins.address)))
sil.append("asm {},nop,1".format(hex(ins.address+6)))
sil.append("asm {},\"push eax\",1".format(hex(ins.address)))
if globalVariantIsInvail == True:
if ins.mnemonic == "mov":
sil.append("asm {},nop,1".format(hex(ins.address)))
if ins.mnemonic == "pop":
sil.append("asm {},nop,1".format(hex(ins.address)))
return sil
try:
while 1:
# PrintIns(ins=ins)
currentBlockList.append(ins)
if ins.mnemonic == "push":
disp = ins.operands[0].mem.disp
if disp>=0x0433000 and disp<=obfBase:
PrintIns(ins=ins)
if (disp in GlobalVariantTable) == False:
GlobalVariantTable[disp] = FindGlobalVariantIsInvail(ins)
if GlobalVariantTable[disp] != []:
for i in GlobalVariantTable[disp]:
scriptInsList.append(i)
ins = GetInsFromInsOffset(ins,1)
continue
nextip = ins.address+ins.size
nextfov = nextip-base
eipCode = CODE[nextfov:nextfov+16]
ins = MdDisasmLiteOne(md=md,eipCode=eipCode,obfBase=nextip)
except:
WriteScriptInsList(scriptInsList)
print("over 6") 这次生成的反混淆脚本巨大,X64Dbg 的补丁窗口会卡死,所以通过 scylla 这一插件进行保存修改。
测试下修改结果,发现程序正常执行,继续玩下去。
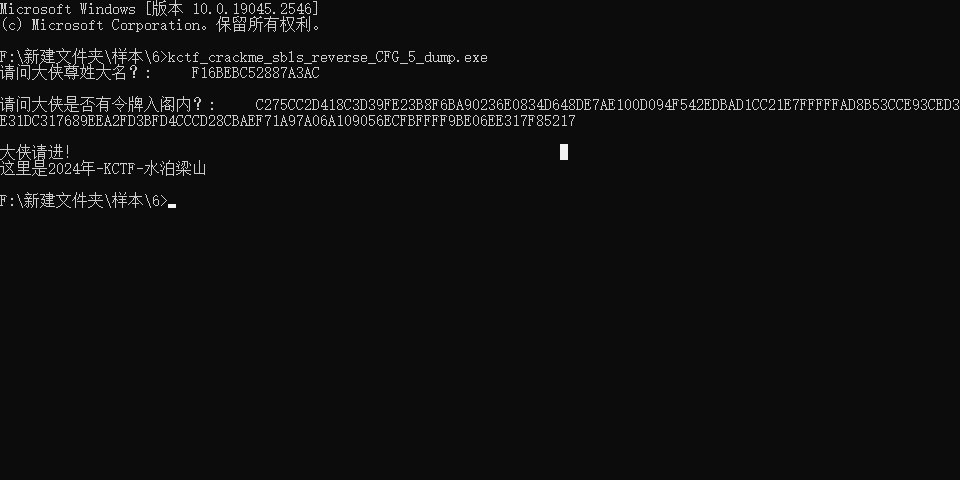
AST 层的混淆去除
IDAPython 提供了操作 AST 的接口,这里的 AST 对应结构为 ctree,可以在 idapython_docs 当中查看相关信息。
ctree 中的节点称为 citem_t,而 citem_t 这一抽象结构可以具体分化为 cinsn_t 与 cexpr_t。(cinsn_t 的结构中包含 cexpr 结构)
同时,IDAPython 提供了 ctree_visitor_t 类,通过继承该类,重写特定函数(visit_insn 与 visit_expr)达到对 ctree 的 curd 操作。
接下来做几个基本的演示。
剔除 __readeflags 和 __writeeflags 相关指令
通过观察反编译结果,发现如下特征代码。这些代码对于我们分析程序来说,是没有用处的,毕竟谁会去在意 eflags 呢?
v8 = __readeflags(); // pushfd __writeeflags(v8); // popfd
我们使用 HRDevHelper 提取对应表达式的结构,这个结构用于判断是否是垃圾代码。
// __readeflags (i.op is idaapi.cit_expr and i.cexpr.op is idaapi.cot_asg and i.cexpr.x.op is idaapi.cot_var and i.cexpr.y.op is idaapi.cot_call and i.cexpr.y.x.op is idaapi.cot_helper) (i.op is idaapi.cit_expr and i.cexpr.op is idaapi.cot_asg and i.cexpr.x.op is idaapi.cot_var and i.cexpr.y.op is idaapi.cot_cast and i.cexpr.y.x.op is idaapi.cot_call and i.cexpr.y.x.x.op is idaapi.cot_helper) // __writeeflags (i.op is idaapi.cit_expr and i.cexpr.op is idaapi.cot_call and i.cexpr.x.op is idaapi.cot_helper and i.cexpr.a[0].op is idaapi.cot_var) // __writeeflags (i.op is idaapi.cit_expr and i.cexpr.op is idaapi.cot_call and i.cexpr.x.op is idaapi.cot_helper and i.cexpr.a[0].op is idaapi.cot_var)
