Android安全-shopee app算法分析第二篇
推荐 原创【Android安全-shopee app算法分析第二篇】此文章归类为:Android安全。
shopee app算法分析第二篇
第一篇地址:https://bbs.kanxue.com/thread-284570.htm
上一篇我们把unidbg跑通了,这一篇我们把这几个字段还原了.
固定随机
clock_gettime和randBytes固定即可.需要注意访问随机数的时候,每次虽然读了4个字节,但只使用第一个字节
注意事项:全随机0的话,很多东西一眼就能看出来,但同时容易丢失步骤. 用不同的随机固定,步骤更完整,但较难一眼观察出一些数据,所以要结合起来事半功倍.
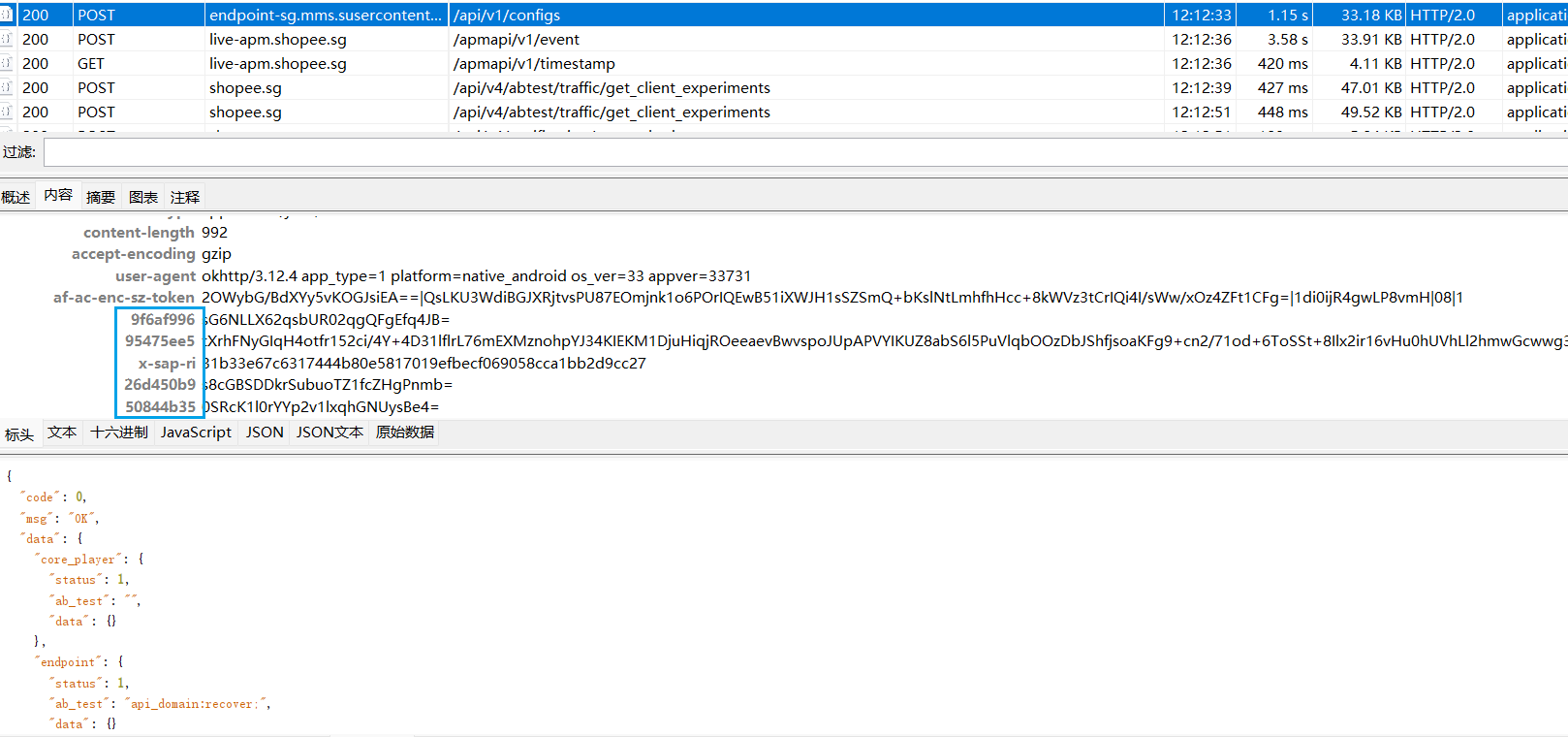
x-sap-ri
固定成全0后发现是

1668436800000000000000100100000000000000000000000000
很明显前面4字节是时间戳,后面还有22字节
1 2 | 00000000 00 00 00 00 00 00 00 10 01 00 00 00 00 00 00 00 |................|00000010 00 00 00 00 00 00 |......| |
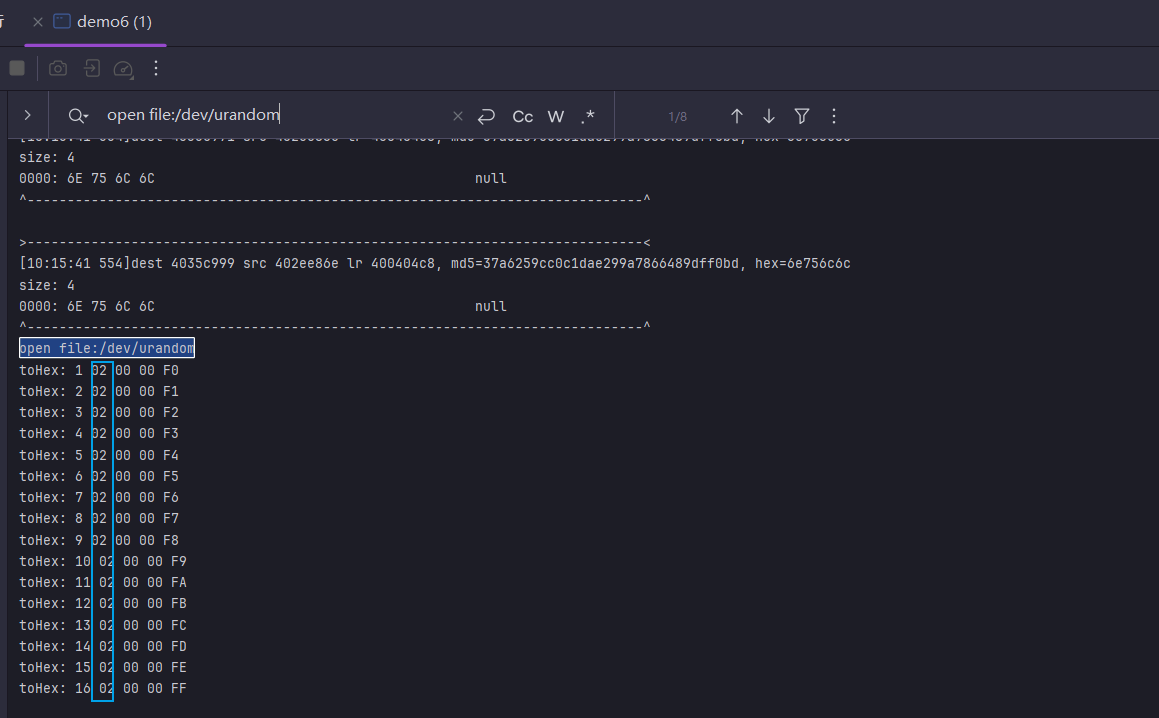
找到最开始位置
发现离这里最近的位置读了22字节的随机,当然可以怀疑后面22字节来自上面随机,略有不一样的地方是第8字节和第9字节是1001.跟踪写入可以直接找到在0x084518位置.

