CTF对抗-HKCERT CTF 部分Re题解
推荐 原创【CTF对抗-HKCERT CTF 部分Re题解】此文章归类为:CTF对抗。
HKCERT CTF 部分Re题解
闲来无事,勾栏解题,看了看香港的这个网安夺旗赛,感觉题目质量都挺高的,写一个博客记录一下我做的几题
Morph
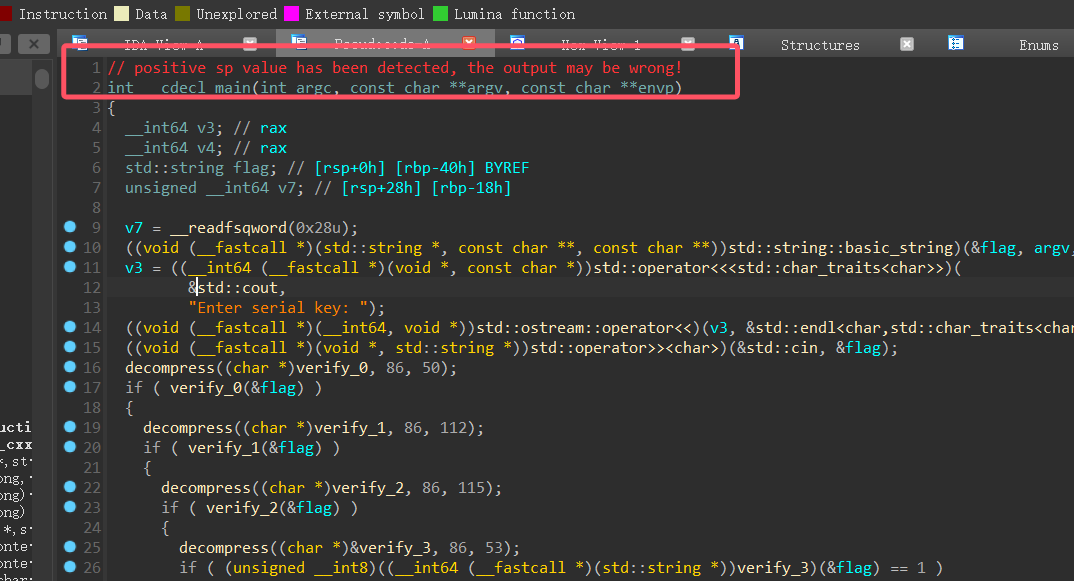
IDA分析报错,需要首先查看具体什么原因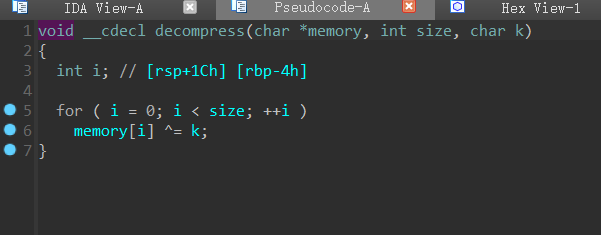
decompress是异或,其实从compress这个词我们就知道应该是对数据做一些处理了,处理的数据正好就是传参的verify函数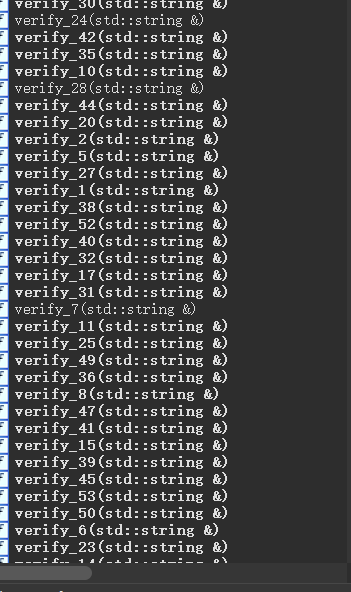
看到verify函数我们会发现有很多,所以一个个手动解混淆花费的时间有点多,根据decompress的传参我们可以发现每一个verify的字节大小都是86,但是每一个verify的传参不一致,但是写脚本获取传参过于麻烦,发现参数都在-128-128之间,正确的话前四个字节必然是F3 0F 1E FA,直接梭就完事了,就不需要读取decompress传入的参数了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | import reimport idautilsimport idaapiimport idcdef find_specific_verify_exports(): """ 查找导出表中名称以 _Z8verify_ 或 _Z9verify_ 开头且后面接一个数字的函数,并返回其名称和地址。 """ verify_exports = [] pattern = re.compile(r"^_Z(?:8|9)verify_(\d+)") # 匹配 _Z8verify_ 或 _Z9verify_ 后接数字的格式 for i in range(idaapi.get_entry_qty()): ordinal = idaapi.get_entry_ordinal(i) func_name = idaapi.get_entry_name(ordinal) # 检查函数名是否符合指定格式 if func_name and pattern.match(func_name): func_addr = idaapi.get_entry(ordinal) verify_exports.append((func_name, func_addr)) return verify_exportsdef xor_bytes(data, key): """将给定数据中的每个字节与指定的key进行异或""" return bytes([b ^ key for b in data])def patch_memory(address, xor_key): """直接对内存中的数据进行补丁""" original_data = idc.get_bytes(address, 86) # 读取从 address 到 address+85 的字节 if not original_data: print(f"无法读取地址 {hex(address)} 的数据") return False # 对数据进行异或 patched_data = xor_bytes(original_data, xor_key) # 写入补丁数据到内存中 for offset, byte in enumerate(patched_data): idc.patch_byte(address + offset, byte) print(f"已在内存中补丁地址范围 {hex(address)} 到 {hex(address+85)},使用异或键 {xor_key}") return Truedef process_address_range(address): """处理给定地址,尝试找到满足条件的异或数字并应用补丁""" original_data = idc.get_bytes(address, 86) # 读取从 address 到 address+85 的字节 if not original_data: print(f"无法读取地址 {hex(address)} 的数据") return None for xor_key in range(-255, 256): xor_key &= 0xFF # 保证异或键值在 0 到 255 的范围内 # 取地址到地址+3的数据并与当前 xor_key 异或 test_data = xor_bytes(original_data[:4], xor_key) # 检查异或后的前四个字节是否等于 F3 0F 1E FA if test_data == b'\xF3\x0F\x1E\xFA': # 