编写如下代码,即可去除 ctree 中特定类型的指令。
import idaapi
import idc
import ida_bytes
import ida_hexrays
class JunkCodeVister(idaapi.ctree_visitor_t):
def __init__(self, cfunc):
global itlist
idaapi.ctree_visitor_t.__init__(self, idaapi.CV_PARENTS)
itlist = []
s = cfunc.body
s.swap(cfunc.body)
self.cfunc = cfunc
self.del_point = 0
def isjunk(self,ins) -> "int":
i = ins
if (i.op is idaapi.cit_expr and
i.cexpr.op is idaapi.cot_asg and
i.cexpr.x.op is idaapi.cot_var and
i.cexpr.y.op is idaapi.cot_call and
i.cexpr.y.x.op is idaapi.cot_helper):
return True
if (i.op is idaapi.cit_expr and
i.cexpr.op is idaapi.cot_call and
i.cexpr.x.op is idaapi.cot_helper and
i.cexpr.a[0].op is idaapi.cot_var):
return True
if (i.op is idaapi.cit_expr and
i.cexpr.op is idaapi.cot_call and
i.cexpr.x.op is idaapi.cot_helper and
i.cexpr.a[0].op is idaapi.cot_cast and
i.cexpr.a[0].x.op is idaapi.cot_var):
return True
return False
def visit_insn(self, ins: idaapi.cinsn_t) -> "int":
self.del_point +=1
if ins.op == idaapi.cit_if and self.del_point !=1:
my_visitor = JunkCodeVister(self.cfunc)
my_visitor.apply_to(ins, ins)
self.prune_now()
return 0
if not ins.cexpr:
return 0
f = self.isjunk(ins)
if f == True:
pd = self.parent_insn().details
dit = self.parent_insn().details.find(ins)
pd.erase(dit)
pass
return 0
class DelJunkCodeVister(idaapi.ctree_visitor_t):
def __init__(self, cfunc):
idaapi.ctree_visitor_t.__init__(self, idaapi.CV_FAST)
self.cfunc = cfunc
return
def main():
func = idaapi.get_func(idc.here())
cfunc = idaapi.decompile(func.start_ea)
my_visitor = JunkCodeVister(cfunc)
my_visitor.apply_to(cfunc.body, None)
print("deover")
if __name__ == '__main__':
main()IDA 执行脚本后,发现如下报错,这是没有及时更新函数内容导致的。
解决方案:修改下函数名,让 IDA 更新函数内容。
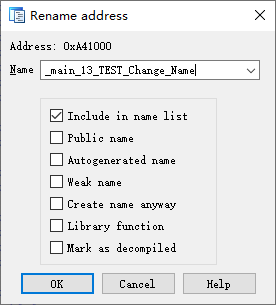
可以看到,IDA 中的反汇编结果已经没有了那串垃圾代码。
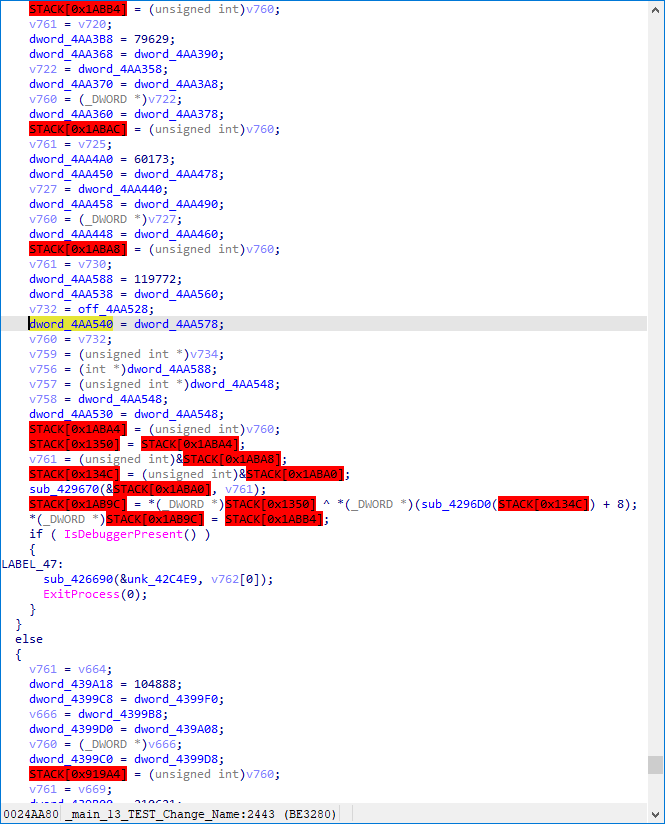
极端化的反混淆
在上图当中,我们发现,有太多全局变量的操作了,影响我们分析,干脆将 表达式中第一个操作数为全局变量 的指令全部删掉。它们的值无需关心,因为在这样情况下的静态分析,你已无法清晰地知道程序的动态结果。(若要用,跑个 Trace 补上就好)
在 isjunk 函数中添加如下逻辑即可:
if (i.op is idaapi.cit_expr andi.cexpr.op is idaapi.cot_asg andi.cexpr.x.op is idaapi.cot_obj): return True
运行脚本,并手动更新下函数。怎样,程序逻辑是不是一下子就明晰了?
