编程技术-神(精病)的一站式嵌入式入门教程(未完成,施工中)
推荐 原创【编程技术-神(精病)的一站式嵌入式入门教程(未完成,施工中)】此文章归类为:编程技术。
一、所谓嵌入式,就是把人嵌到墙里去的招式!
1.1 嵌入式的划分
简单的,实际的,出于实用性的,我们可以将嵌入式系统大致分为两个部分。
软件和硬件( ̄︶ ̄)↗ (认真讲废话)
以单片机与所需的外围器件搭建的电路部分,划分为硬件设计。
通过对单片机编程来实现我们需要的功能,划分为软件编程
1.2 嵌入式的知识体系
关于这篇教程大体会讲什么 AND 这本教程之外你可以自己去学什么——
建议扫一眼有个印象就得了,不要太去在意——更没必要在这个阶段把这些书全买回来研究。
这玩意就是个大概的“培养方案”或者说“目录大纲”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | mindmaproot [嵌入式] 嵌入式软件 数据结构与算法 计算机组成原理 软件工程 设计模式 项目管理与版本控制 C/C++语言编程 关系型数据库与SQL 网络开发与多线程 操作系统与交叉编译 嵌入式硬件 电路基础 模拟电路 数字电路 电路设计 CAD 工程制图/建模 硬件仿真 电路原理图/PCB绘制 FPGA 焊接 |
二、所谓单片机,就是用单刀把人片片解离的技击!
2.1 对 MCU 的基本理解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | mindmaproot [MCU] CPU 计算电路 指令集 时钟 晶振 分频 计数器 存储器 RAM ROM 引脚 基本功能 普通IO 功能复用 中断 外部中断 软中断 优先级 |
大体来说,对于一个什么都不会都不知道刚入门的嵌入式小白来说,理解这张图是刚好合适的——
如果你的右脑图像处理能力不足以解析这幅图的话(通常而言图像解析处理能力与右脑的发育程度有关),又或者你连这些名词都看不懂的话,可以阅读以下内容:
一个MCU的功能可以大概的分为五个模块,分别是 CPU、时钟、存储器、引脚和中断。
1.1.1 CPU
其中CPU部分负责核心的计算功能,根据输入指令的不同,能够接通不同的计算电路。
不同CPU的输入指令和计算电路的对照关系不同,例如某系列CPU的加法指令可能是00001000,但;另一系列CPU的加法指令却是00001011。
将每种 CPU 的输入指令和计算电路的对应关系整理成一个对照集,就是所谓的指令集。
1.1.2 时钟
MCU 的运行需要一个稳定均匀的在高低电平之间反转的输入,以便对齐多个线路各种操作的时间,这个原件焦作晶振。
有的 MCU 在芯片内内置了晶振,有的MCU需要在外部电路中提供晶振。
通过计算检测的高低电平次数,我们可以实现定时与计数,这种电路叫“定时器/计数器”
有些时候晶振产生的频率并不适合我们的实际需要,我们可以通过分频(降低频率)与倍频(增高频率)等方式来调整时钟输入的翻转频率
1.1.3 存储器
字面意思,用来存储内容的
1.1.4 中断
中断是指计算机运行过程中,出现某些意外情况需主机干预时,机器能自动停止正在运行的程序并转入处理新情况的程序,处理完毕后又返回原被暂停的程序继续运行。
直接念定义的话可能不太好理解。
乃们可以这么想,事有轻重缓急——当你正在慢慢悠悠看小说,突然闻到锅糊了,这时候你得停止看小说,先跑去把火关上才能回来继续看。
而中断的优先级,就是重要的事情也分轻重缓急,你正在看小说,锅糊了,同时跳闸了。
你肯定得先把锅关了,再去合电闸。
1.1.5 引脚
嵌入式开发中最直观要控制的东西,芯片的管脚。
基本的功能管脚、例如电源管脚 VCC、GND,重置管脚 RST 等是确定的我们不能修改的。
普通的IO管脚是我们可以用来读取上面的电压或者设置上面的电压,用于做输入输出的。
有一些常用的功能,直接用软件实现又麻烦运行效率又差,因此设计成了专门的电路并连接到部分IO管脚上,只要在编程时设置这些引脚的运行模式,就能使用这些预先设计好的功能,这叫引脚的功能复用。
三、将人的肌肉纤维一根根抽出,重新织造成强韧的材料,谓之编程!
3.1 环境搭建
3.2 基本的 C 语言编程
3.1.1 编程重要的是思维而不是语法
在开始学习编程之前,首先我们要先明确一件事,就是学编程重要的是思维而不是语法。
语言只是工具,思维才是本质。
工具只是便捷你的工作与提高你的效率,但真正决定你能否解决问题的是你的思维方式.
就好比做几何题的时候,垂直平行等那套数学符号语言(工具)真的重要吗?
那只是一种表述方式而已,不会那套数学符号还可以写文字描述和算式。
决定你最终能否解答这道题的还是你是否有解题的思路。
编程也是如此。
3.1.2 模块化概念
在编程学习开始之前,我们还需要了解一个概念,就是模块化。
c语言是一个模块化的语言,这个模块化体现在很多方面,比如函数,比如结构体,比如多文件。
一个c语言程序,就是由一个个变量拼成结构体,一个个结构体与函数拼成文件,最后再由一个个文件拼成最后的整个程序
任何一个C语言程序都是由一个或者多个程序段构成,每个程序段分别负责各自的功能,最后由主程序段统合到一起形成可以执行的程序。 ——这种负责某一部分功能的程序段我们通常称之为“函数”。
3.1.3 主函数
电脑计算机执行程序总要有个开始,总要有个第一行。
前面提到过c语言中每个程序段分别负责各自的功能,那么计算机执行的时候又怎么能知道先执行哪里后执行哪里呢?
为了解决这一问题,我们需要有一段程序来做各个程序段的统合
这个程序也就是main函数
也就是说,如果你写的程序要运行的话,一定要有一个main函数
那么main函数如何写呢?