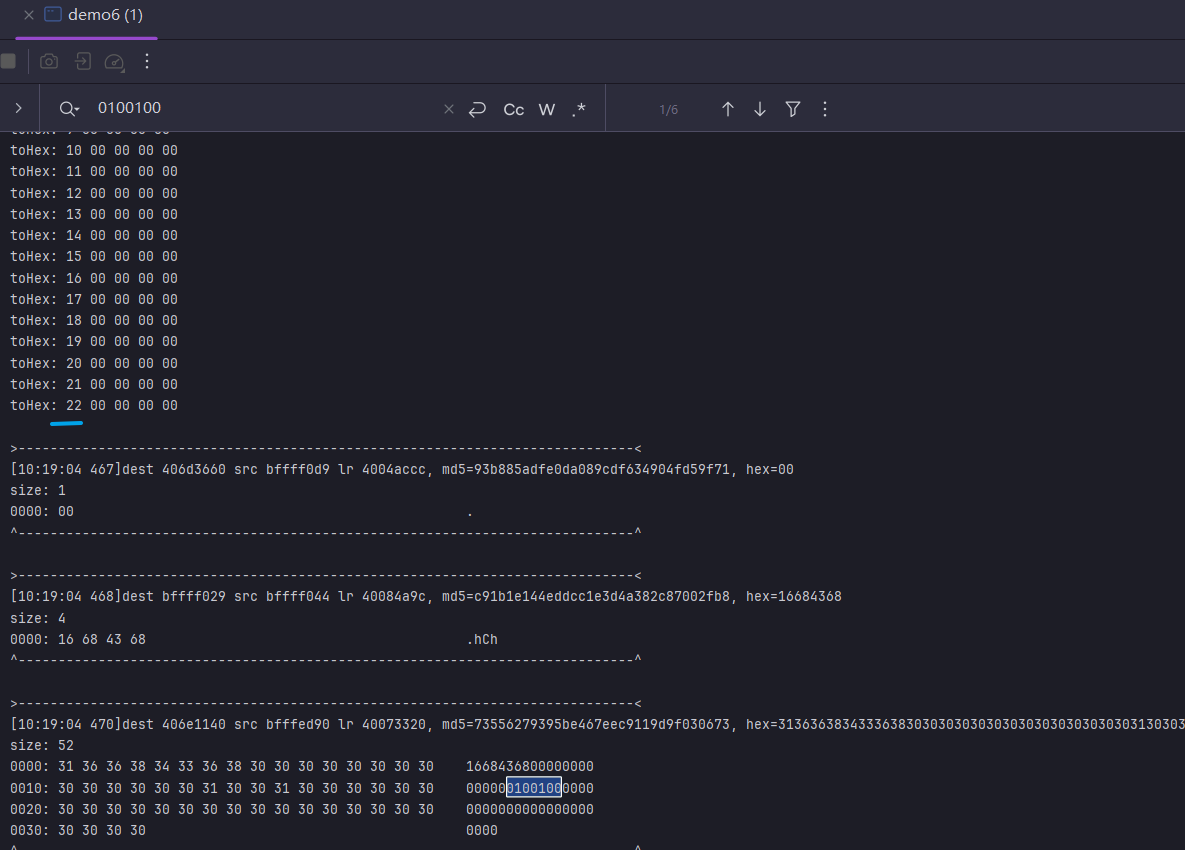
tarce完在010editor里面搜,以0x10为例
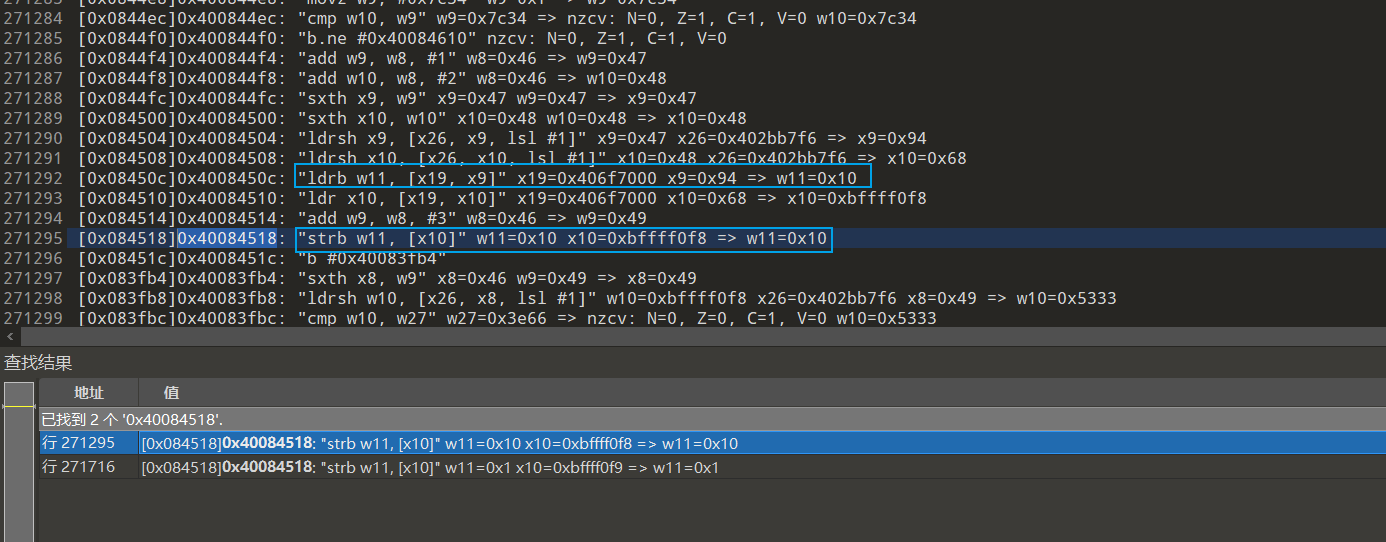
来自[0x08450c]0x4008450c: "ldrb w11, [x19, x9]" x19=0x406f7000 x9=0x94 => w11=0x10 可以直接搜0x10,也可以搜偏移0x94,前者容易定位到最开始生成位置,但是也容易找不到.后者比较稳,但是有可能要花更多时间.
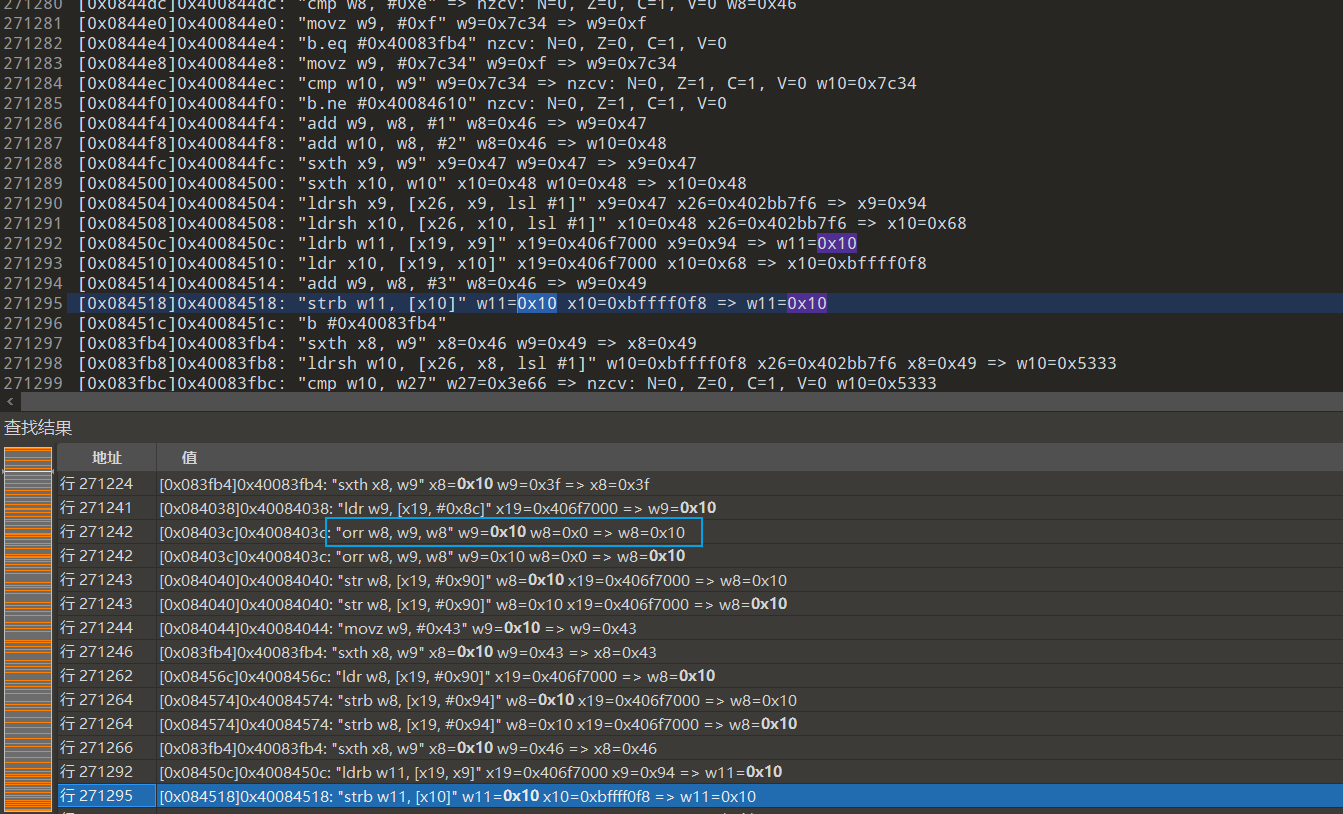
最近一次的生成位置[0x08403c]0x4008403c: "orr w8, w9, w8" w9=0x10 w8=0x0 => w8=0x10
往上跟踪发现0x10固定,0x0来自0x0&0xf,也就是说随机第8字节的第一位一定是1.后面的01同理.所以算法如下.
1 2 3 4 5 6 7 8 9 | def getX_api_ri(timestamp): hex_string = ''.join(random.choice('0123456789abcdef') for _ in range(44)) hex_list = list(hex_string) hex_list[14] = '1' # 第15位 hex_list[16] = '0' # 第17位 hex_list[17] = '1' # 第18位 这块必须是这样,否则第一层就被拦截了 random_hex_string = timestamp.to_bytes(4,byteorder='little').hex()+''.join(hex_list) return random_hex_string |
这块必须是这样,如果不一样,第一层就被拦截了,直接418.
4个key value
key1
有一个key发现frida调用的时候始终是固定的,只和输入有关,剩余3个一直变化.从这个不变的入手.刚好unidbg日志中也可看出这个是最先生成的.1a9ec9b9,4字节,直接搜就有结果
[0x1bfb54]0x401bfb54: "and w11, w13, w11" w13=0x7fffffff w11=0x9a9ec9b9 => w11=0x1a9ec9b9
往上找发现0x7fffffff 固定.
[0x1bfe28]0x401bfe28: "add w14, w1, w14" w1=0x72 w14=0x9a9ec947 => w14=0x9a9ec9b9
[0x1bfcb0]0x401bfcb0: "mul w11, w11, w13" w11=0x334b w13=0x89a70875 => w11=0x9a9ec947
[0x1bfe28]0x401bfe28: "add w14, w1, w14" w1=0x61 w14=0x89a70814 => w14=0x89a70875
[0x1bfcb0]0x401bfcb0: "mul w11, w11, w13" w11=0x334b w13=0x18cf7bc => w11=0x89a70814
这一眼就可以看出在一个循环,0x334b是固定值,0x72,0x61是输入的url /api/v4/pages/bottom_tab_bar的十六进制.所以算法如下.