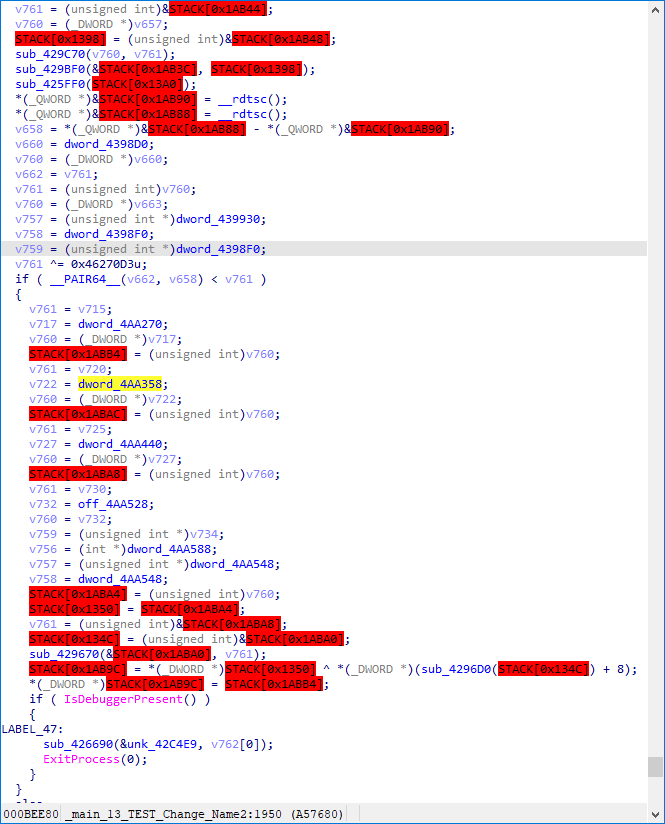
我印象里我的程序里并未定义啥全局变量,所以没有判断全局变量的地址是否在混淆范围内。(应该是有定义的,我想说些闲话)
至此,我们可以开始愉快地做题啦,考虑到实际做题时间的问题,懒得继续优化下去了。(从反混淆的第一步到现在的第八步,不会花多长时间的,预计不超过三小时)
做题
快速定位程序算法验证函数
Dbg 创建程序运行起来,输入如下内容(不要着急按下回车开始验证身份)。
请问大侠尊姓大名?: 梁山.zZhouQing 请问大侠是否有令牌入阁内?: 他时若遂凌云志,敢笑黄巢不丈夫。
Dbg 转到内存窗口,给最后一个段下 内存执行 断点。

程序断在这个位置,IDA 转过去。
00A6261C | jmp kctf_crackme_sbls_reverse_cfg_5_dump.A6262 |
发现程序最后调用了 sub_A6322D 函数,这个函数内容有点大,如出现 function is too big 的问题,请查阅附录中的 IDA问题解决->function is too big。
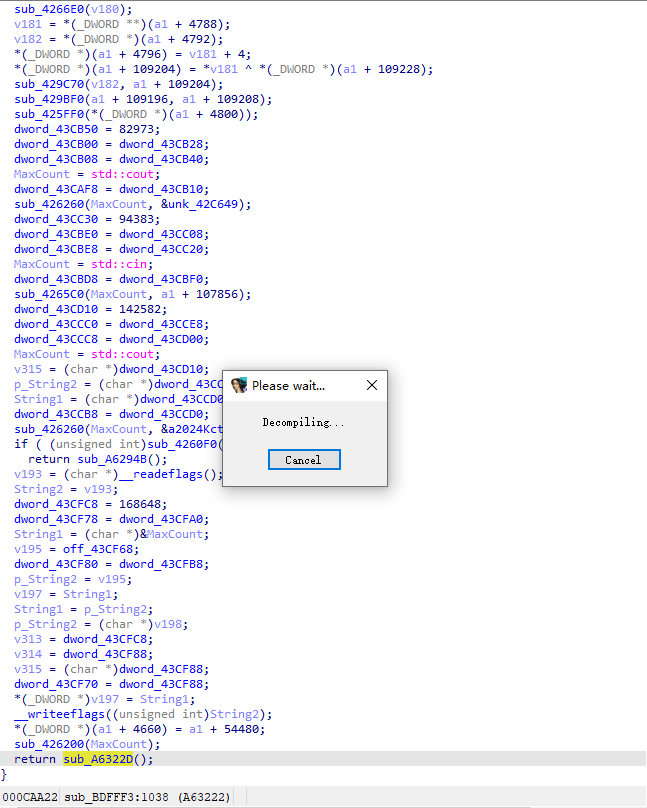
通过扫 std::cout 引用定位 CheckFlag
在我观察 main 函数的时候,发现程序调用了 std::cout,扫下它的引用看看。
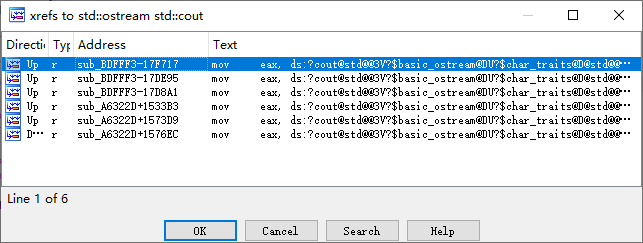
发下这段代码很可疑,X64Dbg 转过去看看,注意下 &unk_42C4DE 是什么。