为了解决这一问题,我们需要了解一下函数的结构。
3.1.4 函数的结构
前面提到,一个c语言程序,就是由一个个变量拼成结构体,一个个结构体与函数拼成文件,最后再由一个个文件拼成最后的整个程序。
那么函数是怎么样的呢?这里我们以不可或缺的主函数为例
1 2 3 4 | void main(){ //代码内容 } |
这就是一个最简化的函数(当然我们通常不用void,这里只是为了方便理解)
这个函数的结构是这样的
1 2 3 4 | void main() // 返回值类型 函数名(参数列表) 表示创建一个函数 { //代码块开始 //代码块可以简单理解为我们要运行的一段代码 } //代码块结束 |
这里的void是指返回值的类型,void表示没有返回值,为什么函数需要返回值呢?因为我们在执行一个函数的时候通常是需要它来实现某个功能的,如果没有返回值我们就不知道它有没有成功执行,或者不知道它的执行结果了(譬如执行开平方以后我们没有收到返回值,平方是开完了,但是结果捏?????)
而且有些时候我们的系统在执行函数的时候也强制要求返回值(一些系统,不是所有系统)
综上,我们的程序最好提供一个返回值
因此在事实上我们的一个函数表达出来其实是这样的
1 2 3 4 | 类型名 main(){ //函数内容 return 数值;} |
这里的类型名常用的有 int char double long short float bool
分别对应为整数,字符,双精度浮点数,长数,短数,浮点数,浮点数就是带小数点的数,计算机处理浮点数有误差,double比float精准一些
这里我们所写的函数名字叫main,也就是前文提到的主函数
由于是主函数,所以我们的返回值自己是没有办法用到了,但是有的计算机系统可能会要求,因此通常的写法是返回一个0,代表程序正确执行完成,此时我们的程序就变成了
1 2 3 4 5 | int main() //创建一个返回值为整数的函数 名为main 传入参数列表为空{ //函数内容 return 0; // 返回整数 0 } |
这里我们运行一下这个程序给大家看看结果
(展示)因为我们函数内容什么都没有写,所以也什么都没有显示
那么怎么证明我们的程序真的执行成功了呢?我们再增加一行用于显示的指令
1 2 3 4 5 6 7 | #include <stdio.h>int main() //创建一个返回值为整数的函数 名为main 传入参数列表为空{ printf("hello world");//显示hello world return 0; // 返回整数 0 } |
注意!C语言函数里的语句结束后需要以英文分号结尾,每一句都需要
printf是c语言里的打印(显示到屏幕)语句,这句话的意思是显示hello world
加上之后我们再来运行一下(展示)程序就会显示输出hello world
加上以后我们的命令后就显示出了我们要显示的内容,这证明本喵刚才认真讲了没有胡说八道(骄傲)
可能刚才有银还意识到一个问题,就是刚才的程序比上面说的多了一行
1 | #include <stdio.h> |
这一句的意思又是什么呢?
#后面加的字符是c语言里的预处理指令,就是编译器程序执行前预先处理的指令,用来补足程序运行中需要的一些东西
这个#include就是包含头文件的意思
#include <stdio,h>
的意思就是这个程序要包含文件stdio.h里面的内容,stdio.h是c语言编译器自带的一个头文件,包含了输入输出的函数之类的一些常用的功能函数,printf()其实也是一个函数,它在stdio文件里面,我们使用的printf就是调用了程序外部文件stdio.h里面的print函数。
3.1.5 多函数
刚才咱们已经说了,c语言由很多函数构成,下面咱们再定义一下别的函数来个多函数的程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #include int die(){ printf(" bay~ world " ); return 0;}int main(){ die(); return 0;} |
由于这个不是主函数了所以函数名就可以自己起了,不过这里要注意,函数名不能和关键字(c语言里面已经被占用的词)同名
这里我们起名die
这里左下角就正确显示了
这里是先定义了die函数然后在主函数里面调用了它
1 | die(); |
就酱,我们写了一个多个函数的c语言程序,(在学习编程的初期可以先不用考虑多文件,先从一个文件写起)
这里要注意!我们使用的程序要在使用的地方之前出现,例如dnlm函数在main函数之前
如果因为某些原因一定要写在使用地方后面的话,要在使用之前声明 extern 函数名
3.1.6 选择分支
然后下面我们讲一坨选择分支结构
这个选择分支结构它是这个样子的
1 2 3 4 5 6 7 8 | if(){ //如果条件成立执行}else{ //如果条件不成立执行} |
这里我们添加一个丢乃老父并且声明母亲父亲两个整数来测试一下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #include int dnlm(){ int a=30;//声明整数a等于30 int b=20; //声明整数b等于20 if a>b) //如果a大于b { printf(" a" ); //显示 } else //否则 { printf(" b" ); //显示 } return 0;}int main(){ dnlm(); return 0;} |
运行结果正确的显示为a。
这样一来证明我们的选择结构发挥了它应有的效果
3.1.7 循环结构
首先是while循环,这是平常会经常用到的一个循环
1 | while(循环条件){ //代码内容} |
while循环的结构是这样的,首先判断循环条件是不是成立,例如循环条件是变量a>=2,那么当a大于等于2的时候,就会执行代码内容一次,然后再次判断a是不是还大于等于2,如果是的话再执行一次。直到有一次发现a不再大于等于2了,才结束循环开始执行循环外面的内容。这样一来的话,实际上也就是说,我们在写这种循环的时候,里面一定要写改变循环条件的代码,否则循环条件一直不变就变成死循环了。
while循环是先判断然后才决定执不执行的,所以while循环最少会执行0次,也就是说如果一开始条件就不成立的话就一次都不执行。
与之相对的是do。。。while循环
1 2 3 4 | do{//代码内容}while() |
do。。。while和while相反,dowhile是先做了再说,做一遍到做完以后再判断,是不是条件成立 ,条件成立的话继续循环,条件不成立的话到此为止,继续往下执行,do while循环是至少会执行一次的循环。
与while系列循环用的同样多的就是for循环了
1 | for(i=100;i>=0;i--){ //代码内容} |
for循环的条件分为三部分,第一部分是声明控制循环的变量,比如声明个i=100,第二个部分和while的控制条件一样是用来判断循环执不执行,最后一个部分是用来声明控制变量的变化,就和while一样,for也需要改变控制条件来防止死循环,不过for直接在控制条件里就可以写好改变控制变量的语句。
以上是循环结构的三种语句。
3.1.8 跳转语句
下面进行跳转语句
c语言里的跳转语句其实就是goto
语法也很简单,在任意一个地方立下flag,然后就可以随时goto到这个地方了