满足条件时,直接补丁内存 if patch_memory(address, xor_key): print(f"成功对地址 {hex(address)} 应用补丁,异或键为 {xor_key}") return xor_key print(f"地址 {hex(address)} 没有找到满足条件的异或键") return None# 获取符合条件的地址列表并进行补丁filtered_exports = find_specific_verify_exports()if filtered_exports: print("开始处理符合条件的 'verify' 函数地址...") for func_name, func_addr in filtered_exports: print(f"Processing function: {func_name} at Address: {hex(func_addr)}") process_address_range(func_addr)else: print("No specific 'verify' functions found in export table.") |
IDApython直接识别开始爆破,修复后可能IDA还识别不过来,这个时候可以保存好patch后的附件,或者跑下面的IDApython代码重新识别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 | import reimport idautilsimport idaapiimport idc# 步骤2:删除所有现有的函数定义print("Starting to undefine all existing functions...")for func_ea in idautils.Functions(): func_name = idc.get_func_name(func_ea) print(f"Undefining function {func_name} at {hex(func_ea)}") idc.del_func(func_ea) # 删除函数定义print("All functions have been undefined.")# 步骤3:将所有代码区域设置为未定义状态,但跳过数据段print("Setting all instructions and data to undefined in code segments...")for seg_ea in idautils.Segments(): # 跳过数据段,仅处理代码段 if idc.get_segm_attr(seg_ea, idc.SEGATTR_TYPE) != idc.SEG_CODE: print(f"Skipping data segment at {hex(seg_ea)}") continue start = seg_ea end = idc.get_segm_end(seg_ea) # 遍历段中的每个地址,并将其设置为未定义 for head in idautils.Heads(start, end): idc.del_items(head, idc.DELIT_SIMPLE) # 将所有指令和数据设置为未定义print("All code in code segments set to undefined.")# 步骤4:重新标记整个程序的代码段以进行重新分析print("Marking all code segments for reanalysis...")for seg_ea in idautils.Segments(): if idc.get_segm_attr(seg_ea, idc.SEGATTR_TYPE) == idc.SEG_CODE: ida_auto.auto_mark_range(seg_ea, idc.get_segm_end(seg_ea), ida_auto.AU_CODE)ida_auto.auto_wait() # 等待重新分析完成print("Reanalyzed all code segments, excluding data segments.") |
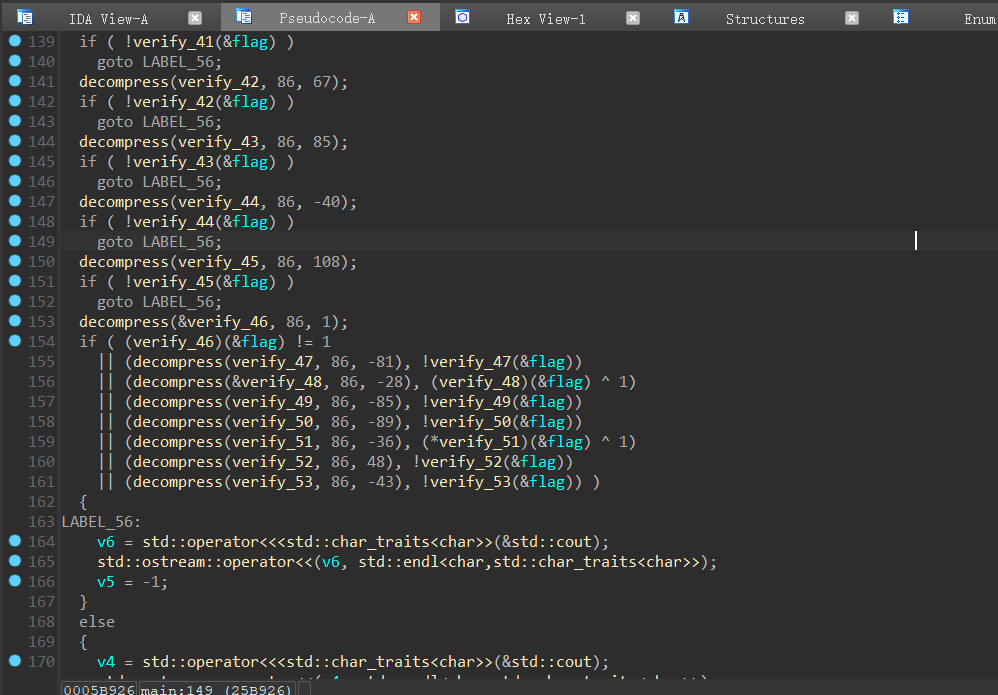
弄好之后小时的代码都回来了
每一次都是前后两个位置的异或等于一个值,继续搓脚本输出他,把每一位结果记录下来,构建约束关系,然后z3梭哈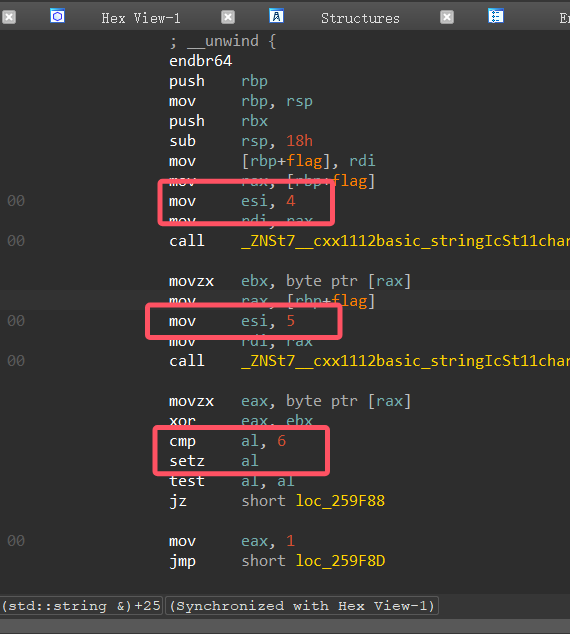