1 2 3 4 5 6 7 | def getKey1(url): tmp = 0 for i in bytearray(url.encode()): tmp = tmp*0x334b & 0xffffffff tmp=(tmp+i) & 0xffffffff key = tmp&0x7fffffff return f"{key:04x}" |
最近面试了某大厂,同事面的时候面试官问了一个问题印象很深刻.记得应该是这样,你不是很会trace吗,如果某一块算法在vmp里面,而且是一个循环结构,但事先不知道,如何应对呢?当时回答的是,vmp里面不是很好分辨,我觉得至少要弄出一轮来才好进行后续的循环.当时没考虑那么多,只想到了这个,其实判断循环特别简单,只需要在循环结构里面搜索一个参与运算的指令,搜索这行汇编即可判断.判断出来就好操作了
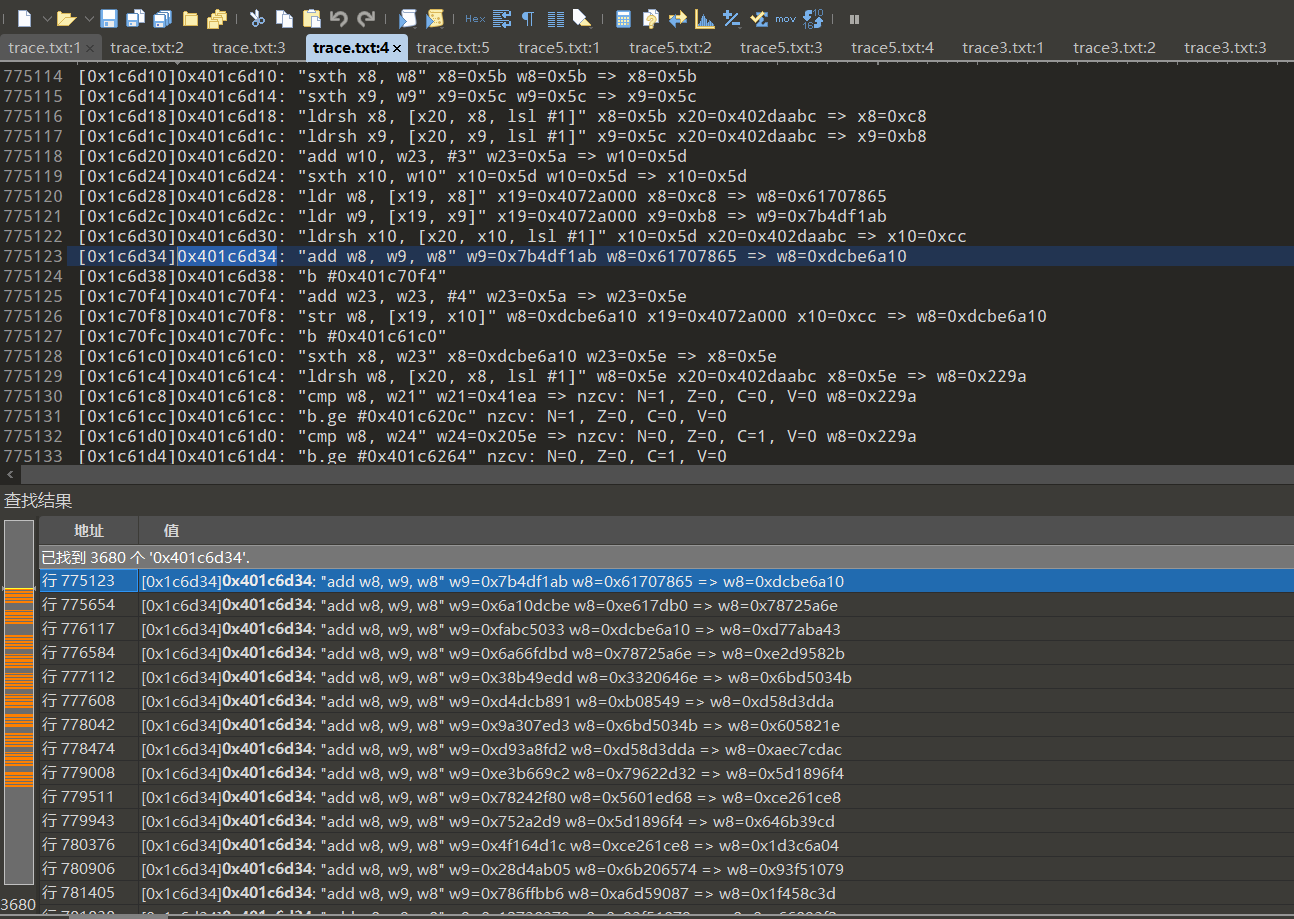
比如这里进行了10次chacha20,从左边的图就能看出来.但有的时候这行汇编可能不止只给一个位置使用,其他需要加法的也是这里怎么判断呢,通常可以正则匹配或者根据特征来判断,比如每进行4次加就有1次是循环中特点位置的加法,这样即可过滤出所在位置的运算.
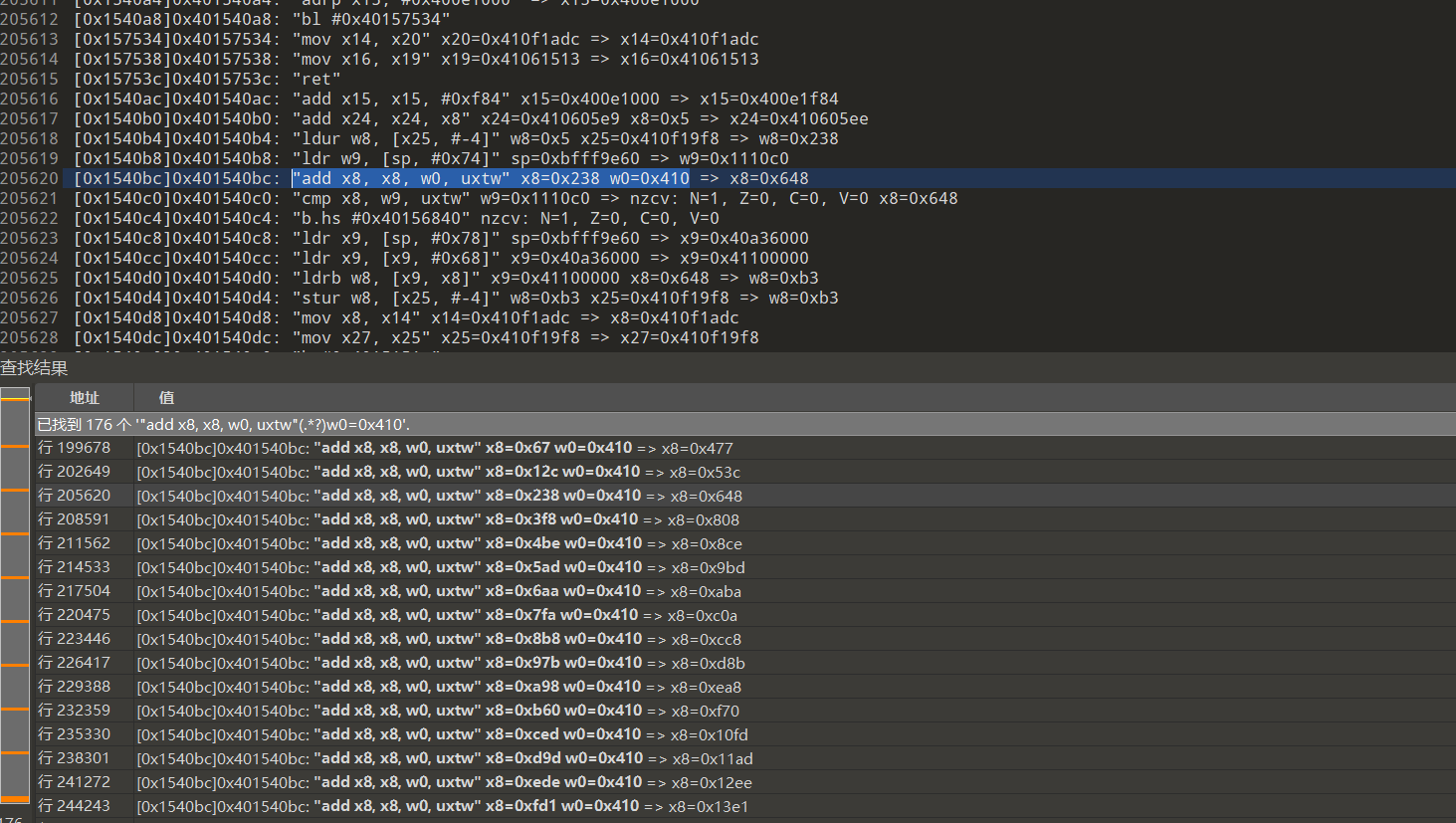
比如s1的vmp aes中的subbytes即可通过匹配偏移特征通过正则找到所有subbytes的过程,如下图 11*16=176
value1
从unidbg日志中看到key1生成后接着value1就生成了,然后才是后面的,所以应当按顺序来,因为有可能后面的参数中有需要前面的结果,事实也是如此.
1 2 | 0000: 74 2F 41 4F 6F 44 67 51 6A 52 66 6C 63 75 38 43 t/AOoDgQjRflcu8C0010: 70 55 79 43 70 55 79 43 70 55 79 3D pUyCpUyCpUy= |
疑似base64过的,拿标准base64解码后扫内存,发现没有这块数据,有可能不是标准码表.