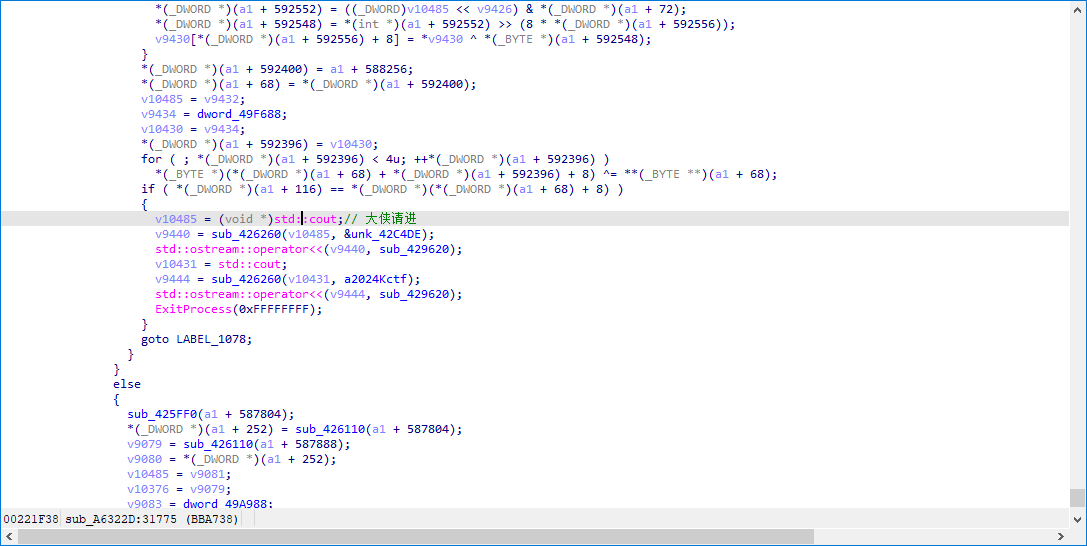
哈,看样子我们很幸运,这下子我们知道程序是如何判断 flag 的了。
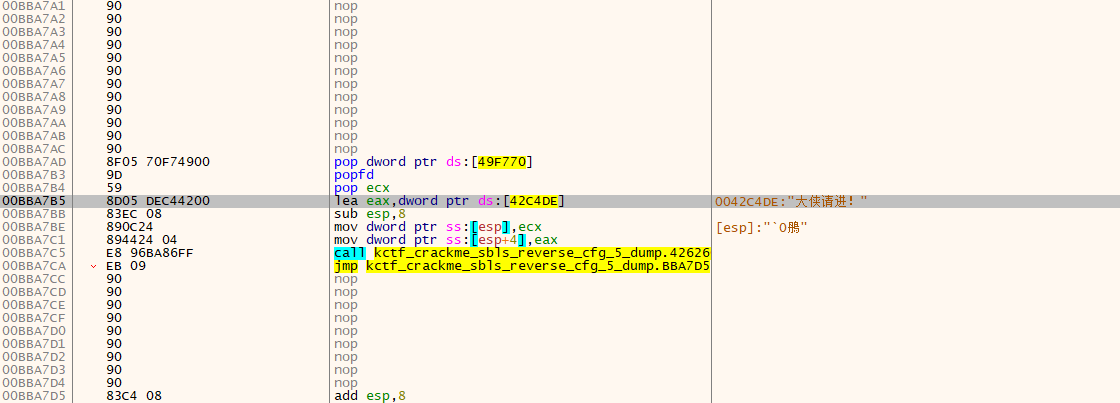
通过 flag 回溯
由于 IDA 并未将 *(_DWORD *)(a1 + 116) 与 *(_DWORD *)(*(_DWORD *)(a1 + 68) + 8) 识别为变量,故采取复制内容到 VsCode 进行分析的方案。Ctrl+F 搜索 *(_DWORD *)(a1 + 116) 发现其有俩个引用,好消息,这意味着 *(_DWORD *)(*(_DWORD *)(a1 + 68) + 8) 很有可能为 const_flag。(经过搜索,发现其的确只引用了一次)
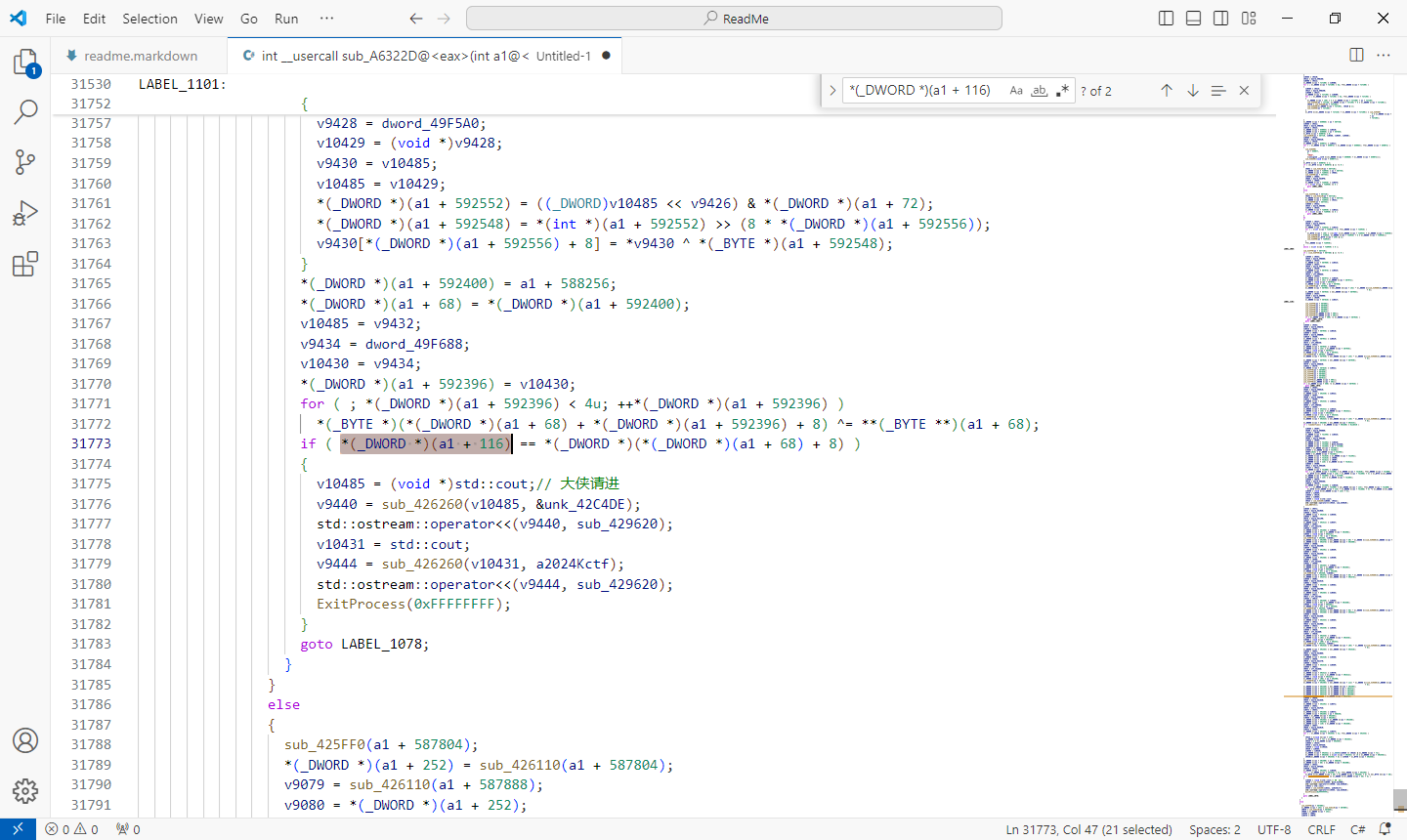
寻找将这条语句包裹起来的代码块,即寻找 if 语句。
*(_DWORD *)(a1 + 116) = *(_DWORD *)(a1 + 592376);
垃圾代码
途中发现这样的垃圾代码,编写脚本删掉这个 citem_t 即可。
if ( timeGetTime() - *(_DWORD *)(a1 + 592380) > 0x1D4C0 ){
v10485 = v9397;
v9399 = dword_49E0D0;
v10425 = v9399;
*(_DWORD *)(a1 + 731596) = v10425;
v10485 = v9402;
v9404 = dword_49E1B8;
....