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | import reimport idaapiimport idautilsimport idcdef find_specific_verify_exports(): """ 查找导出表中名称以 _Z8verify_ 或 _Z9verify_ 开头且后面接一个数字的函数,并返回其名称和地址。 """ verify_exports = [] pattern = re.compile(r"^_Z(?:8|9)verify_(\d+)") # 匹配 _Z8verify_ 或 _Z9verify_ 后接数字的格式 for i in range(idaapi.get_entry_qty()): ordinal = idaapi.get_entry_ordinal(i) func_name = idaapi.get_entry_name(ordinal) # 检查函数名是否符合指定格式 if func_name and pattern.match(func_name): func_addr = idaapi.get_entry(ordinal) verify_exports.append((func_name, func_addr)) return verify_exportsdef extract_equation_from_verify(func_addr): """ 从每个 verify 函数中提取 mov esi 和 cmp al 指令来生成方程。 """ esi_values = [] cmp_value = None # 遍历函数指令,直到找到目标指令或到达函数结束 for instr_addr in idautils.FuncItems(func_addr): mnemonic = idc.print_insn_mnem(instr_addr) # 查找 mov esi, <imm> 指令 if mnemonic == "mov" and "esi" in idc.print_operand(instr_addr, 0): esi_value = idc.get_operand_value(instr_addr, 1) esi_values.append(esi_value) # 查找 cmp al, <imm> 指令 elif mnemonic == "cmp" and "al" in idc.print_operand(instr_addr, 0): cmp_value = idc.get_operand_value(instr_addr, 1) # 当找到两个 esi 值和一个 cmp 值时,可以生成方程 if len(esi_values) == 2 and cmp_value is not None: break # 确保收集到所有所需的值 if len(esi_values) == 2 and cmp_value is not None: equation = f"input[0x{esi_values[0]:X}] ^ input[0x{esi_values[1]:X}] == 0x{cmp_value:X}" return equation else: return None# 主函数,获取所有符合条件的 verify 函数并提取方程filtered_exports = find_specific_verify_exports()if filtered_exports: print("生成 verify 函数的方程:") for func_name, func_addr in filtered_exports: equation = extract_equation_from_verify(func_addr) if equation: print(f"{func_name}: {equation}") else: print(f"{func_name}: 无法生成方程")else: print("未找到符合条件的 'verify' 函数") |
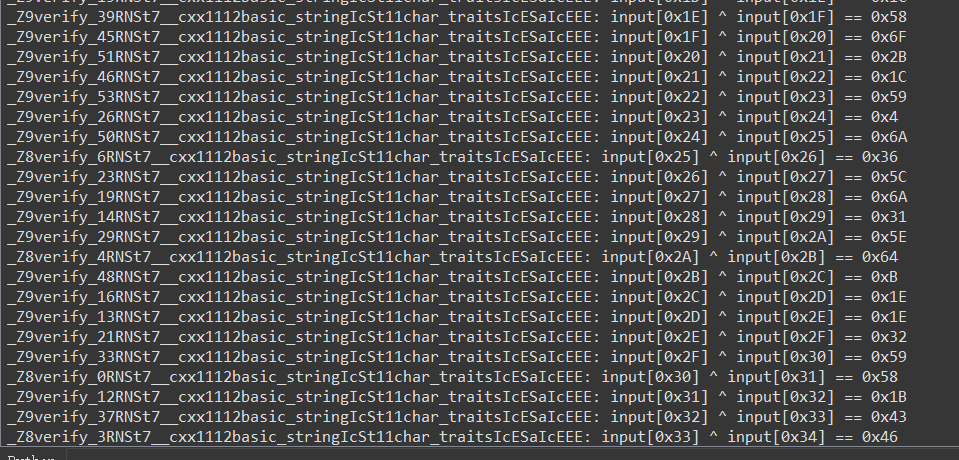
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 | from z3 import *# 创建 0x37(55)个字节的输入变量(假设从 input[0] 到 input[0x36])input_vars = [BitVec(f'input_{i}', 8) for i in range(0x37)]# 初始化 Z3 Solversolver = Solver()# 添加方程到 solverconstraints = [ input_vars[0x0] ^ input_vars[0x1] == 0x3, input_vars[0x1] ^ input_vars[0x2] == 0x8, input_vars[0x2] ^ input_vars[0x3] == 0x6, input_vars[0x3] ^ input_vars[0x4] == 