1 2 | 00000000 b7 f0 0e a0 38 10 8d 17 e5 72 ef 02 a5 4c 82 a5 |·ð. 8...årï.¥L.¥|00000010 4c 82 a5 4c |L.¥L| |
所以直接跟踪原始的数据
1 2 | 0000: 74 2F 41 4F 6F 44 67 51 6A 52 66 6C 63 75 38 43 t/AOoDgQjRflcu8C0010: 70 55 79 43 70 55 79 43 70 55 79 3D pUyCpUyCpUy= |
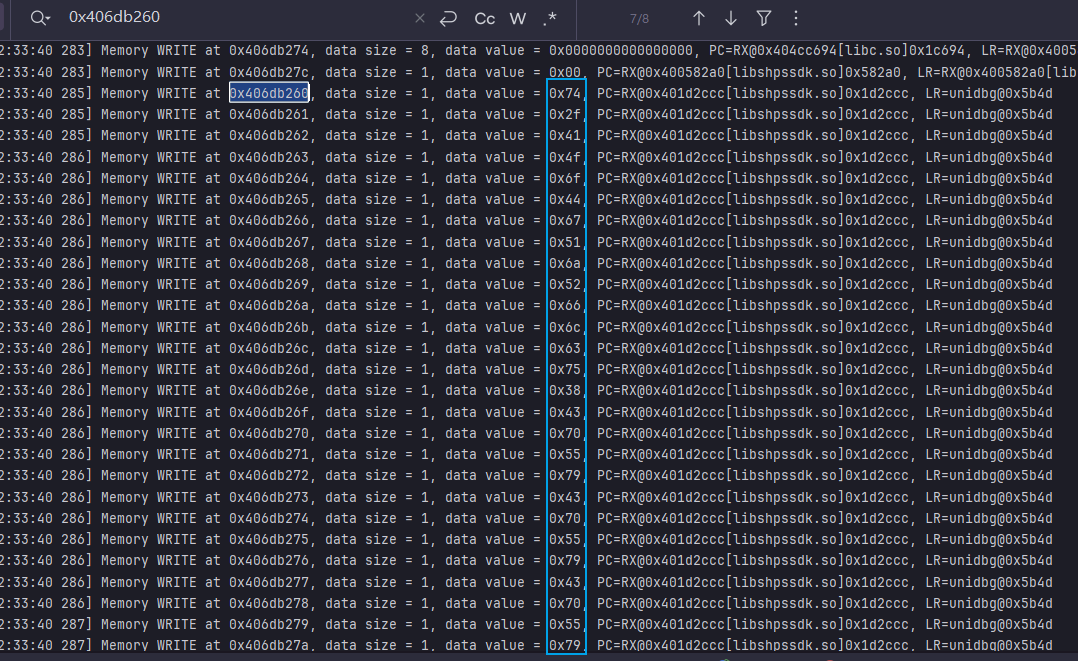
接着跟踪发现是从一块内存中取的
1 2 3 4 5 6 7 8 9 | m0x402dd8b0>-----------------------------------------------------------------------------<[19:09:28 238]RX@0x402dd8b0[libshpssdk.so]0x2dd8b0, md5=08cbad9d596ee8734f60c71851aeafc1, hex=73686f70456553484f504446544143476b72494a34354b4c424d2b4e51636452553156573839585977785a61626667696a6c6d6e74717576797a30322f333736d715000070540800351010002e141800676ba902d947004cb670200028003000e0743000380040003911480040005000size: 1120000: 73 68 6F 70 45 65 53 48 4F 50 44 46 54 41 43 47 shopEeSHOPDFTACG0010: 6B 72 49 4A 34 35 4B 4C 42 4D 2B 4E 51 63 64 52 krIJ45KLBM+NQcdR0020: 55 31 56 57 38 39 58 59 77 78 5A 61 62 66 67 69 U1VW89XYwxZabfgi0030: 6A 6C 6D 6E 74 71 75 76 79 7A 30 32 2F 33 37 36 jlmntquvyz02/376 |
所以这就是码表,而且开头也是app名字shopee,用这块码表解码出来
1 2 | 00000000 d3 c3 48 08 ab 9c c1 fb 71 77 69 0e 0e 0e 0e 0e |ÓÃH.«.Áûqwi.....|00000010 0e 0e 0e 0e |....| |
剩下的就简单了,两处异或,一处魔改一点的rc4
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | def getValue1(str1,randomStr): rc4Key = int.from_bytes(bytes.fromhex(randomStr[16:]),byteorder='little').to_bytes(8,byteorder='big') S = list(range(256)) j = 0 key_length = len(rc4Key) for i in range(256): j = (j + S[i] + rc4Key[i % key_length]) % 256 S[i], S[j] = S[j], S[i] # S盒编排 # print([hex(i) for i in S]) finalKey = [] i = j = 0 for m in range(12): i = (i + 1) % 256 j = (j + S[i]) % 256 S[i],S[j] = S[j],S[i] k = S[(S[i] + S[j]) % 256] finalKey.append(k) # print(bytearray(finalKey).hex()) # 后加密这段 randomStr = '03'+str1+randomStr arr1 = bytearray(bytes.fromhex(randomStr)) arr2 = bytearray(finalKey) table = [] for i in range(12): table.append(arr2[i]^arr1[i]) # 先加密这段 hexStr = bytearray(table).hex()+randomStr[24:] # 223fb3c4089995e37d132e08 + 08090a0b0c0d0e0f arr3 = bytearray(bytes.fromhex(hexStr)) tmp = arr3[0] resultArr = [0] for i in range(19): tmp = tmp ^ arr3[i+1] resultArr.append(tmp) resultArr[0] = tmp^arr3[0] res = custom_base64(bytearray(resultArr), mode="encode") return res |
输入参数1是第5次随机产生的4字节,比如03020109,03代表后续3个键,get后面有2个,post3个,但都是03开头,02,09,01代表执行哪几套算法.修改最开始赋值的位置即可影响函数执行流程从而找到这9套算法.
1 2 3 4 5 6 7 8 9 | // debugger.addBreakPoint(module.base+0x1C0A18); // 1号算法// debugger.addBreakPoint(module.base+0x8F608); // 2号算法// debugger.addBreakPoint(module.base+0x1C0E80); // 3号算法// debugger.addBreakPoint(module.base+0x1DD6A8); // 4号算法// debugger.addBreakPoint(module.base+0x1C104C); // 5号算法// debugger.addBreakPoint(module.base+0x1C1C34); // 6号算法// debugger.addBreakPoint(module.base+0x1C2018); // 7号算法// debugger.addBreakPoint(module.base+0x1C2038); // 8号算法// debugger.addBreakPoint(module.base+0x1C2380); // 9号算法 |
参数2是6第次随机的16字节
此算法只进行了异或和rc4类型操作,可以解密.如果最终结果有加法运算,并且相加的两个都不确定将无法解密,加法能解密必须满足其中一个是固定的,比如通过密钥编排算法算出来的.(减同理),&运算不可还原,|运算在循环移位是固定位的时候可以还原.
key2 key3 key4
key2 key3(对应post) key4(对应最长的) 3个键的输入都是一样的
输入:url.encode()+bytes.fromhex(randomStr[-10:])
1 2 3 4 5 | 1号 似乎是 murmurhash 的变体2号 wyhsah3号 lookup3或者(hashlittle)4号 xxhash后续的没看,采用的是纯汇编还原 |
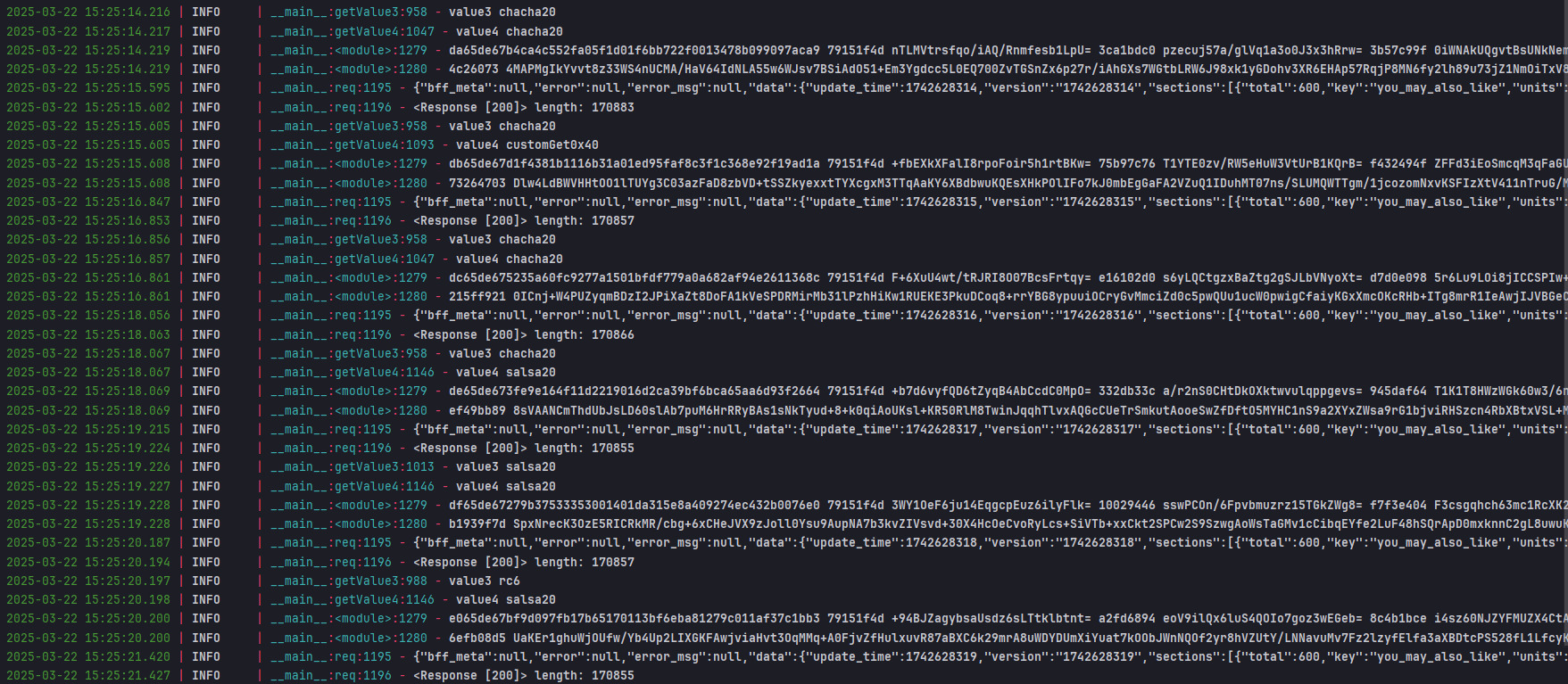
算法全部采用冷门的hash算法,包括后面的对称加密也采用冷门的rc6,chacha20,salsa20.
算法难度不大,但是全搞完需要花时间,因为这些算法几乎没有python库,所以得从网上找别的语言的,或者ai来写,也可以纯汇编级别还原,但是要考虑输入的长度,因为这些hash都没有填充,导致要根据输入的长度做适配,主要是这块复杂.