} 发现其被包裹在这样的语句中,在这些代码中寻找我们的 特殊性,这是我们思考问题的方法。这 PAIR64 函数未免太特殊了,得多注意。
if ( __PAIR64__((unsigned int)v9746, v9742) >= (unsigned int)v10506 )
{
*(_BYTE *)(a1 + 649976) = 1;
if ( (*(_BYTE *)(a1 + 649976) & 1) != 0 )
{
*(_BYTE *)(a1 + 649235) = 1;
if ( (*(_BYTE *)(a1 + 649235) & 1) == 0 )
{
if ( (*(_BYTE *)(a1 + 650096) & 1) != 0 )
{
if ( *(_DWORD *)(a1 + 726908) < *(_DWORD *)(a1 + 726920) )
{
....
*(_DWORD *)(a1 + 116) = *(_DWORD *)(a1 + 592376);
....
}
}
}
}
}bit 操作特征码
看到 256 操作,我立马猜测其是 bit 相关操作。
for ( ; *(int *)(a1 + 649860) < 256; ++*(_DWORD *)(a1 + 649860) )
{
*(_DWORD *)(a1 + 649856) = *(_DWORD *)(a1 + 649860);
v10506 = v8724;
v8726 = (void *)dword_496F28;
v10505 = v8726;
v10504 = (void *)v8728;
v10501 = (int *)dword_496F88;
v10502 = (int *)dword_496F48;
v10503 = dword_496F48;
*(_DWORD *)(a1 + 649852) = v10505;
for ( ; *(int *)(a1 + 649852) > 0; --*(_DWORD *)(a1 + 649852) )
{
if ( (*(_DWORD *)(a1 + 649856) & 1) != 0 )
*(_DWORD *)(a1 + 649856) = (*(int *)(a1 + 649856) >> 1) ^ 0x520;
else
*(int *)(a1 + 649856) >>= 1;
}
dword_42F0C4[*(_DWORD *)(a1 + 649860)] = *(_DWORD *)(a1 + 649856);
}暗装代码
继续回溯,发现其被包裹在 else 块里,通过另一个基本块内容,猜测其可能是程序的暗装。
if(timeGetTime() - *(_DWORD *)(a1 + 370880) <= *(_DWORD *)(a1 + 370884) ){
...
fakecode
...
}else{
...
flagcode
...
}RC6
继续回溯,发现如下代码特征,由于我学过相关算法,所以断定它是 RC6 算法。类似代码重复了俩次,看样子是进行了俩次的 RC6 解密。