1 2 3 | lable1: //此处省略两百万亿行goto lable1 |
就可以直接飞回flag
goto用的好的话不仅可以跳转还可以实现各种循环,不过goto很容易出现不知道飞到了哪里去但是编译器不报错导致查错人员头比地球还大的现象,因此一般的来说,不建议使用goto语句。
3.1.9 数组
数组部分也很简单,其实就是把数据连起来存
我们平常声明一个变量a,可以储存一个数据。
我们现在声明一个数组a[100],就可以储存100个数据
1 | 数据类型 数组名[数组长度] |
可以通过a[0-99]来分别使用这100个数据,就不用写100遍声明变量了,而且如果我们要查找的数有好几个特点,还可以使用二维或者多维数组。
比如a[1][2][3][4][5][6][7]就是七维数组里第二组的第三小组的第四小组的第五小组的第六小组的第七小组的第八个数
这里要注意<font color=red>数组里面排序序号是从零开始的,第一个内容的编号是0,所以数组名加数字实际访问到位置是数字加一的位置存的数据。</font>例如a[0]其实是数组a的第一位。
从本质上而言,数组其实就是一种指针的应用方式。
![[Pasted image 20251011091711.png]]
3.1.10 指针
语言里面指针是核心精髓所在,所谓指针,就是指向数据储存的地方。
我们平常声明一个变量,a=100,大概就相当于在白纸上划了一部分叫做a区,然后往里面记录了一个数字100,100写在a这个地方。
这块a区所在的位置就叫做a的地址
c语言里面和地址有关的有两个符号,一个是&,取地址符,一个是*,是指针的标记(也是解引用符号)
我们平常创建变量的时候是这样的
1 | int a; |
我们创建指针变量时候是这样的
1 | int* p; |
标上一个*
表示这个变量p存储的是int变量的地址。
注意:指针和指针变量是不同的 !指针是地址,指针变量是存放指针的变量
我们平常给变量赋值的方法是这样的
1 | a=100; |
我们给指针变量赋值的时候是这样的
1 | p=&a; |
这里的&a的意思就是取得a的地址
看到这里大家可能会有所疑惑,这个指针和变量到底有什么区别呢?
这里举一个简单的例子来说明指针和直接调用变量的区别
坐在隔壁的小明想要抄你的试卷,他看了一下a区,把数字抄走了,这是b=a,
坐在隔壁的小明,他拿走了你的试卷,这是b=&a
前者只是拿走了数据,后者拿走的数据的地址,那么这会导致什么呢?
当小明(b)想要修改卷子的时候——
前者,b修改了卷子上的数值,a的卷子没事,因为b只是修改了抄走的一个数据
后者,b修改了卷子上的数值,a惊叫一声:卧槽你把我卷子改了干啥!!!
这就是使用变量的值和使用变量的指针的区别
BUT!!!为什么我们需要使用指针呢????
当然是因为**<font color=red>有些时候我们必须使用指针!</font>**
举个例子!比如我们想要在某个函数里修改函数外的值的时候,我们就必须得使用指针。
这里我们需要涉及一点关于函数调用、形参与实参的知识。
有些时候我们要用的函数会需要传入一些数值,比如我们写一个求和的函数
1 2 3 4 | int sum(int a,int b) //声明一个返回值是整数的函数,使用时需要传入整数a和整数b{ return a+b; //返回a+b的值} |
然后我们在使用的时候就需要传入两个值
1 2 | sum(x,y) //x和y是之前已经弄好的存了值的变量sum(10,20)//或者这样直接给两个数值 |
这里面的a和b就叫形参,也可以简单粗略地理解为参数所需的形式,x和y就是实参,可以简单粗略的理解为实际传入的参数。
在程序运行到调用sum函数的时候就会创建两个临时的变量a和b,然后把x和y的值传给a和b。
这里就出现了不使用指针无法解决的问题——如果我们想要把存储的结果还存在x里呢?
当然,这样其实还能解决,x=sum(x,y)就行了,但是如果我们要存到的地方不确定呢?比如根据sum计算结果的不同存到不同的地方,是不是没有办法啦!
而使用指针就可以很方便(才怪)的解决这个问题,我们不传入值,而是把地址传过去,小明不久可以直接修改你的试卷了吗?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #include <stdio.h>int main(int argc, char const *argv[]){ int x=1; int y=2; sum (&x,&y); return 0;}int sum(int* a,int* b){ *a=*a+*b; return 0;} |
这样就完美的解决了这个问题。
那么这里出一道小题,如果想要修改指针变量int* a的值应该怎么办呢?
1 2 3 4 5 | int sum(int** a,int** b){ *a=*a+*b; return 0;} |
当然是传入指针的指针!
指针是可以一层套一层的,int************************************************ a都可以!(当然,没什么大病的话一般是不会写太多层的)
回到刚才,讲指针的时候我们有说数组是指针的一种应用,是什么意思呢?现在我们就可以解答这个问题了,数组就是根据你的需求创建了好多挨在一起的空间,然后数组的名字就是一个指针,指向第一块地方,然后数组[]里跟不同的数字就是把指针往后移不同的长度,指到不同的地方。
比如a[3],其实也就是*(a+3)的意思,你把a[3]写成*(a+3),*(3+a),3[a]都可以的,都是一样的东西。
这里也解答了为什么数组前面要加int double之类的类型的问题,因为声明数组的时候需要创建出一些地方来存数据,不同类型数据大小不一眼需要的空间也不一样,数组前面的数据类型是用来标识每一块地方多大的。
3.1.11 结构体
众所周不知!(知道的话你们也不会在这里听了~)所谓结构体,就是简略版的类。
那么类是什么呢?与这一节无关,我们先跳过(bushi)
所谓结构,就是把多个零件拿来摆在一起。
例如我们把一个整数,两个字符串,一个小数,两个函数指针放在一起,就可以用来概括一个用户的基本信息(用户id,用户姓名,用户身份证号,用户信誉指数,访问处理函数,用户状态反馈函数)这就是一个用户结构。
我们按C语言要求的语法格式把它写出来
1 2 3 4 5 6 7 8 9 | struct User{ int id; string name; string idCardNumber; float be; int (*editmine)(); int (*getuserstate)();} |
这就是一个结构体。
我们就可以通过
1 2 3 | struct User user1 //按照结构体User创建user1user1.id=114514; //通过点运算符访问user1具有的成员变量......(略) |
的方式来简单的描述一个用户
如果嫌弃struct User太长,还可以用typedef给它起个小名。
1 | typedef struct User User //定义类型struct User为User |
这样就可以直接用User创建用户了
1 2 3 | User user1;user1.id=10086;...... |
3.2 从软件编程-->到嵌入式编程
3.2.1 电平与变量的值
现在你已经掌握了最基本的C语言编程,如何将软件代码与硬件电路结合起来呢?