0x17, input_vars[0x4] ^ input_vars[0x5] == 0x6, input_vars[0x5] ^ input_vars[0x6] == 0x46, input_vars[0x6] ^ input_vars[0x7] == 0x6, input_vars[0x7] ^ input_vars[0x8] == 0x4F, input_vars[0x8] ^ input_vars[0x9] == 0x8, input_vars[0x9] ^ input_vars[0xA] == 0x40, input_vars[0xA] ^ input_vars[0xB] == 0x5F, input_vars[0xB] ^ input_vars[0xC] == 0xA, input_vars[0xC] ^ input_vars[0xD] == 0x39, input_vars[0xD] ^ input_vars[0xE] == 0x32, input_vars[0xE] ^ input_vars[0xF] == 0x5D, input_vars[0xF] ^ input_vars[0x10] == 0x54, input_vars[0x10] ^ input_vars[0x11] == 0x55, input_vars[0x11] ^ input_vars[0x12] == 0x57, input_vars[0x12] ^ input_vars[0x13] == 0x1F, input_vars[0x13] ^ input_vars[0x14] == 0x48, input_vars[0x14] ^ input_vars[0x15] == 0x5F, input_vars[0x15] ^ input_vars[0x16] == 0x9, input_vars[0x16] ^ input_vars[0x17] == 0x38, input_vars[0x17] ^ input_vars[0x18] == 0x3C, input_vars[0x18] ^ input_vars[0x19] == 0x53, input_vars[0x19] ^ input_vars[0x1A] == 0x54, input_vars[0x1A] ^ input_vars[0x1B] == 0x57, input_vars[0x1B] ^ input_vars[0x1C] == 0x6C, input_vars[0x1C] ^ input_vars[0x1D] == 0x2B, input_vars[0x1D] ^ input_vars[0x1E] == 0x1C, input_vars[0x1E] ^ input_vars[0x1F] == 0x58, input_vars[0x1F] ^ input_vars[0x20] == 0x6F, input_vars[0x20] ^ input_vars[0x21] == 0x2B, input_vars[0x21] ^ input_vars[0x22] == 0x1C, input_vars[0x22] ^ input_vars[0x23] == 0x59, input_vars[0x23] ^ input_vars[0x24] == 0x4, input_vars[0x24] ^ input_vars[0x25] == 0x6A, input_vars[0x25] ^ input_vars[0x26] == 0x36, input_vars[0x26] ^ input_vars[0x27] == 0x5C, input_vars[0x27] ^ input_vars[0x28] == 0x6A, input_vars[0x28] ^ input_vars[0x29] == 0x31, input_vars[0x29] ^ input_vars[0x2A] == 0x5E, input_vars[0x2A] ^ input_vars[0x2B] == 0x64, input_vars[0x2B] ^ input_vars[0x2C] == 0xB, input_vars[0x2C] ^ input_vars[0x2D] == 0x1E, input_vars[0x2D] ^ input_vars[0x2E] == 0x1E, input_vars[0x2E] ^ input_vars[0x2F] == 0x32, input_vars[0x2F] ^ input_vars[0x30] == 0x59, input_vars[0x30] ^ input_vars[0x31] == 0x58, input_vars[0x31] ^ input_vars[0x32] == 0x1B, input_vars[0x32] ^ input_vars[0x33] == 0x43, input_vars[0x33] ^ input_vars[0x34] == 0x46, input_vars[0x34] ^ input_vars[0x35] == 0x41, input_vars[0x35] ^ input_vars[0x36] == 0x4E]# 将所有约束添加到 solver 中for constraint in constraints: solver.add(constraint)# 添加输入的范围约束for var in input_vars: solver.add(var >= 0x20, var <= 0x7E) # 限制每个 input 变量在可见 ASCII 字符范围内# 找到并展示所有解solutions = []while solver.check() == sat: model = solver.model() solution = [model[input_vars[i]].as_long() for i in range(0x37)] solutions.append(solution) # 将解转换为排除条件,确保寻找不同的解 solver.add(Or([input_vars[i] != solution[i] for i in range(0x37)]))# 输出所有解for i, solution in enumerate(solutions, 1): readable_solution = ''.join(chr(val) for val in solution) print(f"解 {i}: {readable_solution}") |
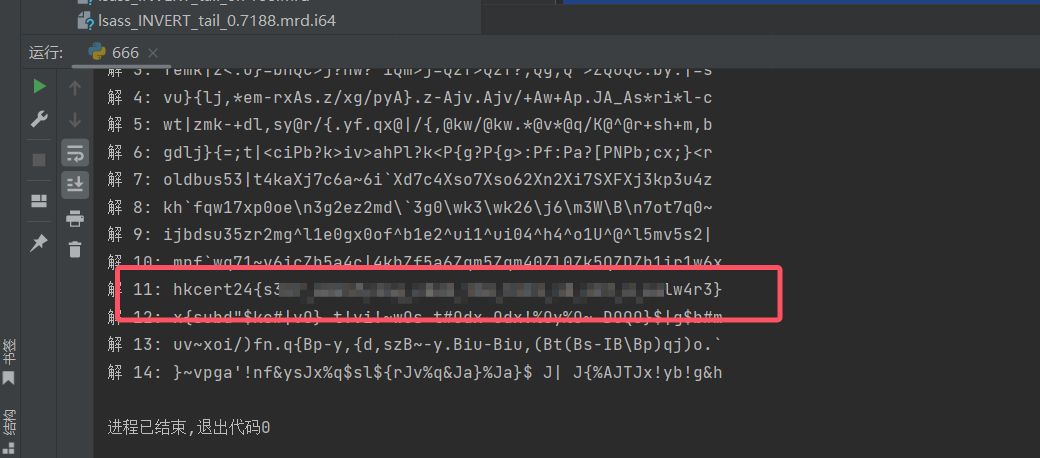
Void
Script语句中把解密后的源码打印出来即可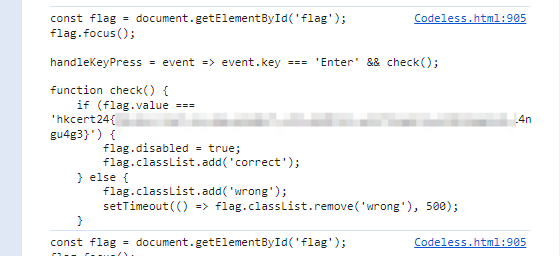
Yet another crackme
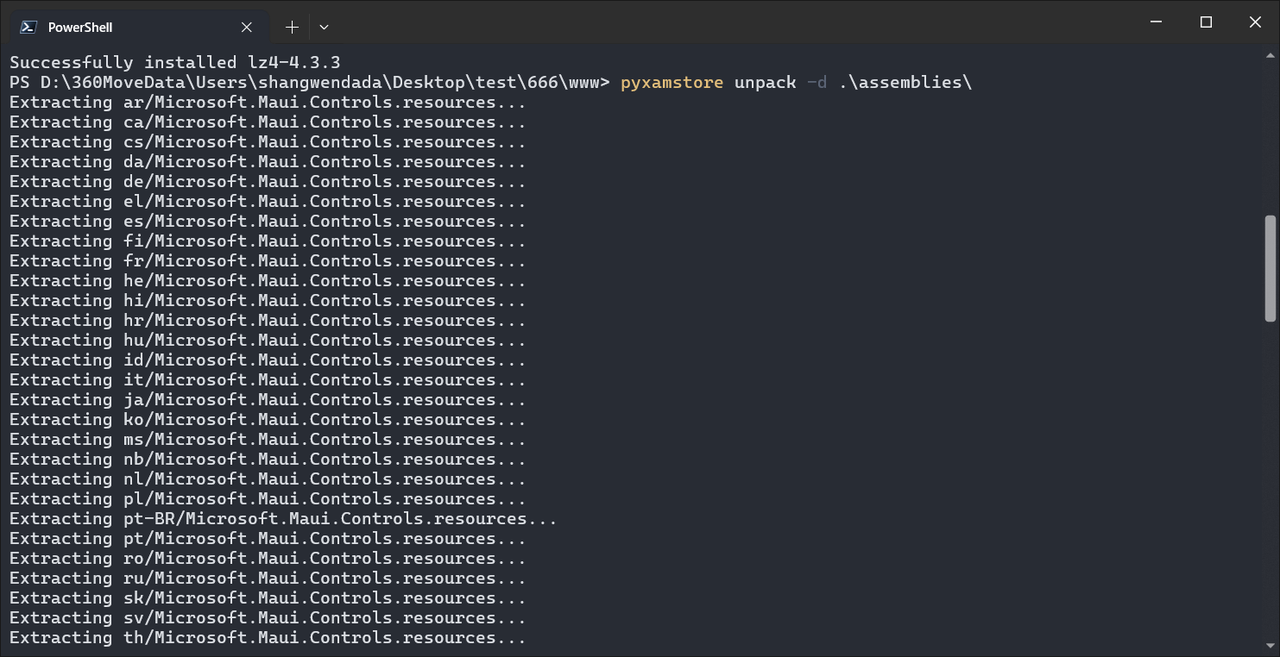
解包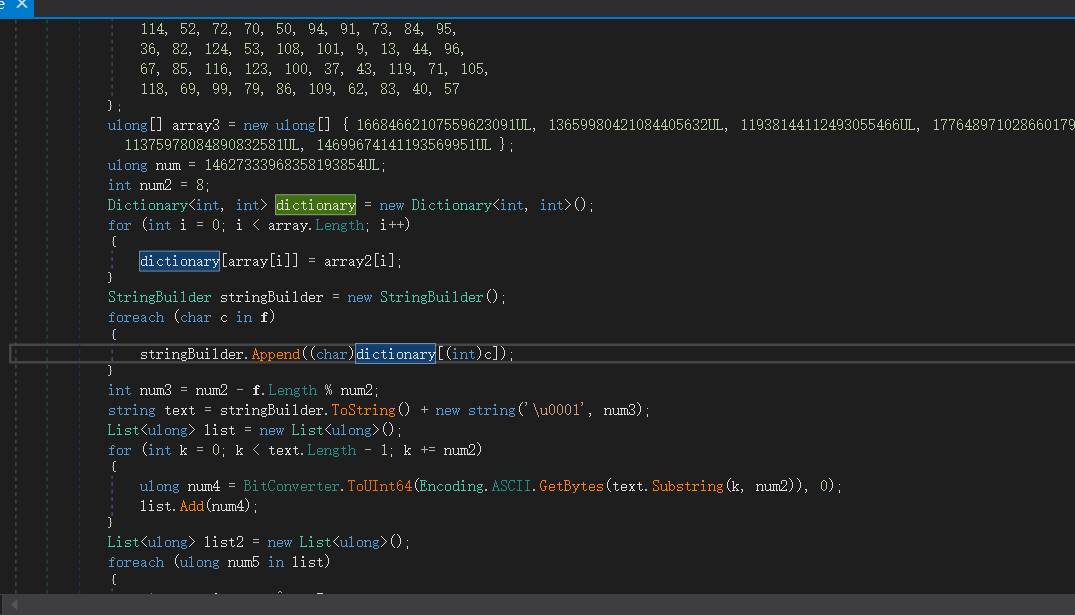
随便解密就好了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | import struct# 给定的映射数组array = [ 9, 10, 11, 12, 13, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126]array2 = [ 58, 38, 66, 88, 78, 39, 80, 125, 64, 106, 48, 49, 98, 32, 42, 59, 126, 93, 33, 56, 112, 120, 60, 117, 111, 45, 87, 35, 10, 68, 61, 77, 11, 55, 121, 74, 107, 104, 65, 63, 46, 110, 34, 41, 102, 97, 81, 12, 47, 51, 103, 89, 115, 75, 54, 92, 90, 76, 113, 122, 114, 52, 72, 70, 50, 94, 91, 73, 84, 95, 36, 82, 124, 53, 108, 101, 9, 13, 44, 96, 67, 85, 116, 123, 100, 37, 43, 119, 71, 105, 118, 69, 99, 79, 86, 109, 62, 83, 40, 57]array3 = [16684662107559623091, 13659980421084405632, 11938144112493055466, 17764897102866017993, 11375978084890832581, 14699674141193569951]num = 14627333968358193854num2 = 8# 生成逆映射:从 array2 到 arrayreverse_map = {array2[i]: array[i] for i in range(len(array))}# 逆向构造字符串def find_flag(): result = [] for target in array3: # 反向异或 num 和 target num6 = num ^ target # 将得到的 num6 转换为字符串 try: bytes_text = struct.pack("<Q", num6) # 小端字节序解码 decoded_text = "".join(chr(reverse_map.get(b, b)) for b in bytes_text if b in reverse_map) result.append(decoded_text) except KeyError: # 如果映射不完全,跳过此字符(可以进一步调试) continue return ''.join(result)# 输出可能的 flag 值flag = find_flag()print(f"Possible flag: {flag}") |