*(_DWORD *)(a1 + 701100) -= 4; *(_DWORD *)(a1 + 701112) = *(_DWORD *)(a1 + 701116); *(_DWORD *)(a1 + 701116) = *(_DWORD *)(a1 + 701120); *(_DWORD *)(a1 + 701120) = *(_DWORD *)(a1 + 701124); *(_DWORD *)(a1 + 701124) = *(_DWORD *)(a1 + 701128); *(_DWORD *)(a1 + 701128) = *(_DWORD *)(a1 + 701112); ++*(_DWORD *)(a1 + 701104); } while ( *(_DWORD *)(a1 + 701104) < 5u );LABEL_837: *(_DWORD *)(a1 + 701116) -= **(_DWORD **)(a1 + 701100); *(_DWORD *)(a1 + 701100) -= 4; *(_DWORD *)(a1 + 701124) -= **(_DWORD **)(a1 + 701100); *(_DWORD *)(a1 + 701100) -= 4;
经典的查表换位
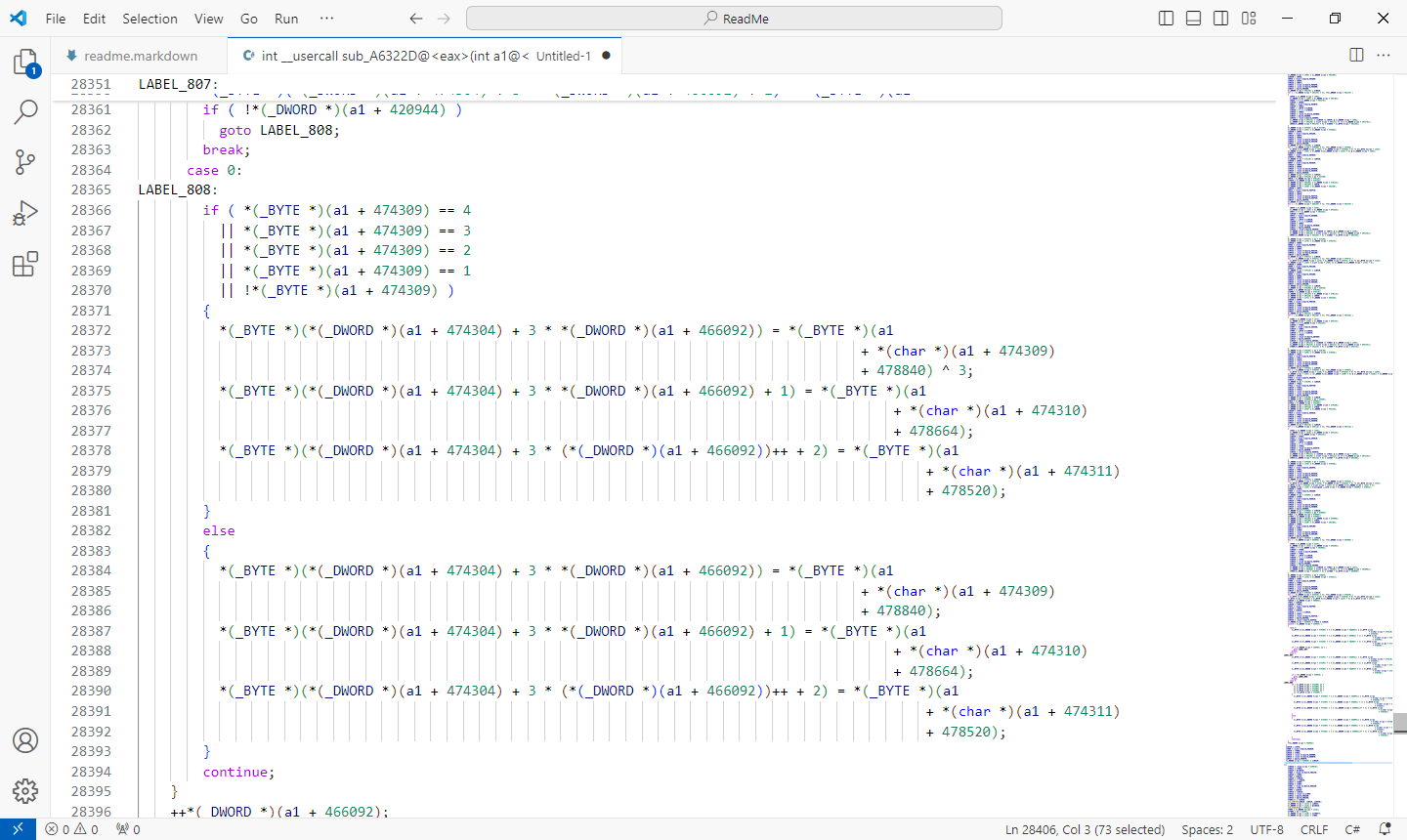
下方有这样的代码,24 可能是个字符串长度。
for ( ; *(_DWORD *)(a1 + 420940) != 24; ++*(_DWORD *)(a1 + 420940) ){
...
rc6
flagcode
...
}小结
总之,这个程序就是这样玩的,如果我再回溯下去,本篇随笔内容就太复杂了。
逆向的小技巧
在调试的过程中,题目自行生成的数据一般是不用逆向的,直接拿过来用即可。
其次,RC6 与 DES 的加密与解密代码极其相似,可以通过修改汇编和参数做逆运算达到相反功能。
总结
题目在本质上具有普遍的一般性,算法验证流程也是偏向基础。相信对于各位学习混淆的对抗,它会是一个不错的样本。混淆什么的,没什么怕的。遇到新情况要多于尝试。
附录
代码乱序
可以看到,Dbg 已经无法正常的反汇编程序,因为其使用的反汇编算法是线性扫描算法。(Linear Sweep)
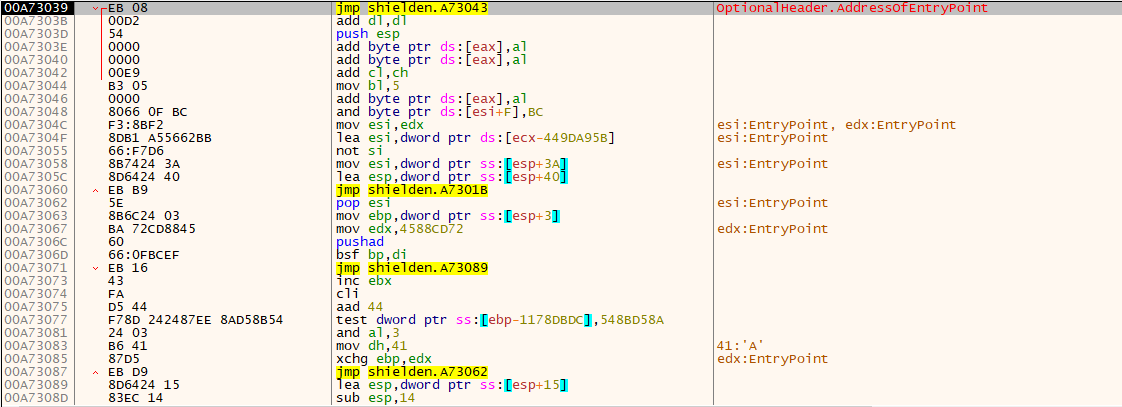
但若是在 Dbg 反汇编窗口按下 G 键,使用的则是递归行进算法。(Recursive Traversal)此时的反汇编结果是正常的。(OllyDbg 在分析代码功能(“Ctrl+A”组合键)时使用递归行进算法)
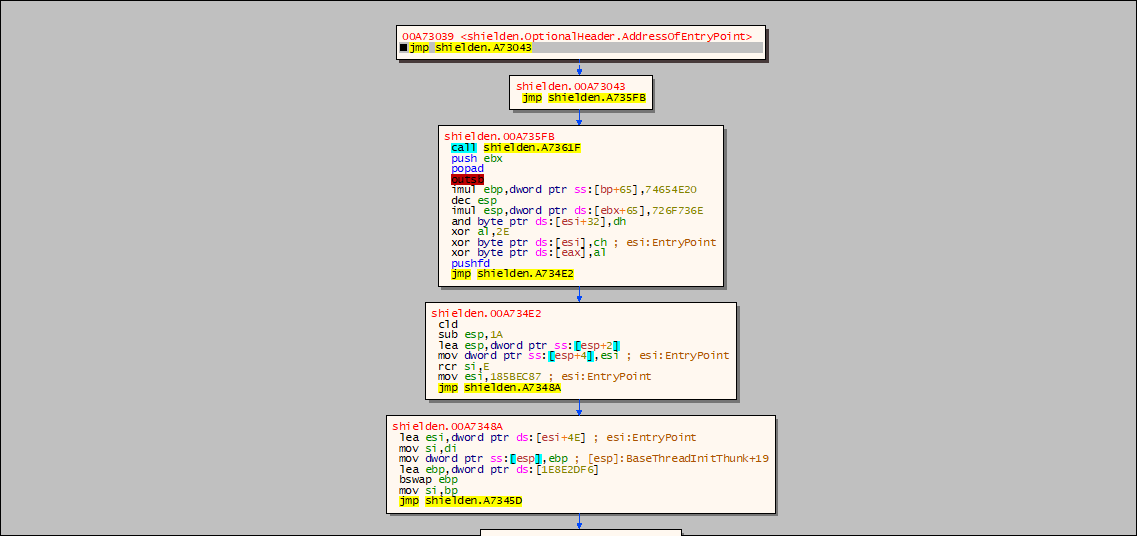
花指令
示例程序为 《加密与解密(第四版)》的随书文件。(Chap17->17.2 抵御静态分析->17.2.1 花指令-> example1.exe)
可以看到,程序构造了恒成立的跳转,并在跳转的空隙中填入无效字节,导致 Dbg 无法正常反汇编。
采用特征码匹配的方式,删除无效字节即可解决反汇编问题。

Dejunk(花指令清除工具)
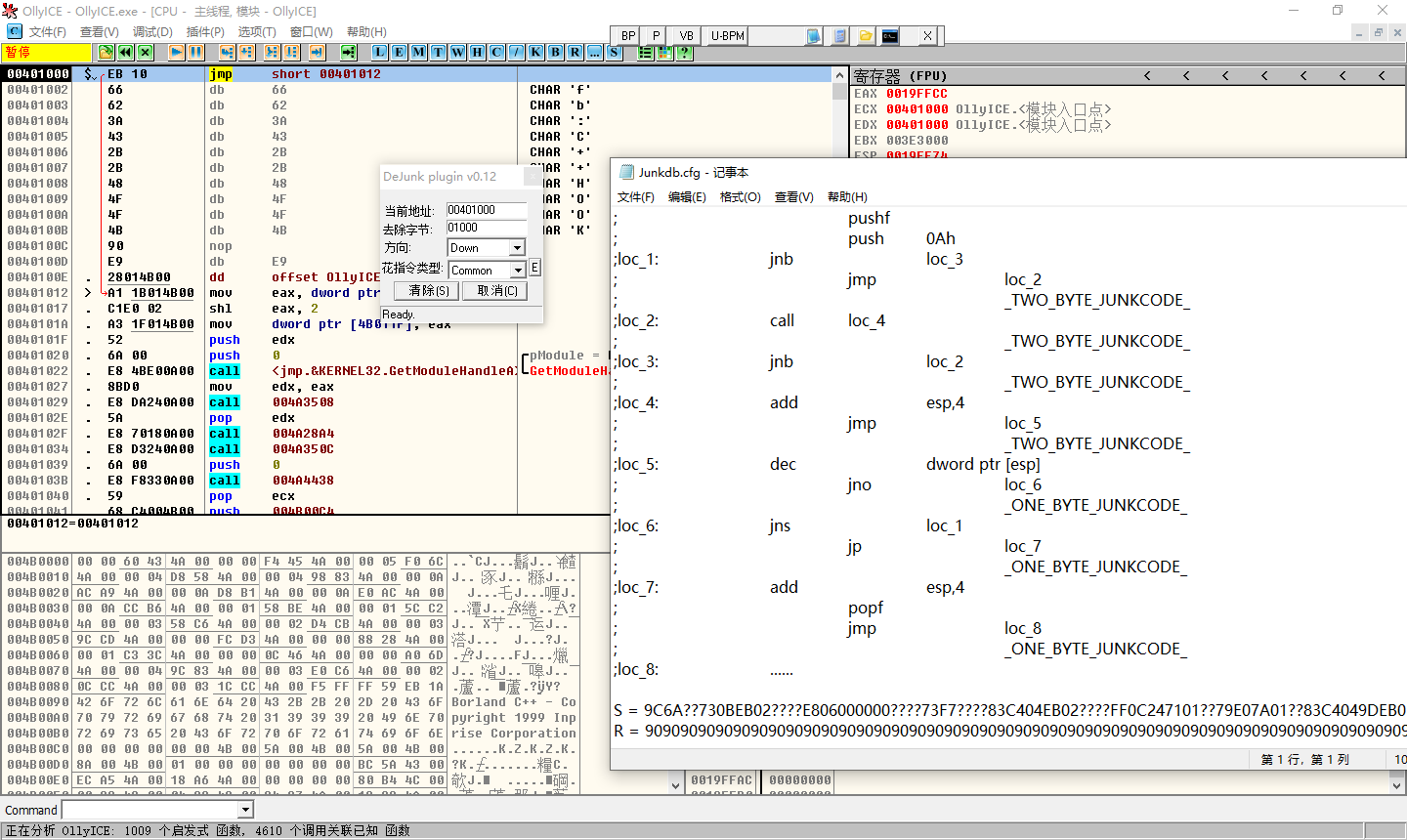
花指令去除器
Python Capstone 的安装
Command 窗口执行 pip install qiling 命令即可安装,一应俱全。
HRDevHelper
HRDevHelper 是用 IDAPython 编写的 Hexrays 反编译器扩展,旨在成为调试和开发自己的 Hexrays 插件和脚本的有用工具。该插件通过显示反编译函数各自的 ctree 图形,并在其底层反编译代码和图形的各个项目之间创建可视化链接来发挥其作用。