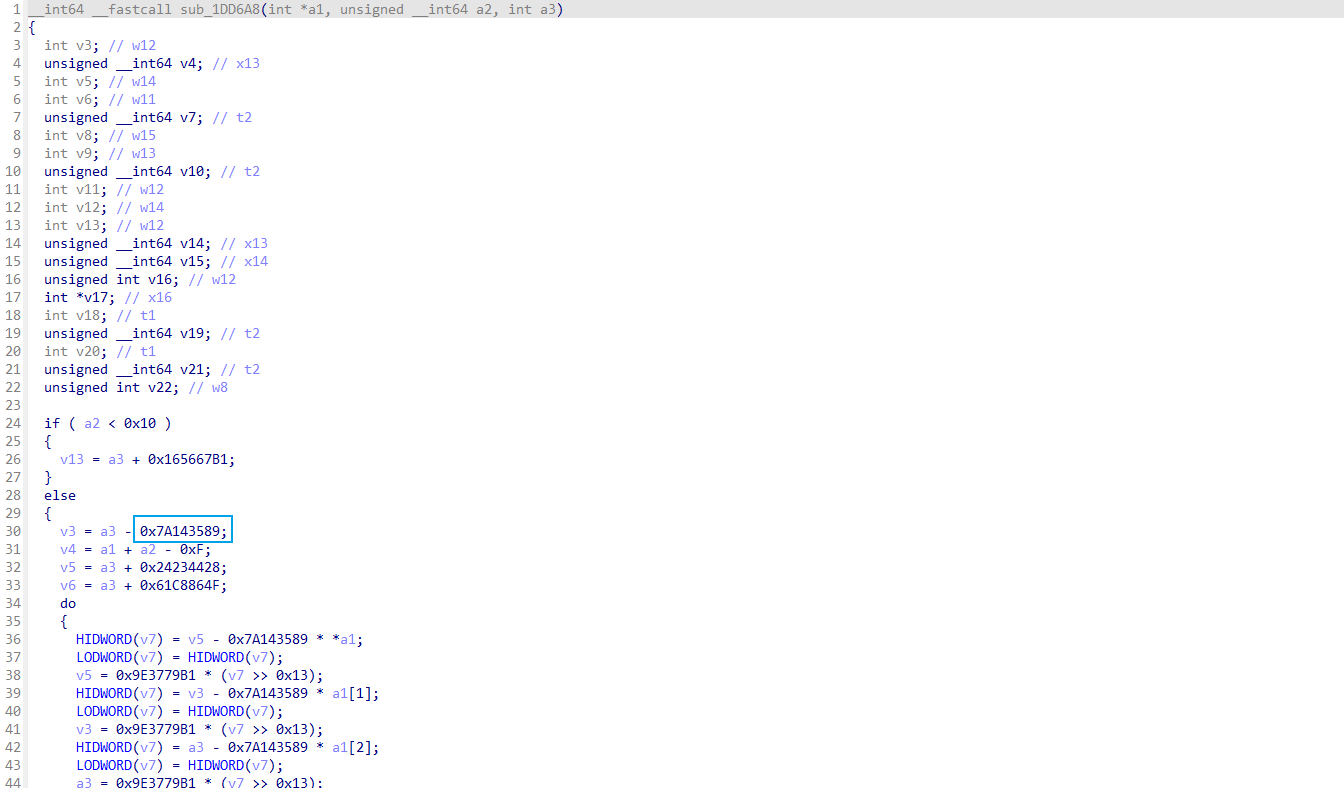
以4号 0x1DD6A8为例,图中有很多常量,直接搜常量即可大概确认使用的什么hash.
9套算法最好全部还原,才好进行后续的解密步骤,因为抓包中的可是随机的.
value2
FARrgVHXe45Pv0qTshBs+shpsSU= 首先解码
1 2 | 00000000 2c d7 d1 ba 21 e6 15 45 49 df ad 4c 00 16 00 68 |,×Ѻ!æ.EIß.L...h|00000010 00 43 00 68 |.C.h| |
观察可发现后8字节随机数和时间戳交替,其实这里时间戳还异或了随机数,因为是0所以看不出来,换别的随机即可发现.
所以需要前12字节,4字节一组搜索,找到最开的位置会找到一个常量0x61707865
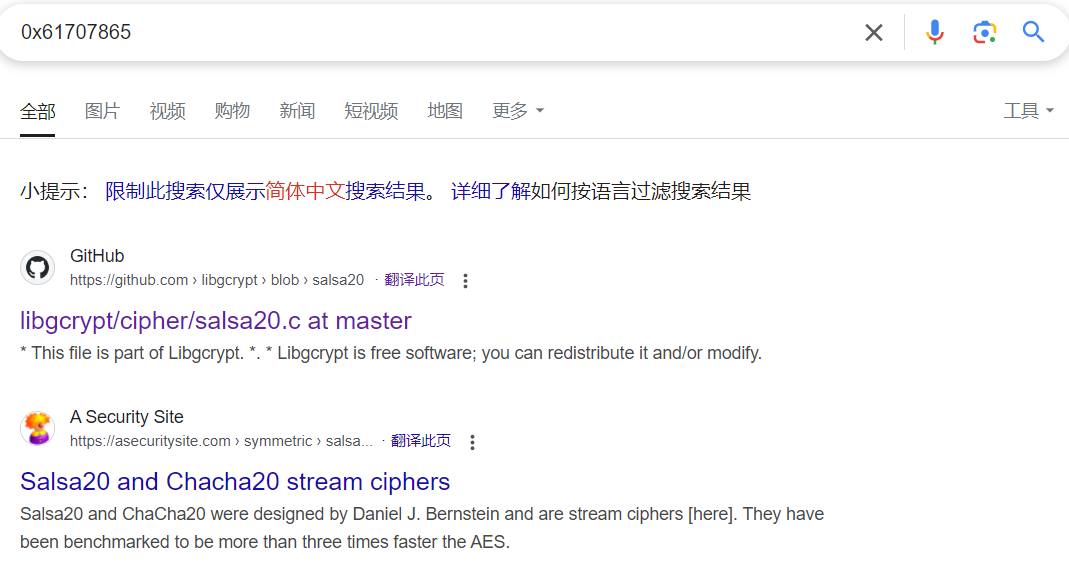
有两个共用的salsa20和chacha20,chacha20由salsa20改进而来.还有3个常量是0x3320646e, 0x79622d32, 0x6b206574
并且这其实是一个16字节字符串
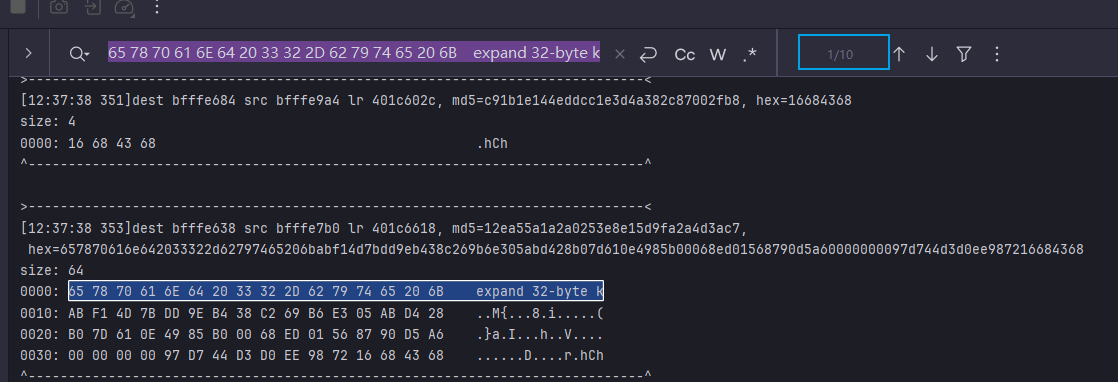
和前面10轮也对上了,其实是value2 1轮 value3 1轮 value4 8轮. value2只有一种算法,value3 3种,value4 种
下面是一份标准chacha20,可在cyberchef验证正确性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 | import structdef rotl(v, n): """对32位无符号整数 v 进行循环左移 n 位。""" return ((v << n) & 0xffffffff) | (v >> (32 - n))def quarter_round(x, a, b, c, d): """ ChaCha20 的四分轮函数,对状态数组 x 的 a, b, c, d 四个位置进行操作。 """ x[a] = (x[a] + x[b]) & 0xffffffff x[d] = rotl(x[d] ^ x[a], 16) x[c] = (x[c] + x[d]) & 0xffffffff x[b] = rotl(x[b] ^ x[c], 12) x[a] = (x[a] + x[b]) & 0xffffffff x[d] = rotl(x[d] ^ x[a], 8) x[c] = (x[c] + x[d]) & 0xffffffff x[b] = rotl(x[b] ^ x[c], 7)def chacha20_block(key, counter, nonce): """ 根据 key(32字节)、counter(32位整数)和 nonce(12字节)生成 64 字节的 ChaCha20 块。 该函数实现了 IETF 标准变体(即 nonce 长度为 12 字节)。 """ if len(key) != 32: raise ValueError("Key 必须为 32 字节") if len(nonce) != 12: raise ValueError("Nonce 必须为 12 字节") # ChaCha20 常量 "expand 32-byte k" constants = [0x61707865, 0x3320646e, 0x79622d32, 0x6b206574] key_words = list(struct.unpack("<8L", key)) nonce_words = list(struct.unpack("<3L", nonce)) # 构造初始状态,共16个32位整数 state = [0] * 16 state[0:4] = constants state[4:12] = key_words state[12] = counter & 0xffffffff state[13:16] = nonce_words working_state = state.copy() # 进行 20 轮运算(10 次双轮,每次包括列轮和对角线轮) for _ in range(10): # 列轮 quarter_round(working_state, 0, 4, 8, 12) quarter_round(working_state, 1, 5, 9, 13) quarter_round(working_state, 2, 6, 10, 14) quarter_round(working_state, 3, 7, 11, 15) # 对角线轮 quarter_round(working_state, 0, 5, 10, 15) quarter_round(working_state, 1, 6, 11, 12) quarter_round(working_state, 2, 7, 8, 13) quarter_round(working_state, 3, 4, 9, 14) # 最终将原始状态与运算结果相加 for i in range(16): working_state[i] = (working_state[i] + state[i]) & 0xffffffff # 将 16 个 32 位整数以小端序打包成 64 字节 return struct.pack("<16L", *working_state)def chacha20_encrypt(key, nonce, counter, plaintext): ciphertext = bytearray() # 每个块 64 字节,若明文长度不足 64 字节,则只使用部分 keystream block_count = (len(plaintext) + 63) // 64 for i in range(block_count): keystream = chacha20_block(key, counter + i, nonce) block = plaintext[i*64:(i+1)*64] # 异或运算 for j in range(len(block)): ciphertext.append(block[j] ^ keystream[j]) return bytes(ciphertext)if __name__ == '__main__': # 示例密钥(32字节)和 nonce(12字节) key = bytes.fromhex('0ead0c2e54a978e8b303ed242e6d313f253ea446bcbfc6f86d9809c09d191e22') nonce = bytes.fromhex('9565542946c322befc1dd567') counter = 0 # 随轮数递增 plaintext = bytes.fromhex('0000000001000200cdb87f28') print("明文:", plaintext.hex()) # 加密 ciphertext = chacha20_encrypt(key, nonce, counter, plaintext) print("密文 (hex):", ciphertext.hex()) # 解密:对密文再次使用同样的 keystream 异或即可还原明文 decrypted = chacha20_encrypt(key, nonce, counter, ciphertext) # print("解密后明文:", decrypted.hex()) |
chacha20属于对称加密里的流加密,即一个字节一个字节加密,所以名为流.