首先引入两个概念
- 电流从高电平流向低电平。
- 数字电路里高电平是1,低电平是0。
然后导入一个理解
3. 单片机的IO引脚可以像变量一样操作。
那么,假设一个灯连接在Pin1和Pin2两个引脚之间,我们该如何让它亮起来呢?
look:
1 2 3 4 5 | while() //让单片机跑一个死循环防止程序结束{ Pin1=1; //点亮灯泡 Pin2=0; //根据不同MCU提供的库不同,具体语法会有所不同} |
这就是最简单的单片机编程。
3.2.2 时钟频率与延时
计算机的本质其实也就是基于数字电路,数字电路中各种触发器或者集成芯片都需要一个clk输入,这个输入是均匀的方波,(大概就是01010101.......这样)
一个数字电路系统中可能有很多个模块,例如好几个触发器要在合适的时候锁定,电路状态是会变化的,怎么告知触发器什么时候合锁定呢?
CLK:我特马来辣!
把各个触发器都设计成当检测到clk电压0变1的时候锁定,就能避免电路的不同部分输出有先有后导致数据出错了。
通过时钟信号,整个完整的电路才能稳定的按照正确的时序,正确的执行输入指令。
这个clk通常由一个名为晶振的元器件生成。
俗称晶振。
晶振每秒产生方波的数量叫做时钟频率。
然后,每条指令执行时间不一定是相同的,有得指令可能需要两个方波,有的可能需要三个、四个,这个叫指令周期(这些术语在开发里其实没啥大用,理解有这么个东西就行没必要费时间记)
知道时钟频率和指令周期之后,我们就可以据此来实现所需时长的延时了
例如以8051单片机为例,时钟频率12MHZ,while空转的指令周期是6x2,要延时20ms,就可以写成这样
1 2 3 4 5 6 7 8 9 10 11 | void Delay20ms(void) //@12.000MHz{ unsigned char data i, j; i = 39; j = 230; do { while (--j); } while (--i);} |
(什么?你问我39和230是怎么计算出来的?我有病吗自己算这玩意。直接拿芯片官方给的工具生成不就完了-->stc-aicube-isp)
3.2.3 中断与优先级
前文讲过了,中断就类似你看书看半截闻到糊味,就得先去关火。
优先级就是这些突发情况之间也分比较严重和特别严重,要优先处理最严重的。
具体实现上。。。。就是按要求编写中断后的处理函数
中断的优先级根据不同MCU或者开发环境也会有所不同。
例如Arduino的中断优先级如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | 1 Reset 2 External Interrupt Request 0 (pin D2) (INT0_vect) 3 External Interrupt Request 1 (pin D3) (INT1_vect) 4 Pin Change Interrupt Request 0 (pins D8 to D13) (PCINT0_vect) 5 Pin Change Interrupt Request 1 (pins A0 to A5) (PCINT1_vect) 6 Pin Change Interrupt Request 2 (pins D0 to D7) (PCINT2_vect) 7 Watchdog Time-out Interrupt (WDT_vect) 8 Timer/Counter2 Compare Match A (TIMER2_COMPA_vect) 9 Timer/Counter2 Compare Match B (TIMER2_COMPB_vect) 10 Timer/Counter2 Overflow (TIMER2_OVF_vect) 11 Timer/Counter1 Capture Event (TIMER1_CAPT_vect) 12 Timer/Counter1 Compare Match A (TIMER1_COMPA_vect) 13 Timer/Counter1 Compare Match B (TIMER1_COMPB_vect) 14 Timer/Counter1 Overflow (TIMER1_OVF_vect) 15 Timer/Counter0 Compare Match A (TIMER0_COMPA_vect) 16 Timer/Counter0 Compare Match B (TIMER0_COMPB_vect) 17 Timer/Counter0 Overflow (TIMER0_OVF_vect) 18 SPI Serial Transfer Complete (SPI_STC_vect) 19 USART Rx Complete (USART_RX_vect) 20 USART, Data Register Empty (USART_UDRE_vect) 21 USART, Tx Complete (USART_TX_vect) 22 ADC Conversion Complete (ADC_vect) 23 EEPROM Ready (EE_READY_vect) 24 Analog Comparator (ANALOG_COMP_vect) 25 2-wire Serial Interface (I2C) (TWI_vect) 26 Store Program Memory Ready (SPM_READY_vect) |
(谁要是浪费时间记这玩意,我能笑他一年)
3.2.4 Read the fucking manual !
翻译成中文是:去读他喵的文档
嵌入式开发的本质是阅读电路与文档的能力。基本的概念说完了,还需要我讲什么?
带着你遍历一遍全天下所有的单片机所有的总线协议所有的指令集吗?
入门所必需的理论知识就这么多,该实践了mybro~
你当然可以背的下某几款MCU的全部引脚定义和全部寄存器,努努力你甚至能背的下一个系列——但你能背的下所有系列所有型号吗?
你当然可以找到并记住几个常用通用传感器的(被简化后的)代码控制逻辑——你能记得住所有的传感器吗?那些市面上还没有人总结过的新型号传感器怎么办?
例如当你费劲千辛万苦学会了STM32F103C8AT6MCU+带驱动板双PWM电机的开发。然后发现任务需求是在GD32F407VET6上驱动四相五线步进电机。你就不干了吗?还是说打个报告“这个MCU和传感器我没有学习过,请给我批几个月假期去学习一下”?
<猫猫叹气>
何必呢?
所以说就嵌入式开发的学习来说,在单一MCU或模块的基本功能上耗费太多时间其实是没有什么必要的。其实学习嵌入式真正要学习的东西是阅读电路和阅读手册文档的能力啊。
引脚分布图datasheet上不是有吗?
寄存器定义对应MCU的手册上不是有吗?