对于 IDAPython 操作 ctree 来说,它是一个很好的辅助开发工具。
IDA 问题解决
STACK[count]
修改函数属性,修改 Local variables area 的值,我喜欢填 0x1000。(因为是 4096,hiahia,正好一页大小)如果反编译结果仍然出现 STACK[count],那就写个脚本改个别名。
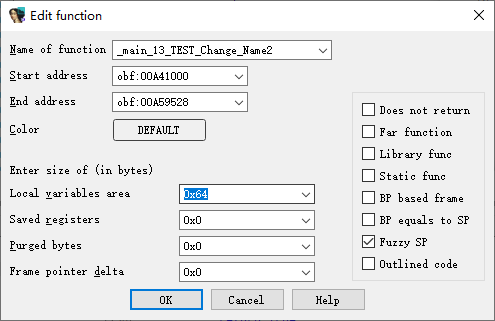
function is too big
配置文件路径为:IDA\cfg\hexrays.cfg
MAX_FUNCSIZE = 64 // Functions over 64K are not decompiled MAX_FUNCSIZE = 4096 // Functions over 64K are not decompiled
基于栈平衡的数据流匹配
反混淆部分其实到 AST 层就结束了,下面俩个实验我只是随便做的,相对于上面三个反混淆方式,它们在这道题当中并不实用。
由于今天过生日,拉了项目到硬盘里,结果 C 盘突然红了,索性重装了电脑。相应的代码文件也丢了。(哈,我喜欢把随手写的项目放 C 盘下)
举个例子(将下面代码转换为数据流的形式):
push eax mov eax,dword ptr ds:[433038] push eax mov eax,dword ptr ss:[esp+4] pop dword ptr ss:[esp] pop eax
由于有 push 和 pop 指令的存在,所以数据流分析需要考虑到栈。定义 stack_point_offset 为 0。每条指令都记录修改前与修改后的 stack_point_offset,记得当时写的脚本所分析的数据流是这样子的。
将上面的汇编指令转换为数据流是这样的。
stack_point_offset = 0 [esp-4] = eax; //stack_point_offset = -4 eax = [433038]; //stack_point_offset = -4 [esp-4] = eax; //stack_point_offset = -8 eax = [esp + 4]; //stack_point_offset = -8 [esp+4] = [esp]; //stack_point_offset = -4 eax = [esp-4]; //stack_point_offset = 0
不难发现,它是做了个这样的操作。由于 intel 指令集中并未包含这样形式的指令,只好作罢。(就算有也懒得写,哈哈)
xchg [esp],[433038]
LLIL 层的反混淆
binary ninja 这一反编译器给用户提供了操作 IL 的接口,但是我在测试时发现关于 pop dword ptr ss:[esp] 这一指令的解析是错误的。(数据的传递出现错误,虽然不影响基于 SSA 理论的编译优化,但看着碍眼)不过我的电脑太老旧了,在此已经无法继续细说。
LLIL 与 ASM 类似,若要通过它来反混淆,会比较累。不过 bn 提供了多种类型的 IL ,相信在实际运用当中,会比最基本的 汇编代码匹配 方便许多,这是 基于汇编代码匹配 的一种平替方向。
参考资料
Dejunk 与 花指令去除器(Ollydbg plugin)
[原创] 看雪·2024 KCTF 大赛 第三题 绝境逢生 WriteUP
igors-tip-of-the-week-147-fixing-stack-frame-is-too-big