主要由密钥扩展和明文异或组成,明文好找,密文生成位置就是.密钥最快的方式就是找下面这一轮加的位置
1 2 3 | # 最终将原始状态与运算结果相加for i in range(16): working_state[i] = (working_state[i] + state[i]) & 0xffffffff |
前面扩展的时候有10*8*4=320个,也就是从320后续的加就能找到原始的密钥和nonce.
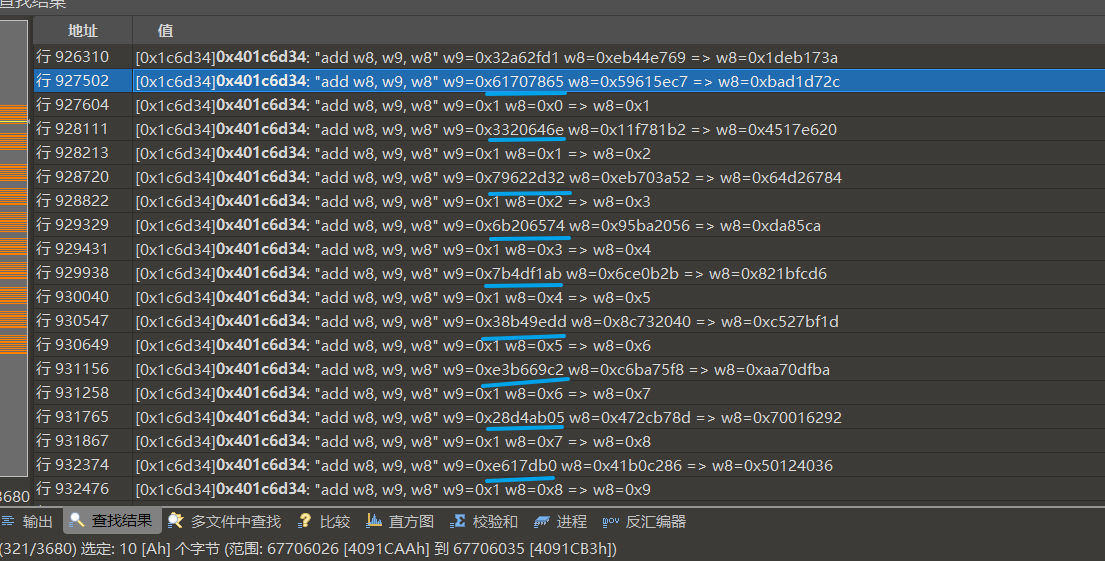
这样就一下找到key和nonce了.密钥不是固定的,是一组魔改sha256加密的url和随机数.
value3(post)
有chacha20(2) rc6(1) salsa20(0)三种.
通过url和随机数时间戳算一个hash值,然后逐字节相加再%3,这个hash算法是deadbeef.
value3和value2长度一样,aXUAj+4o++zMRgG/ZgW5Gksssss=
1 2 | 00000000 ae 68 0d c1 a5 02 69 ae 59 7e e3 fc aa e8 d5 3d |®h.Á¥.i®Y~ãüªèÕ=|00000010 00 00 00 00 |....| |
后4字节是第8次随机,前16字节的输入是00000000000000000000000000000000,一直都是.同chacha20往上找可以找到两个常量0xB7E15163,0x9E3779B9,rc5和rc6和都用的是这一组.之前拿标准rc5魔改出来还原的,后面才发现其实是标准rc6.
历史背景:rc6的诞生是为了评aes竞赛,但综合考虑性能和安全性Rijndael胜出,也就成了后面的aes.前5中常见的还有Twofish排第二,rc6排第四.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 | import struct# 常量定义WORD_SIZE = 32 # w = 32 bitsBLOCK_SIZE = 128 # 分组大小 = 128 位 = 4 * 32 位KEY_BYTES = 32 # 密钥长度 = 32 字节R = 20 # 轮数# 魔数 P 和 QP32 = 0xB7E15163Q32 = 0x9E3779B9# 循环左移和右移def rotl(x, y): return ((x << (y & 31)) & 0xFFFFFFFF) | (x >> (32 - (y & 31)))def rotr(x, y): return ((x >> (y & 31)) | (x << (32 - (y & 31)))) & 0xFFFFFFFFclass RC6: def __init__(self, key: bytes): self.w = WORD_SIZE self.r = R self.b = len(key) self.mod = 2 ** self.w self.key = key self.S = [] self._key_expansion() def _key_expansion(self): """RC6 密钥扩展""" # 密钥转为 c 个字 c = max(1, self.b // 4) L = [0] * c for i in range(self.b): L[i // 4] |= self.key[i] << (8 * (i % 4)) # 初始化 S 表 t = 2 * self.r + 4 self.S = [0] * t self.S[0] = P32 for i in range(1, t): self.S[i] = (self.S[i - 1] + Q32) & 0xFFFFFFFF # 混合 S 和 L i = j = 0 A = B = 0 n = 3 * max(t, c) for _ in range(n): A = self.S[i] = rotl((self.S[i] + A + B) & 0xFFFFFFFF, 3) B = L[j] = rotl((L[j] + A + B) & 0xFFFFFFFF, (A + B)) i = (i + 1) % t j = (j + 1) % c def encrypt_block(self, plaintext: bytes) -> bytes: """加密 128 位块""" A, B, C, D = struct.unpack('<4L', plaintext) B = (B + self.S[0]) & 0xFFFFFFFF D = (D + self.S[1]) & 0xFFFFFFFF for i in range(1, self.r + 1): t = rotl((B * (2 * B + 1)) & 0xFFFFFFFF, 5) u = rotl((D * (2 * D + 1)) & 0xFFFFFFFF, 5) t_mod = t & 0x1F # 低 5 位 u_mod = u & 0x1F A = (rotl((A ^ t), u_mod) + self.S[2 * i]) & 0xFFFFFFFF C = (rotl((C ^ u), t_mod) + self.S[2 * i + 1]) & 0xFFFFFFFF # 循环变量互换 A, B, C, D = B, C, D, A A = (A + self.S[2 * self.r + 2]) & 0xFFFFFFFF C = (C + self.S[2 * self.r + 3]) & 0xFFFFFFFF return struct.pack('<4L', A, B, C, D) def decrypt_block(self, ciphertext: bytes) -> bytes: """解密 128 位块""" A, B, C, D = struct.unpack('<4L', ciphertext) C = (C - self.S[2 * self.r + 3]) & 0xFFFFFFFF A = (A - self.S[2 * self.r + 2]) & 0xFFFFFFFF for i in range(self.r, 0, -1): # 反向循环变量互换 A, B, C, D = D, A, B, C t = rotl((B * (2 * B + 1)) & 0xFFFFFFFF, 5) u = rotl((D * (2 * D + 1)) & 0xFFFFFFFF, 5) t_mod = t & 0x1F u_mod = u & 0x1F C = rotr((C - self.S[2 * i + 1]) & 0xFFFFFFFF, t_mod) ^ u A = rotr((A - self.S[2 * i]) & 0xFFFFFFFF, u_mod) ^ t D = (D - self.S[1]) & 0xFFFFFFFF B = (B - self.S[0]) & 0xFFFFFFFF return struct.pack('<4L', A, B, C, D)if __name__ == '__main__': # 16 字节密钥 (128 位) key = b'5pC5QlE9zKWoSRBy' + bytes.fromhex('a3bde24bbb7c9d20 16684368 09090909'.replace(' ','')) # 128位密钥 rc6 = RC6(key) # 明文(128 位 = 16 字节) plaintext = bytes.fromhex('3C004C00 44004800 40003c00 40000000 '.replace(' ','')) # 8字节 print(f"原始明文: {plaintext}") # 加密 ciphertext = rc6.encrypt_block(plaintext) print(f"密文 (hex): {ciphertext.hex()}") # 解密 decrypted = rc6.decrypt_block(ciphertext) print(f"解密还原: {decrypted.hex()}") |
和上面说的方法类似匹配特征可以直接找到密钥.也是有魔改sha256结果和deadbeef组成.
value4(long)
4套算法,第7次随机的第一个字节%4
1 | chacha20(0) rc6(1) customGet0x40(2) salsa20(3) |
2号不是很好看出来,第一眼看过去甚至会以为是hash的结构.到最后没仔细看,反正加密没问题,解密不是很好写,毕竟一个快一千行的算法.