传感器和功能模块、通信协议的原理逻辑和控制时序对应的资料手册上不是也有吗?
甚至商家还会给你带基本的驱动库和例程。
如果你有足够的阅读电路和阅读手册文档的能力,只要GET一本MCU手册,GET所需的模块手册,其实即使是完全陌生的MCU和模块也可以直接上手使用,不是吗?
3.2.5 最基本的嵌入式编程实践
以下,是一些 IDE 和 MCU 的电灯代码——别误会,我不是说真的要你们一上来就学习这么多IDE和这么多MCU,更不是说某些IDE固定只能开发对应MCU.
<font color=red>我列举这么多种的目的是在于清清楚楚的明示你:尽管有这么多种 IDE 和不同的 MCU ,但在编程上,除了不同芯片的头文件和函数命名不同外,它们的实现逻辑都完全一样!</font>
3.2.5.1 Keil-MDK uvision + STC89C52RC REG51定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | #include <reg52.h>// 简单延时函数void Delay_ms(unsigned int ms) { unsigned int i, j; for (i = 0; i < ms; i++) { for (j = 0; j < 120; j++); // 大约 1ms @ 12MHz }}void main(void) { // 配置 P1.0 为推挽输出(51 默认就是准双向口,可直接输出) // 无需额外配置 while (1) { P1_0 = 0; // 低电平点亮 LED Delay_ms(1000); P1_0 = 1; // 高电平熄灭 LED Delay_ms(1000); }} |
3.2.5.2 Clion + STM32F407VET6 HAL库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include "stm32f4xx_hal.h"void GPIO_Init(void) { HAL_Init(); // 1. HAL 库初始化 SystemClock_Config(); // 2. 系统时钟配置(CubeMX 生成) GPIO_InitTypeDef GPIO_InitStruct = {0}; // 使能 GPIOF 时钟 __HAL_RCC_GPIOF_CLK_ENABLE(); // 配置 PF9 为推挽输出 GPIO_InitStruct.Pin = GPIO_PIN_9; GPIO_InitStruct.Mode = GPIO_MODE_OUTPUT_PP; GPIO_InitStruct.Pull = GPIO_NOPULL; GPIO_InitStruct.Speed = GPIO_SPEED_FREQ_LOW; HAL_GPIO_Init(GPIOF, &GPIO_InitStruct); // 默认熄灭 LED HAL_GPIO_WritePin(GPIOF, GPIO_PIN_9, GPIO_PIN_SET);}int main(void) { GPIO_Init(); while (1) { HAL_GPIO_WritePin(GPIOF, GPIO_PIN_9, GPIO_PIN_RESET); // 点亮 HAL_Delay(1000); HAL_GPIO_WritePin(GPIOF, GPIO_PIN_9, GPIO_PIN_SET); // 熄灭 HAL_Delay(1000); }} |
3.2.5.3 VS-Code + STM32F103C8T6 标准库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | #include "stm32f10x.h"// 简单延时函数void Delay_ms(uint32_t ms) { uint32_t i; while (ms--) { for (i = 0; i < 8000; i++); // 大约 1ms @ 72MHz }}void gpioinit() { // 使能 GPIOC 时钟 RCC_APB2PeriphClockCmd(RCC_APB2Periph_GPIOC, ENABLE); // 配置 PC13 用于推挽输出 GPIO_InitTypeDef GPIO_InitStructure; GPIO_InitStructure.GPIO_Pin = GPIO_Pin_13; GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz; GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP; // 推挽输出 GPIO_Init(GPIOC, &GPIO_InitStructure);}int main(void) { gpioinit(); while (1) { GPIO_ResetBits(GPIOC, GPIO_Pin_13); // 低电平点亮 LED Delay_ms(1000); // 延时 1 秒 GPIO_SetBits(GPIOC, GPIO_Pin_13); // 高电平熄灭 LED Delay_ms(1000); // 延时 1 秒 }} |
3.2.5.4 Arduino + ESP32S3R8 Arduino库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | /* ESP32-S3R8 Arduino 点灯示例 功能:板载 LED 每隔 1 秒闪烁一次*/// 定义板载 LED 引脚// ESP32-S3R8 板载 LED 一般连接在 GPIO48#define LED_PIN 48void setup() { // 设置 LED 引脚为输出模式 pinMode(LED_PIN, OUTPUT);}void loop() { // 点亮 LED digitalWrite(LED_PIN, HIGH); delay(1000); // 延时 1 秒 // 熄灭 LED digitalWrite(LED_PIN, LOW); delay(1000); // 延时 1 秒} |
3.2.5.4 概括
发现了吗?尽管随mcu不同,头文件和函数命名有所不同,但是就电灯这一事件而言,都是给某个引脚输出高电平,延时,再给引脚输出低电平,再延时。
逻辑完全一样!
也就是说,从某种意义上,你可以理解为“**所有 MCU ,在所有 IDE 下的编程都大体相同”
四、如果这世上有人可以成为神,那为什么不能是我!以不朽的名义,我命令你——数据结构,在我面前显现真谛!