MBTI Radar
IL2CPP的题目,正好之前有过一段时间的研究。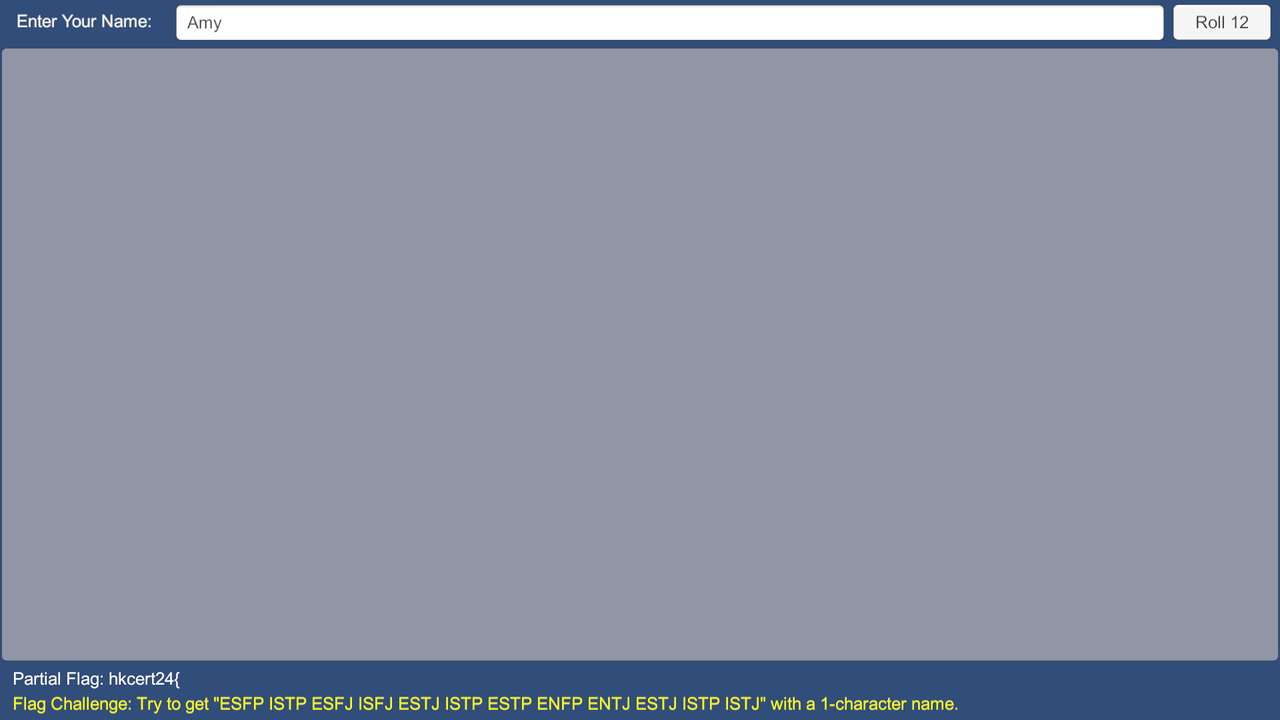
用户输入产生MBTI数据,需要产生一一对应的数据
首先还是利用dumper把符号表之类的dump下来
恢复符号表啥的操作就不细说了详情可以看https://bbs.kanxue.com/thread-282821.htm
先用Dnspy观察: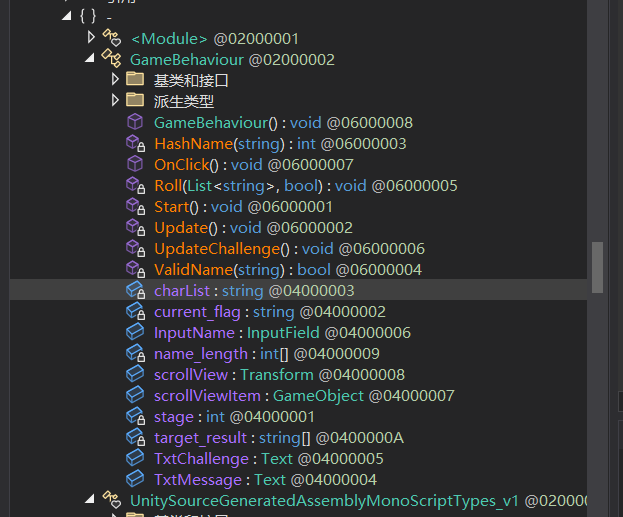
可以发现逻辑不多,分析起来难度不会很大
根据Il2cpp的特性,我们知道方法传入的a1其实就是这个类里面一些成员变量组成的结构体之类的,我们可以通过偏移来推断到底是个什么类: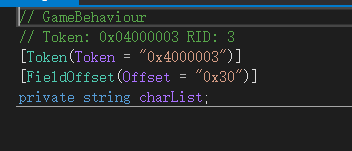
像这个charList就是a1+0x30:
于是我们在GameBehaviour__OnClick中就可以发现如下逻辑了:
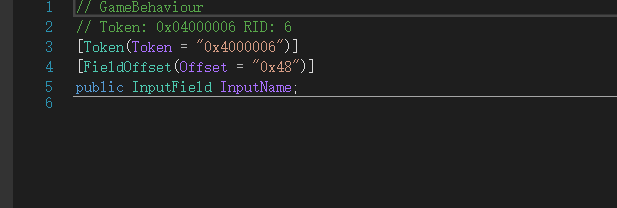
首先看到偏移0x48就是InputName,在onclick中查找
不难发现:
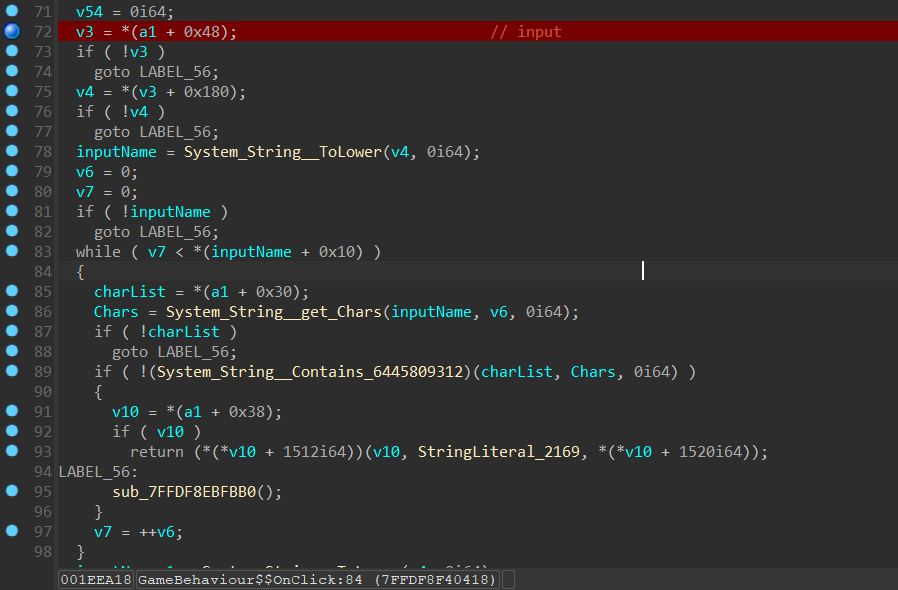
这一段就是获取了onClick和charList,做一些基础的对象的处理
下面就是关键逻辑了: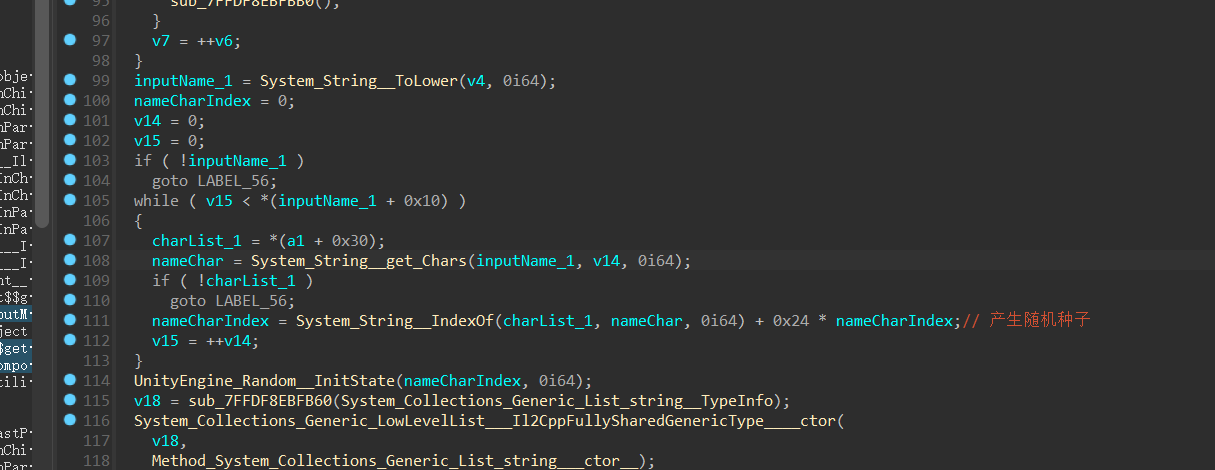
调试发现,这里利用我们输入的名字在table中取了索引,然后对索引做了一个似乎是0x24进制的操作,储存到一个值中,我们可以看到UnityEngine_Random__InitState这个是Unity的一个设置随机中的的方法,类似于srand。
接下来过了一些基础操作就可以看到下一个关键逻辑了:
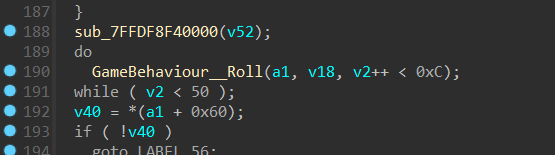
这里的0xc其实就是对应题目的12个MBTI
那么MBTI的生成逻辑肯定在里面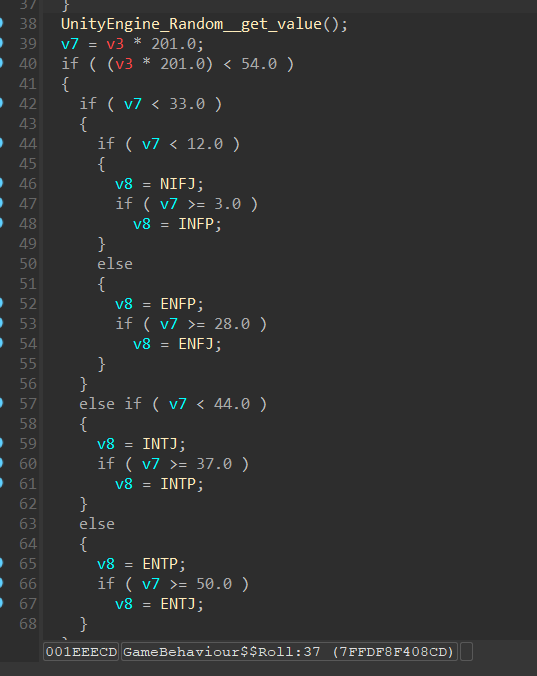
发现就是利用seed产生的value做运算了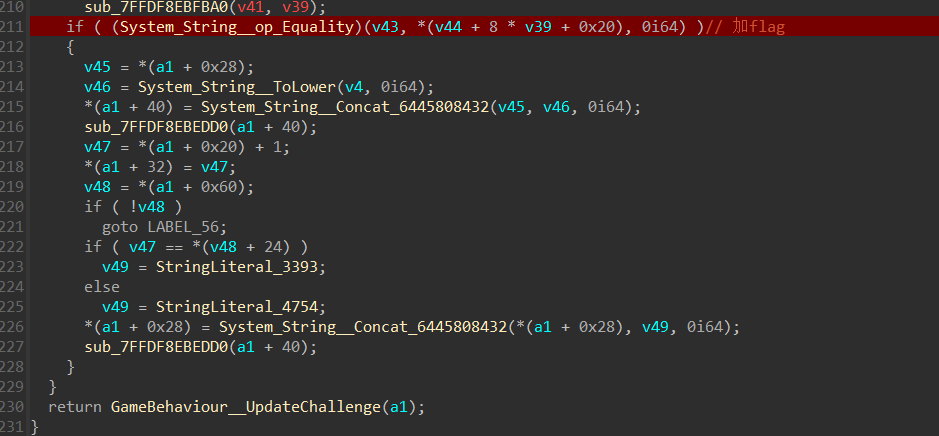
到这里比较就完事了。
我们新建一个Unity项目
编辑->资源->创建一个C#脚本
然后点击我们的Main Camera,给Main Camera添加一个组件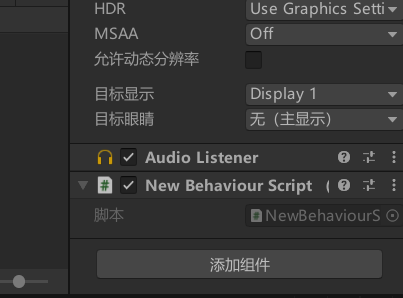
添加我们的脚本进去,就可以执行我们的脚本了,正好一个很巧的事情发生了,一开始随便输入了一个1,然后程序居然正确了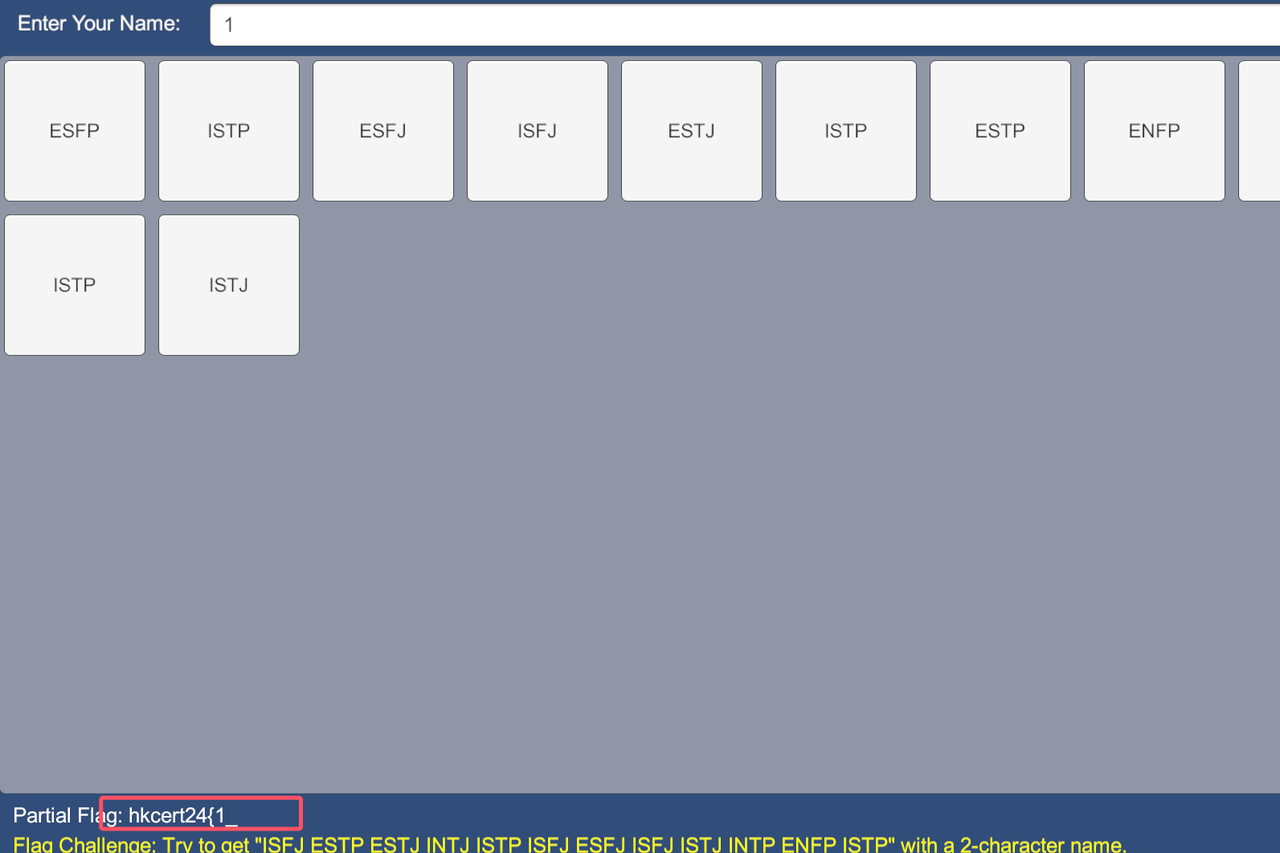
这样正好给我们提供了一个测试思路的用例,1的索引正好就是1,我们写脚本验证一下
这里脚本需要注意: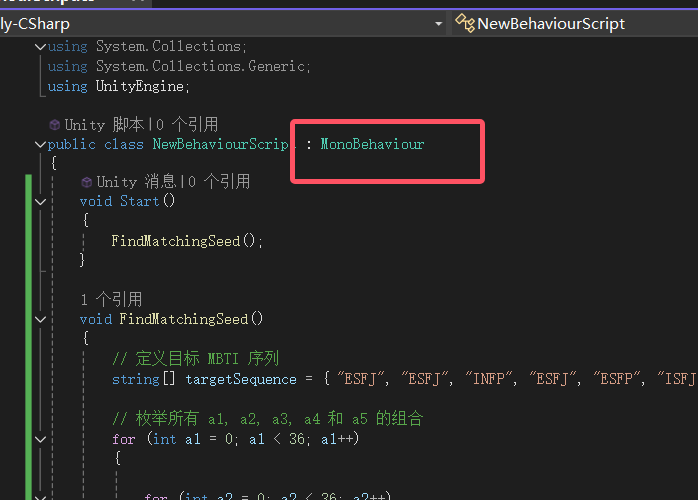
继承的类得是MonoBehavior
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 | using UnityEngine;public class NewBehaviourScript: MonoBehaviour{ void Start() { GenerateTypes(12); // 生成并输出12个对应类型 } void GenerateTypes(int count) { int seed = 42; // 设置种子以确保每次生成相同的随机序列 Random.InitState(seed); for (int i = 0; i < count; i++) { float randomValue = Random.value; float v7 = randomValue * 201.0f; string v8; // 根据提供的条件,判断对应的类型 if (v7 < 54.0f) { if (v7 < 33.0f) { if (v7 < 12.0f) { v8 = v7 >= 3.0f ? "INFP" : "NIFJ"; } else { v8 = v7 >= 28.0f ? "ENFJ" : "ENFP"; } } else if (v7 < 44.0f) { v8 = v7 >= 37.0f ? "INTP" : "INTJ"; } else { v8 = v7 >= 50.0f ? "ENTJ" : "ENTP"; } } else if (v7 < 147.0f) { if (v7 < 105.0f) { v8 = v7 >= 77.0f ? "ISFJ" : "ISTJ"; } else { v8 = v7 >= 122.0f ? "ESFJ" : "ESTJ"; } } else if (v7 < 176.0f) { v8 = v7 >= 158.0f ? "ISFP" : "ISTP"; } else { v8 = v7 >= 184.0f ? "ESFP" : "ESTP"; } Debug.Log(v8); // 输出类型结果 } }} |