qqdWJdUhssssssssXewJFAT0Owe0phRy2c8HfdKEc4/NBgqiJreFbXOv8g8v8t/Rphpi/0JiY6A4DKjjWF0HrZ3Mp99zG2rHsR0pFzvWGeenxgnhYiNPoxyzCmLDL2Ocm3fJnLpmcY7Qy/To5Yyfk/1c1OKZB/qj+wchFXzmd133qlm0hwEpkjphkefsdh4Jzd702ONYyZRFtvbolq0lAqfWLk6zoGgEn+vGYbzirNK3QlWTLVt4vNe3Syfl/QExxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx1XOgfy4Nk1iX6EHpgOgBBlDnoKDygt05LxNkeIev9DQKfhIalMO9bEehaOEQI1rM2NNI7A/wCK3b/yRpWjx5GrEPkCU9ItDEYyGLf70ytMa7/ZaOkdarhjibGbhOPKrR0QrR9Z1B5OipKGovjg4an3dgqZu/i5rObK+kof7GF0ACysXhCTHdBcTCdZ61wPCfaJtU5+bo8az2ZFoFmEyir1a+kLFJwOWnusAurihdknWfibR+XrDbxn2OMv/hma2ZJA5mYM5VPfoSux/mBqu9o27jrJfsCo98mQOKuvQTRR9UPRdhcGf3D9gv58hb8zTXU1rFCC1TjkRz3UnekHM0tZJn2uj8YcayUp5G3vroVgQp4zK5+IST6IkxGEjnlHk=
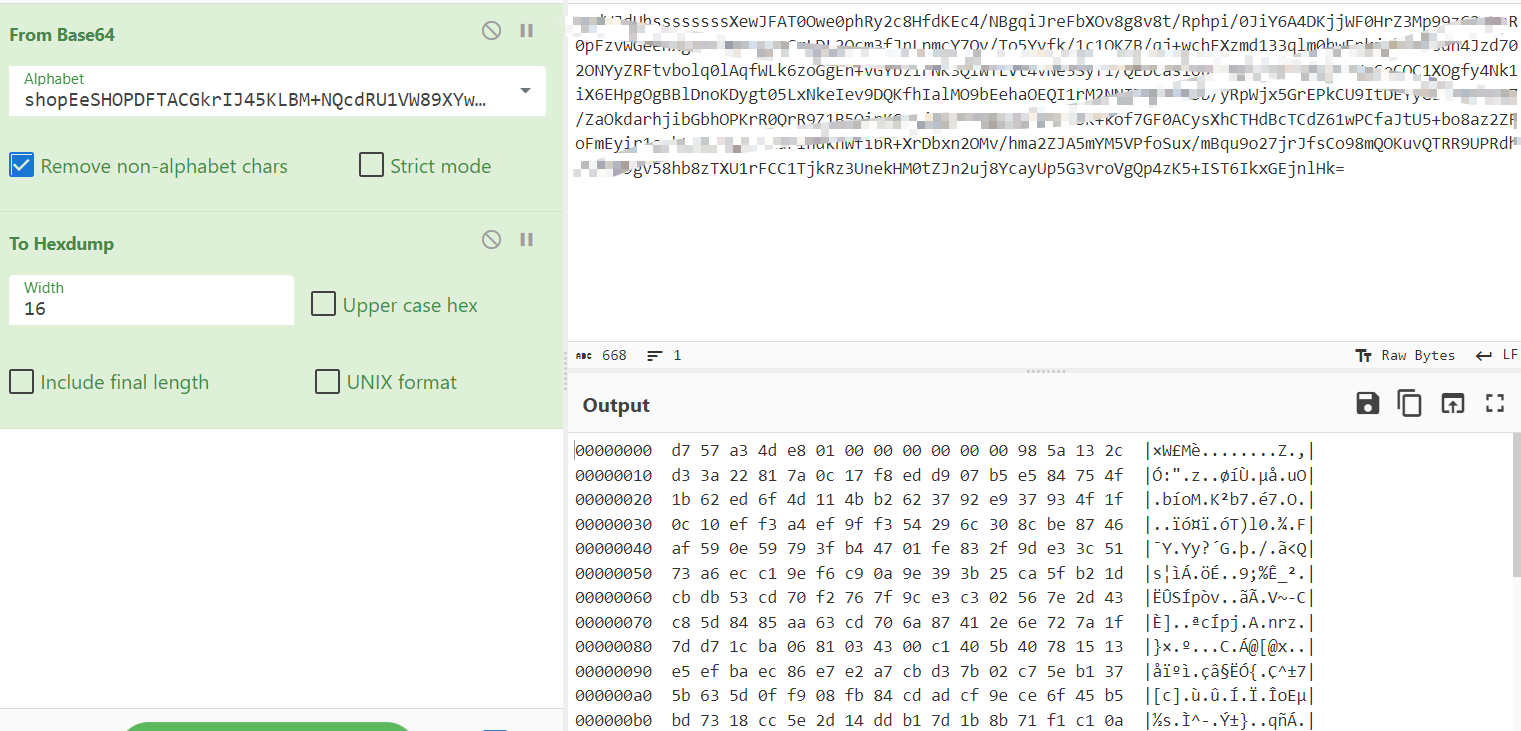
解码后前12字节和后面的是拆分开的,前4字节xxhash后面剩余的再异或时间戳,中间4字节,输入的长度e8010000,后面4字节00000000代表几号算法,比如3号就是03000000.后面的就是4种分组算法,上面说过了chacha20,rc6,这里说说salsa20和一个自定义的算法.
修改随机%4=1才能到rc6分支.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | import structdef rotl(x, n): """将32位无符号整数 x 循环左移 n 位""" return ((x << n) & 0xffffffff) | (x >> (32 - n))def quarterround(a, b, c, d): """Salsa20 的 quarter round 变换""" b ^= rotl((a + d) & 0xffffffff, 7) c ^= rotl((b + a) & 0xffffffff, 9) d ^= rotl((c + b) & 0xffffffff, 13) a ^= rotl((d + c) & 0xffffffff, 18) return a, b, c, ddef rowround(y): """对 16 个 32 位字(排列为 4x4 矩阵)进行 row round 变换""" z = y.copy() z[0], z[1], z[2], z[3] = quarterround(y[0], y[1], y[2], y[3]) z[5], z[6], z[7], z[4] = quarterround(y[5], y[6], y[7], y[4]) z[10], z[11], z[8], z[9] = quarterround(y[10], y[11], y[8], y[9]) z[15], z[12], z[13], z[14] = quarterround(y[15], y[12], y[13], y[14]) return zdef columnround(x): """对 16 个 32 位字(排列为 4x4 矩阵)进行 column round 变换""" y = x.copy() y[0], y[4], y[8], y[12] = quarterround(x[0], x[4], x[8], x[12]) y[5], y[9], y[13], y[1] = quarterround(x[5], x[9], x[13], x[1]) y[10], y[14], y[2], y[6] = quarterround(x[10], x[14], x[2], x[6]) y[15], y[3], y[7], y[11] = quarterround(x[15], x[3], x[7], x[11]) return ydef doubleround(x): """Salsa20 的 doubleround 变换(先 column round 后 row round)""" return rowround(columnround(x))def littleendian(b): """将4字节转为 32 位无符号整数(小端序)""" return struct.unpack('<I', b)[0]def littleendian_inv(w): """将 32 位无符号整数转换为 4 字节的小端表示""" return struct.pack('<I', w)def salsa20_block(key, nonce, block_counter): constants = b"expand 32-byte k" # 16 字节常量 if len(key) != 32: raise ValueError("Key 必须为 32 字节") if len(nonce) != 8: raise ValueError("Nonce 必须为 8 字节") # Salsa20 状态为 16 个 32 位字 state = [0] * 16 state[0] = littleendian(constants[0:4]) state[1] = littleendian(key[0:4]) state[2] = littleendian(key[4:8]) state[3] = littleendian(key[8:12]) state[4] = littleendian(key[12:16]) state[5] = littleendian(constants[4:8]) state[6] = littleendian(nonce[0:4]) state[7] = littleendian(nonce[4:8]) # 使用 64 位块计数器拆分为两个 32 位整数 state[8] = block_counter & 0xffffffff state[9] = (block_counter >> 32) & 0xffffffff state[10] = littleendian(constants[8:12]) state[11] = littleendian(key[16:20]) state[12] = littleendian(key[20:24]) state[13] = littleendian(key[24:28]) state[14] = littleendian(key[28:32]) state[15] = littleendian(constants[12:16]) working_state = state.copy() # 进行 20 轮变换(10 个 doubleround) for _ in range(10): working_state = doubleround(working_state) # 将原始状态与变换后的状态相加得到最终状态 result_state = [(working_state[i] + state[i]) & 0xffffffff for i in range(16)] block = b"".join(littleendian_inv(w) for w in result_state) return blockdef salsa20_encrypt(key, nonce, plaintext): ciphertext = bytearray() block_counter = 0 for i in range(0, len(plaintext), 64): keystream = salsa20_block(key, nonce, block_counter) block_counter += 1 chunk = plaintext[i:i+64] # 异或运算 ciphertext.extend(bytes(a ^ b for a, b in zip(chunk, keystream))) return bytes(ciphertext)# 示例if __name__ == "__main__": # 定义 32 字节的密钥和 8 字节的 nonce key = b'gkXKQn1X6TZ1OR49' +bytes.fromhex('bafd9ab40cd0cfcf69b1d6955c9c3181') # 32 字节 nonce = bytes.fromhex('e4e1390603030303') # 8 字节 plaintext = bytes.fromhex('400000003c004c0040003c0044004800') # 加密 ciphertext = salsa20_encrypt(key, nonce, plaintext) print("密文 (hex):", ciphertext.hex()) # 解密(对密文再次使用相同的 key 和 nonce 进行加密) decrypted = salsa20_encrypt(key, nonce, ciphertext) print("解密后:", decrypted) |
chacha20由salsa20改进而来,一开始当成魔改chacha20来做的,后来问了ai chacha20还有哪些变体才知道这个的.