恭喜你到这里已经入门了基本的嵌入式编程,达到了普通大学电子系本科生大一或者大二的水平。
但如果你的目的不是于此止步的话,你就不能止步于此(废话)
如果你不想一辈子只能写点基本的电灯级别的玩意的话,以下还有少许的《数据结构》《数字电路》《基本算法》《常见编程范式》《设计模式》《软件工程》《项目工程管理》《线性代数》《范畴论》《计算机网络》《常用总线通信》《FPGA》《C++ 11》《C++20》《Effective C++》《CMAKE》《Git、Svn与版本控制》需要学习。
莫慌,我们一本一本来(doge)
4.1 顺序表
从上文的C基础教程部分,君已知晓。
如果说定义一个变量为a,能够存储一个数据。
那么定义一个数组,就能够存储连续的多个数据,并且能够通过下标(从0开始的计数)来访问任意位置的数据。
![[Pasted image 20251011103640.png]]
顺序表,粗略的理解就是数组,或者说顺序表就是更广义上的数组。
传统的数组在声明定义的时候就确定了大小,后续并不能随着数据量的增大动态扩张。顺序表范畴更大,还囊括了后续出现的“动态数组”、“向量”
4.1.1 传统数组
就是上文C语言中的数组,参见[[#3.1.9 数组]]
4.1.2 向量
这就要引入一个稍微进阶一点的知识了,叫做内存分配。
C语言中用的函数叫malloc,这个函数的作用是分配指定字节数大小的内存。
例如我们需要存储五个int变量,就可以将size但是还是建议采用sizeof函数来获取某一类型的具体占用字节以防溢出。
具体malloc函数和sizeof函数的具体使用,bro~这正是锻炼阅读文档能力的好机会,请到cpprefence网站搜索查阅(doge)
总之向量的本质就是,创建数组的时候创建一个附加的指针用来计算数组以及使用了多少,并且提供一些辅助的操作函数例如在“末尾新增数据”,然后当数组已满又新增的时候,就会重新malloc一段更大的空间把当前的数据都搬进去,再把原本的空间释放掉,这样就有空间追加新数据了。
4.1.3 优缺点
已知顺序表分配的内存是连续的,又已知数组名其实存储的是数组的首地址,又又已知固定数据类型变量占用的字节数是一致的。
那么,直接在数组名后面加上偏移就能得到任意位置的数值*(a+3*sizeof(int)),这也就是所谓的“下标”的原理。
因此,顺序表能方便的找到任意位置的数据,但是如果要在某个地方插入或者删除,就会很麻烦,因为要把插入位置后面的所有数据全部都依次移动。
4.2 链表
一个篮子挂个链子链子下面挂个篮子
![[Pasted image 20251011141543.png]]
篮子就是变量
链子就是指针,指向下一个篮子
一个带链子的篮子就是一个结构体
1 2 3 4 5 | struct chainNode{ int a; struct chainNode* nextChainNode;} |
创建很多个这种篮子再串起来的存储方式就是链表,好处是可以方便在任何地方插入或者删除篮子,坏处是因为存储空间在内存里不是连续的(每一层都是通过指针跳转的),所以没有数组那样的下标,查找某个篮子时候要从头顺着往下捋。
4.3 队列和栈
如果说顺序表和链表在优缺点上互为相反,那栈和队列就是在用法上互为相反。
队列是先进先出。
栈是先进后出。
如何理解呢?
队列就像吃饭拉屎,你早上吃的早饭会比午饭先拉出来。
栈就像吃多了催吐,你最后吃进去的东西在最上面,会最先呕出来。
![[Pasted image 20251011144026.png]]
具体实现上,不管是哪种队列或是栈,都可以用(数组+指针)的方式或者链表方式实现,
建议自己尝试一下。
4.4 树
树,可以简单的分为两种。
一种是二叉树,一种是其它~
其具体区别为:二叉树每一根分支最多长两个杈杈(长叶子也算杈)。
正所谓道生一,一生二,二生三,三生万物。
二叉树,生b树以外一切树。
4.4.1 普通树和B树
4.4.1.1 普通树
就是最基本的树,一个节点下面可以挂任意数量叶子
4.4.1.2 B树和B+树
又名多路平衡查找树。主要用途就是数据库底层在用,你可以简单理解为把很多数据按顺序分为很多组,每组又按顺序分成很多组,这样查询的时候,直接进大分组再进小分组再进更小的分组,就能快速找到需要的数据。
4.4.2 二叉树
所谓二叉树,就是每个每一根分支最多长两个杈杈。
长不满的叫二叉树,每个分支都长满两个杈(除了最后一层)的叫完全二叉树
在分类、排序、数据存储等多种方向有用
4.4.2.1 二叉树的存储
二叉树的一大是可以用数组存储。比如第一位是根,第二位是第二层第一个,第三位是第二层第二个......这样存储后,每个杈和两个子杈的关系都是左边2n右边2n+1。方便存储也方便查找。
但前提是使用完全二叉树。
如果是不完全的二叉树这样存储,可能会浪费一定的空间(数组没存满,部分位置是空的)
4.4.2.2 二叉树的遍历
常见的有先序遍历,中序遍历和后序遍历
这里的先、中、后指的是根放的位置。
每个节点以及对应的两个子节点都按照根左右的顺序排,就是先序,按照左根右就是中序,按照左右根就是后序
4.4.2.3 二叉树的变体
太多了,二叉搜索树,二叉平衡树,红黑树,哈夫曼树等等,都是在基本的二叉树上加上扩展思想而形成的。
建议用到什么再看什么
4.5 图
太长了,肝不动了,什么时候我想起来再写
五、什么?你说你只是个凡人?那你愿意跟我一起走上设计模式的登神之路吗?
5.-2 从面向过程到面向对象
一、面向过程与面向对象的本质是哲学。
从本质上而言,面向过程的和面向对象的本质是处理事务的方式。
它们不是所谓的顺序结构、类和抽象,也不是转型重载和继承等编程机制,而是如何理解事务,如何看待事务,如何处理事务的哲学思想。
一、面向过程(OP)
面向过程是最基本的编程思想,它基于事件本身的逻辑。
也就是要想做一件事,我们应该分哪几步,先做什么后做什么。
譬如以一个饭店炒菜的事情为例,首先买菜,洗菜,切菜,然后热锅,烧油,炒制,调味,装盘,最后查询这道菜是那桌点的,把菜呈给对应的客人。
这种把一件事情细化为多个步骤,然后按顺序完成的思想就叫做面向过程。
面向过程最核心的思路在于如何把一件事务按照逻辑拆解,譬如你肯定无法先热锅,然后装盘,再切菜,再炒制,然后再洗菜。
二、面向对象(OOP)
面向对象则是在面向过程基础上进一步发展的团队协作。在理解过程的基础上,把任务合理的分给多个角色去做。
依然以饭店炒菜的例子为例,首先安排一个配菜员负责买菜,洗菜,和不断切菜,再安排一个厨师热锅,烧油,炒制,调味,装盘,最后再安排一个服务员负责上菜。
这种多个角色协作解决事务的思路就叫做面向对象。
面向对象的核心思路在于任务分配的合理,譬如你安排一个人负责热锅和买菜,一个人负责烧油和上菜,另一个人负责洗菜和装盘,厨房大概就会乱成一团。
三、面向对象与面向过程的关系
1. 只有一个对象的面向对象是面向过程,有多组过程的面向过程是面向对象。
面向过程和面向对象并不是不同的,它们在一定程度上可以相互转化。
当面向对象只有一个对象,任务全都分配给一个角色的时候,就没有了所谓的面向过程。
同样的,当有多个角色同时来解决同一个问题,每个角色负责一组行为时,也就从面向过程变成了面向对象。
2. 面向过程的核心思想是事件的逻辑,面向对象的核心思想是协作的秩序。
面向过程的核心思想是对事件按照逻辑进行合理的拆分,使之细化为按顺序执行的步骤。
面向对象的核心思想是如何把任务进行合理的划分,再分别交给不同的角色。
3. 面向过程是面向对象的基础,没有面向过程也就没有面向对象
面向对象是依赖于面向过程的,要能够对一个任务进行合理的划分,必须首先了解这个任务原本大体是怎样执行的,然后把原本一个角色完成的任务进行合理的拆分。而且拆分之后每个角色的工作还是面向过程的。
同样以人举例,面向过程是一个人做事,面向对象是许多个(一个人)一起协作。连基本的一个人都没有的话,哪来的多人。而且就算一个任务分给多个人做了,每个人自己做事情不还是有逻辑顺序的吗?按上面餐馆的例子,配菜员不还是得按买菜洗菜切菜的面向过程流程走吗?