IDAPro F5出现too big function 解决
[原创] 使用BinaryNinja去除libtprt.so的混淆 (一)
更多【软件逆向-2024年KCTF水泊梁山-WriteUp-反混淆】相关视频教程:www.yxfzedu.com
相关文章推荐
- 二进制漏洞-通用shellcode开发原理与实践 - PwnHarmonyOSWeb安全软件逆向
- Android安全-frida-server运行报错问题的解决 - PwnHarmonyOSWeb安全软件逆向
- Android安全-记一次中联X科的试岗实战项目 - PwnHarmonyOSWeb安全软件逆向
- Android安全-对SM-P200平板的root记录 - PwnHarmonyOSWeb安全软件逆向
- Android安全-某艺TV版 apk 破解去广告及源码分析 - PwnHarmonyOSWeb安全软件逆向
- Pwn-Hack-A-Sat 4 Qualifiers pwn部分wp - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞- AFL 源代码速通笔记 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-Netatalk CVE-2018-1160 复现及漏洞利用思路 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-DynamoRIO源码分析(一)--劫持进程 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-通用shellcode开发原理与实践 - PwnHarmonyOSWeb安全软件逆向
- Android安全-frida-server运行报错问题的解决 - PwnHarmonyOSWeb安全软件逆向
- Android安全-记一次中联X科的试岗实战项目 - PwnHarmonyOSWeb安全软件逆向
- Android安全-对SM-P200平板的root记录 - PwnHarmonyOSWeb安全软件逆向
- 编程技术- 从应用层到MCU,看Windows处理键盘输入 [1.在应用层调试Notepad.exe (按键消费者)] - PwnHarmonyOSWeb安全软件逆向
- 软件逆向- MFC逆向之CrackMe Level3 过反调试 + 写注册机(一) - PwnHarmonyOSWeb安全软件逆向
- Android安全-frida-qbdi-tracer - PwnHarmonyOSWeb安全软件逆向
- 编程技术-Python源码解析-import过程 - PwnHarmonyOSWeb安全软件逆向
- Pwn-[writeup]CTFHUB-LargeBin Attack|House of Storm - PwnHarmonyOSWeb安全软件逆向
- 软件逆向-与AI沟通学习恶意软件分析技术V1.0 - PwnHarmonyOSWeb安全软件逆向
- Pwn-一条新的glibc IO_FILE利用链:__printf_buffer_as_file_overflow利用分析 - PwnHarmonyOSWeb安全软件逆向
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com