最大的区别就是下面的
chacha20
1 2 3 4 5 6 7 8 | x[a] = (x[a] + x[b]) & 0xffffffffx[d] = rotl(x[d] ^ x[a], 16)x[c] = (x[c] + x[d]) & 0xffffffffx[b] = rotl(x[b] ^ x[c], 12)x[a] = (x[a] + x[b]) & 0xffffffffx[d] = rotl(x[d] ^ x[a], 8)x[c] = (x[c] + x[d]) & 0xffffffffx[b] = rotl(x[b] ^ x[c], 7) |
salsa20
1 2 3 4 | b ^= rotl((a + d) & 0xffffffff, 7)c ^= rotl((b + a) & 0xffffffff, 9)d ^= rotl((c + b) & 0xffffffff, 13)a ^= rotl((d + c) & 0xffffffff, 18) |
chacha20是异或的左移,salsa20是加的左移,而且位数也不一样.这里已经很明显了,直接看左移位数就可以判断.
剩余一个自定义的算法
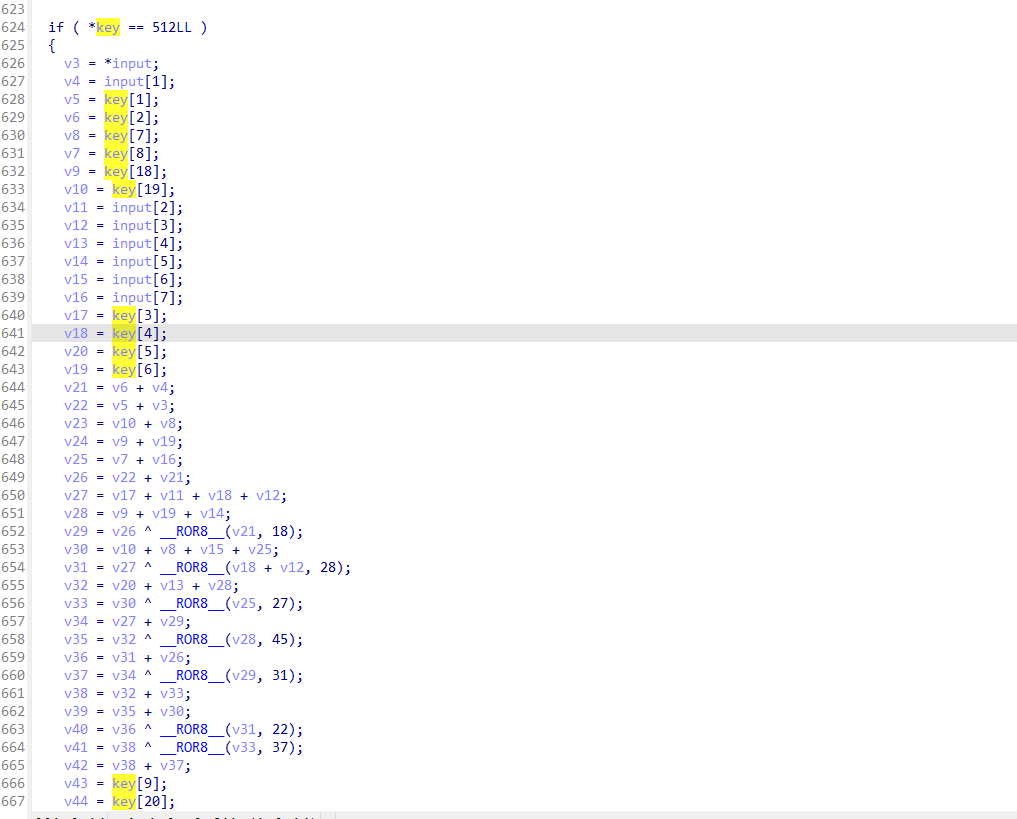
直接扣下来即可,就是解密不好写,不好解2号算法.
至于里面的指纹,有时候会发现真机长度特别长,达到1500多位,unidbg只有600多位
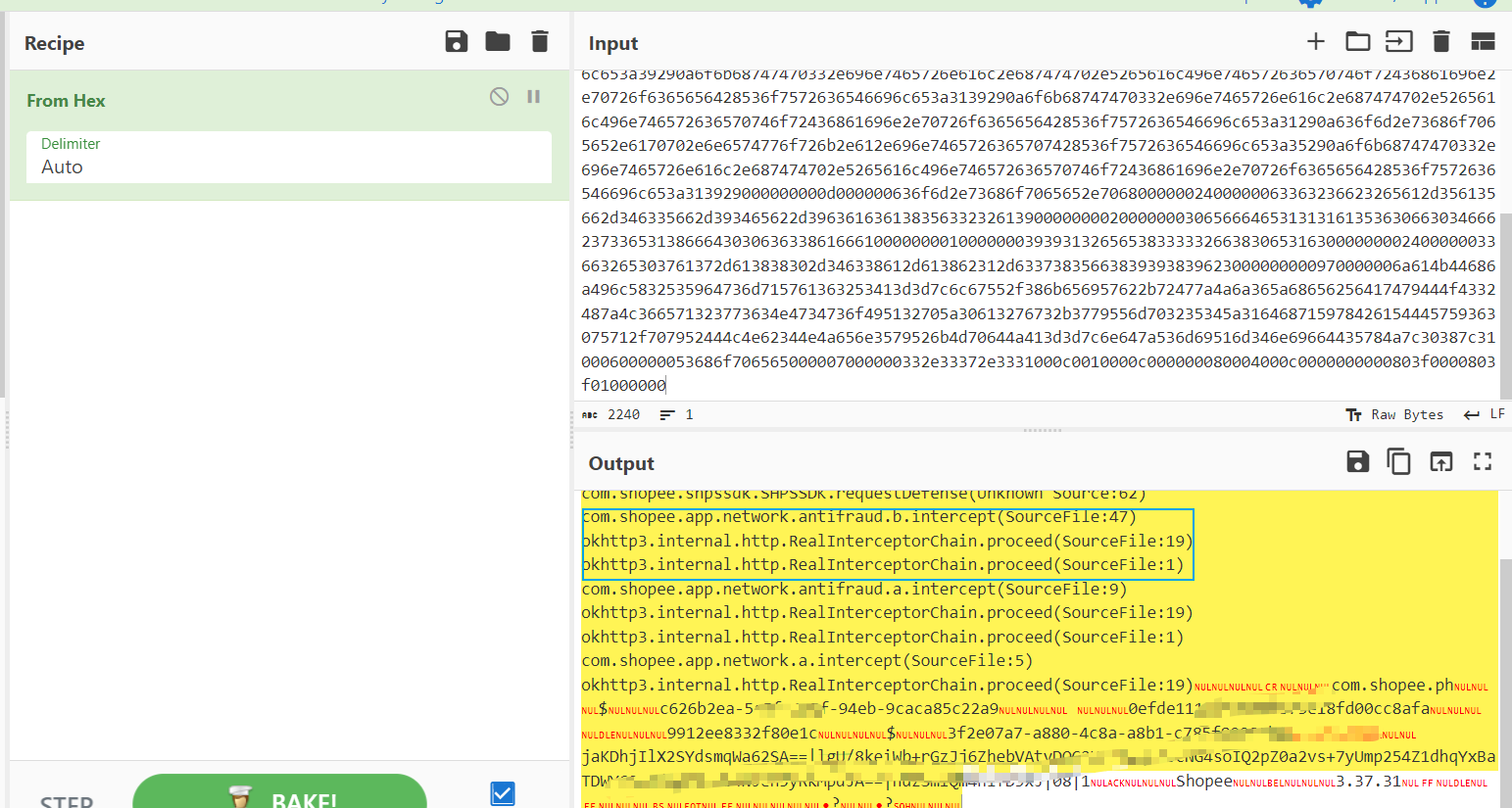
原因就是真机抓包的时候触发了异常堆栈,把一个特别长的堆栈加到里面了,导致长度很长,其他的和unidbg几乎一样.里面的主要是af-ac-enc-sz-token,来自headers,是设备id,也在同一个sdk生成.
总结
总体来说难度不大,和国内的区别最大就是全部用冷门算法,有vmp,但是代码膨胀的没国内的那么厉害,掌握好基本的算法分析基础和推理能力即可.
这个shopee不同国家不同版本算法几乎一样,但是ios不一样.
搜索详情接口都测试过,算法可用.如果x-sap-ri或者value1,value2不一样会直接418.
更多【Android安全-shopee app算法分析第二篇】相关视频教程:www.yxfzedu.com
相关文章推荐
- 软件逆向-自动化提取恶意文档中的shellcode - Android安全CTF对抗IOS安全
- 二进制漏洞-铁威马TerraMaster CVE-2022-24990&CVE-2022-24989漏洞分析报告 - Android安全CTF对抗IOS安全
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo) - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows内核提权漏洞CVE-2018-8120分析 - Android安全CTF对抗IOS安全
- CTF对抗-Hack-A-Sat 2020预选赛 beckley - Android安全CTF对抗IOS安全
- CTF对抗-]2022KCTF秋季赛 第十题 两袖清风 - Android安全CTF对抗IOS安全
- CTF对抗-kctf2022 秋季赛 第十题 两袖清风 wp - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 4 动态链接 - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 3 静态链接 - Android安全CTF对抗IOS安全
- CTF对抗-22年12月某春秋赛题-Random_花指令_Chacha20_RC4 - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 2 ELF文件格式 - Android安全CTF对抗IOS安全
- Pwn-从NCTF 2022 ezshellcode入门CTF PWN中的ptrace代码注入 - Android安全CTF对抗IOS安全
- 编程技术-开源一个自己写的简易的windows内核hook框架 - Android安全CTF对抗IOS安全
- 编程技术-拦截Windows关机消息 - Android安全CTF对抗IOS安全
- CTF对抗-KCTF2022秋季赛 第八题 商贸往来 题解 - Android安全CTF对抗IOS安全
- 软件逆向-分析某游戏驱动保护的学习历程 - Android安全CTF对抗IOS安全
- 软件逆向-Wibu Codemeter 7.3学习笔记——Codemeter API调用及通信协议 - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 1 编译原理 - Android安全CTF对抗IOS安全
- Android安全-ByteCTF2022 mobile系列 - Android安全CTF对抗IOS安全
- Pwn-HITCON2022-wtfshell详解 - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com