四、C++的简单OOP编程
5.-1 在开始学习之前你得先明白的
在你开始get本文章后续技能时请先确保自己已了解本章节内容,如无法确保请再读一遍,如仍无法确保请再再读一遍,如......
(-1).1 为什么说面向对象的核心是解耦合
面向对象的核心优势
面向对象的优势除了更适宜人类思维方式之外,体现在代码质量上主要有以下三点:
- 易于维护
- 更容易实现代码复用
- 具有更良好的扩展性
而这三点又有一个共同点:都是基于解耦合的方式实现的。
解耦合与易维护
易维护从根本上就是建立于解耦合上的,因为解耦合,所以修改的时候只需要修改单独的个别代码块而不需要对整个程序到处编辑
解耦合与代码复用
面向对象之所以在代码复用上有优势,是因为存在类的抽象,能够从类的层次进行复用,即“类的复用”,而这一复用的前提是被复用的类本身遵循了SRP设计原则(具体内容见下文(-1).2),否则一个同时承担了多个功能,各种代码混杂在一起的类基本上复用的收益是很低的。想象一下,你能想像一个类一部分用于界面显示,但这个类里还有半个数据库处理流程和半个压缩包处理,甚至还塞了半截输入输出处理流程吗?你要怎么复用这个类呢?
解耦合与代码的扩展性
正是因为有解耦合的存在,每个功能被分开做成不同的模块,代码才称得上有可扩展性——当要扩展某一方面功能的时候只需要修改对应的部分而不需要把整个项目重写一遍。
如果没有解耦合,所有代码紧密耦合在一起,那就没有可扩展性了,整个项目大改一遍还不如直接重写。
(-1).2 如何用鞭子抽打大象
(-1).2.1 两种常见的关系
(-1).2.1.1 继承
其本质在于实现“XX是YY”的逻辑
(-1).2.1.2 组合
其本质在于实现“XX有YY”的逻辑
(-1).2.1.3 你还不懂的话就看这个
继承表示一种向下逐渐细分,向上逐渐统一的层级关系,例如猫类可以继承自动物类,因为猫是动物,卡车可以继承自汽车类,因为卡车是汽车,继承关系表示的通常是抽象概念的细化实现与落实,并且具有传递性。如狸花猫是猫,猫是猫科动物,猫科动物是动物。猫科动物是动物的细化落实,猫是猫科动物的细化落实,狸花猫是猫的细化分类落实,并且一通继承下来,最终的猫也还是属于最初的动物。
组合表示一种大小包含,模块化构建的层次关系,例如汽车拥有前保险杠,油箱,发动机,变速箱。但变速箱不是汽车,油箱也不是汽车,它们之间有一定关联但并不是继承的关系,而是类似拼图的关系,大的汽车由小的模块化的部件单位组合而成。
继承和组合不存在优劣关系或者竞争关系,在不同的情况下各自适用,例如一个基本的对话框界面可以继承自视图类(新的对话框是视图),而用户界面里面引用的现有资源则应该以组合方式引用(对话框里有标题框和按钮)
(-1).2.2 SOLID原则
即,一个良好的面向对象的程序在设计时应遵守以下五大基本原则。
S:SRP
单一职责原则:“任何一个软件模块都应该只对某一类行为负责”
就好比服务员不需要炒菜,厨师不需要会算账,采购员不需要会安保。
一字头改锥不适合用来铲猫砂。
大家(每个类)都干好自己的活就行了
O:OCP
开放封闭原则:“软件实体应当对扩展开放,对修改关闭”
通俗的来讲,就是当你给程序追加一个新功能,不需要把半个项目都重构一遍。
尽可能地解耦合并尽可能地在系统架构设计阶段考虑到未来项目可能的发展,从而使追加新功能变得容易,并且减少甚至杜绝新加功能时对已有良好功能的修改。
L:LSP
**里氏替换原则:**使用基类对象指针或引用的函数必须能够在不了解衍生类的条件下使用衍生类的对象
简单来说就是,继承关系要完全实现XX是YY”的关系,例如可乐类继承自液体饮料,那么可乐是液体饮料,液体饮料的一切性质可乐都要有,液体饮料可以喝可乐就可以喝,液体饮料是液体可乐就是液体。
子类必须能够完全替代父类,任何一个地方如果能用父类,放一个子类对象过去也一样可以。
你不能继承自液体饮料类然后生产一种不能喝的液体饮料,也不能生产一种气体的液体饮料,因为它们不是液体饮料。
I:ISP
**接口隔离原则:**不应强制客户端依赖于它们不使用的接口
我称之为接口的解耦合。我们不应把一堆乱七八糟的东西塞进同一个接口里,而应该让一个接口做一件专一的事情。
譬如为MySQL提供的接口不需要包含MongoDB的实现。
这样一来一个只使用MySQL的用户就不需要把MongoDB的的功能函数也全都实现一遍。
这样一来不仅开发便捷,还可以有效减少代码里的垃圾。
不然的话你的接口就是屎山里屎的源头。
D:DIP
**依赖倒置原则:**高层次的模块不应该依赖低层次的模块,他们都应该依赖于抽象。抽象不应该依赖于具体实现,具体实现应该依赖于抽象
这个理解之所以称之为倒置原则,是因为它的理论其实挺反直觉的。
通常来说大家都认为,驱动依赖于硬件,底层依赖于驱动,上层软件代码依赖于底层。如此一层一层依赖,一层一层引用。
而依赖倒置就是说,我们在设计程序时候不应该自下而上而应该自上而下,在涉及到依赖关系的环节,采取抽象类或者接口的方式进行解耦。这样一来当不同层级出现修改、甚至出现功能变化时,就不需要其他层级也跟着大改。
比如货物的运输依赖于物理的运输方式,你直接写死运输方式为卡车,并且把卡车的具体功能函数写进来,过段时间底层增加了海运,你就得把整个货物运输重写一遍,然后加入火车时候再重写一遍,引入飞机航运时候再重写一遍。
而你如果一开始写的是货物运输依赖于运输方式类,然后在运输方式类里实现卡车接口,等其他功能进来你只需要在运输方式类里面加加加就行了。
5.1. 创建型模式
5.1.1 泥头车创创子,零落成泥碾做尘
创建型模式提供了创建对象的机制,从而将对象的创建与使用分离,能够提升代码的可拓展性并更容易实现代码复用。
怎么样,被术语创到没(doge)
理解简化版:创建型模式:把对象创建和使用解耦合
<font color=red> 1.1.@#$%^ 简%……&单【【错误!】】工厂模【删除】式
警告:该模式违反 SRP 单一职责原则,是一种错误范式。它不是一个真正的设计模式,仅仅是工厂模式的前身</font>
简单工厂模式并不在设计模式列表里,也不是一种正式的设计模式,在这里添加这一小节仅仅是为了便于你更容易了解后文的工厂模式。因此请务必记住 简单工厂不是设计模式,简单工厂模式是错误的!