对应上了,我们就直接开始爆破了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 | using System.Collections;using System.Collections.Generic;using UnityEngine;public class NewBehaviourScript : MonoBehaviour{ void Start() { FindMatchingSeed(); } void FindMatchingSeed() { // 定义目标 MBTI 序列 string[] targetSequence = { "ESFJ", "ESFJ", "INFP", "ESFJ", "ESFP", "ISFJ", "ESTJ", "ESFJ", "ESTJ", "ISFJ", "ISFP", "ISFJ" }; // 枚举所有 a1, a2, a3, a4 和 a5 的组合 for (int a1 = 0; a1 < 36; a1++) { for (int a2 = 0; a2 < 36; a2++) { for (int a3 = 0; a3 < 36; a3++) { for (int a4 = 0; a4 < 36; a4++) { for (int a5 = 0; a5 < 36; a5++) { for(int a6 = 0;a6 < 36; a6++) { int seed = a1 + 0x24 * a2 + 0x24 * 0x24 * a3 + 0x24 * 0x24 * 0x24 * a4 + 0x24 * 0x24 * 0x24 * 0x24 * a5 + 0x24 * 0x24 * 0x24 * 0x24 * 0x24*a6 ; if (CheckMBTISeries(seed, targetSequence)) { Debug.Log($"Match found! a1: {a1}, a2: {a2}, a3: {a3}, a4: {a4}, a5: {a5},a6:{a6}, seed: {seed}"); return; // 找到匹配项后终止搜索 } } } } } Debug.Log(a2); } } Debug.Log("No matching seed found."); } bool CheckMBTISeries(int seed, string[] targetSequence) { string[] generatedSequence = new string[12]; // 使用生成的种子初始化随机数生成器 Random.InitState(seed); // 生成 12 个 MBTI 类型 for (int i = 0; i < 12; i++) { float randomValue = Random.value; float v7 = randomValue * 201.0f; generatedSequence[i] = DetermineMBTI(v7); } // 检查生成的序列是否与目标序列匹配 for (int i = 0; i < 12; i++) { if (generatedSequence[i] != targetSequence[i]) return false; // 一旦有不匹配的情况,返回 false } return true; // 所有值都匹配,返回 true } string DetermineMBTI(float v7) { // 根据条件生成 MBTI 类型 if (v7 < 54.0f) { if (v7 < 33.0f) { if (v7 < 12.0f) { return v7 >= 3.0f ? "INFP" : "NIFJ"; } else { return v7 >= 28.0f ? "ENFJ" : "ENFP"; } } else if (v7 < 44.0f) { return v7 >= 37.0f ? "INTP" : "INTJ"; } else { return v7 >= 50.0f ? "ENTJ" : "ENTP"; } } else if (v7 < 147.0f) { if (v7 < 105.0f) { return v7 >= 77.0f ? "ISFJ" : "ISTJ"; } else { return v7 >= 122.0f ? "ESFJ" : "ESTJ"; } } else if (v7 < 176.0f) { return v7 >= 158.0f ? "ISFP" : "ISTP"; } else { return v7 >= 184.0f ? "ESFP" : "ESTP"; } }} |
这里我只写了六位数据的爆破,需要跑大概半个小时,前面1-5个长度的名字基本都在一分钟内,五个长度需要一分钟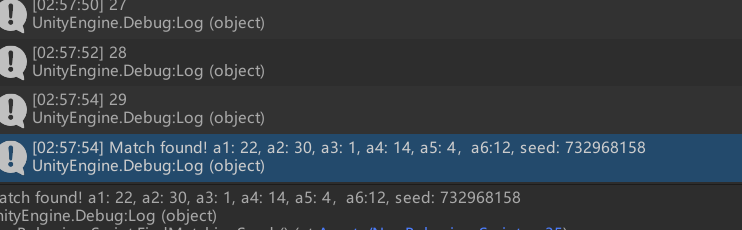
写个脚本整理结果就好了
1 2 3 4 5 6 7 8 | table = "0123456789abcdefghijklmnopqrstuvwxyz"index1 = [[1], [4,22],[24,23,3],[5,29,4,27],[30,23,13,3,27],[12,4,14,1,30,22]]for i in index1: for j in i: print(table[j], end='') print("",end="_") |

更多【CTF对抗-HKCERT CTF 部分Re题解】相关视频教程:www.yxfzedu.com
相关文章推荐
- 企业安全-学习Kubernetes笔记——部署web站点环境(PHP+Nginx) - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——安装NFS驱动 - Android安全CTF对抗IOS安全
- 企业安全-学习Kubernetes笔记——kubeadm安装Kubernetes - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(四) - Android安全CTF对抗IOS安全
- 软件逆向-使用IDAPython开发复制RVA的插件 - Android安全CTF对抗IOS安全
- 2-wibu软授权(三) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(二) - Android安全CTF对抗IOS安全
- 软件逆向-wibu软授权(一) - Android安全CTF对抗IOS安全
- 软件逆向- PE格式:分析IatHook并实现 - Android安全CTF对抗IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全CTF对抗IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全CTF对抗IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全CTF对抗IOS安全
- CTF对抗-lua 逆向学习 & RCTF picstore 还原代码块 - Android安全CTF对抗IOS安全
- Android安全-如何修改unity HybridCLR 热更dll - Android安全CTF对抗IOS安全
- 软件逆向-浅谈编译器对代码的优化 - Android安全CTF对抗IOS安全
- 二进制漏洞-年终CLFS漏洞汇总分析 - Android安全CTF对抗IOS安全
- 软件逆向-自动化提取恶意文档中的shellcode - Android安全CTF对抗IOS安全
- 二进制漏洞-铁威马TerraMaster CVE-2022-24990&CVE-2022-24989漏洞分析报告 - Android安全CTF对抗IOS安全
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo) - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- spring-在Spring Boot中使用JTA实现对多数据源的事务管理
- 3d-原始html和vue中使用3dmol js展示分子模型,pdb文件
- ddos-DDoS攻击剧增,深入解析抗DDoS防护方案
- spring boot-AI 辅助学习:Spring Boot 集成 PostgreSQL 并设置最大连接数
- golang-go中的rune类型
- python-深度学习之基于Python+OpenCV(DNN)性别和年龄识别系统
- 运维-Linux-Docker的基础命令和部署code-server
- 算法-421. 数组中两个数的最大异或值/字典树【leetcode】
- 编程技术-解非线性方程python实现黄金分割法
- 学习-Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks - 翻译学习