所谓简单工厂模式就是说,有一个“工厂”能够根据用户的需求提供不同的“产品实例”
例如:
我们有一个饮料类,并且有两个子类糯香柠檬茶和崂山蛇草水,你有时候想喝糯香柠檬茶,有时候想喝崂山蛇草水,而这个时候你有一个室友大爹(工厂),根据你不同的要求,他会给你带回对应的洗袜子水——我是说饮料。
5.1.1.1 工厂方法(函数)模式
在上一个【错误】模式中,我们已经把糯香柠檬茶和崂山蛇草水抽象出了饮料的层级,这使得你想要再追加新饮品譬如恒河水的时候不需要触碰已有的饮料相关类,然而由于你的室友大爹代购函数和糯香柠檬茶与崂山蛇草水直接耦合,这导致你每当想喝不同的东西,就得修改一遍室友大爹代购函数,增加一种新的饮料。
因此工厂方法(函数)模式就是在这个基础上,把你的室友大爹代购函数也抽象出来,把它做成一个接口。然后你就可以写两个室友大爹代购函数的实现类,分别是室友大爹喂我喝糯香柠檬水和室友大爹喂我喝崂山蛇草水。
然后你自己的室友大爹代购函数自身是个抽象接口(或者父类),根据 LSP 原则,不管是室友大爹喂我喝糯香柠檬水还是室友大爹喂我喝崂山蛇草水都可以直接接替进来。并且当你需要追加一种新饮料的时候,只需要创建两个新类恒河水和室友大爹喂我喝恒河水即可,原有的功能代码全部不需要改动。(良好的符合 OCP 原则的实现)
5.1.1.2 抽象工厂模式
上一节的工厂模式只能提供一个大类的产品(饮料),而抽象工厂模式,就是工厂接口提供更多的产品大类。
通俗的来讲,就是你的室友大爹除了给你带“饮料”,还能给你带“盖饭”
5.1.1.3 生成器模式
如果说上述模式是为了解决产品与用户之间解耦合的话,那么生成器模式(也称建造者模式),就是为了实现复杂产品或自定义产品(总之就是同一类但有部分差别的产品)的生产问题。
这里用饭店炒菜来举例子。
你创建了一个“出餐”函数对用户提供产品,通过输入不同的产品要求和工序参数,用户能够获得各自不同需求的产品。
比如酸辣土豆丝不要醋和土豆丝、麻辣豆腐不要花椒和辣椒、葱花饼不要放葱花、鱼香肉丝里多加芝士和腐竹等等。
(别问,问就是客人是上帝,甲方是大爷)
于是为了适应不同用户的需求,你最终会写出一个巨大巨大巨大巨大的出餐函数。
而这时候来了一个脑子正常的甲方A,他想买一份宫保鸡丁。
他看着有两万多个参数的出餐函数陷入了沉思。
然后开始填写:“不要酸辣土豆丝,不要麻婆豆腐,不要馅饼,不要鱼香茄子,要宫保鸡丁,不加辣椒,不加土豆丝,不加盘子,不加餐具吗,不加杯子,不要炒米饭,不要炒面,要米饭,不要饼,要油炒,要鸡丁,要花生米,要糖,不要腐竹,不加茄丁......”
而这时候来了一个脑子正常的甲方B,他想买一个馒头。
两个小时之后,流程还没执行完。
第二天,接到过多投诉的你因为左脚先迈进公司被董事会开除。
发现这个函数的问题了吗?出餐这个概念的设计的东西太多了!
我们完全可以给每个菜单独抽离出来,出餐的地方配置一大组接口,用户用什么就去调用对应的工序,比如用户可以先添加宫保鸡丁基本工序,再添加一个炒制过程加入茄丁附加工序,就得到了加茄丁的宫保鸡丁。
而且也不用买个馒头都跑一遍完整工序了。
后续追加菜品也容易了,新加接口就行,不用把巨大巨大巨大巨大的函数再改一遍。
5.1.1.4 单例模式
单例模式从理解的方面来说,其实核心思想就是:“只有一个我”,这样一来就可以解决两个问题:
- 有些类只能有一个实例,例如一个操作系统只能有一个id生成器(否则两个生成器生成的id可能重复),或者有些你到处使用的工具类来回创建销毁对象会导致很大的资源开销,那就不如保留一个实例一直用。
- 有些东西你定义成全局变量很容易被局部变量给覆盖了导致访问不到,而单例模式是无法拷贝也无法生成新实例的,因此不管在任何作用域如何访问,都能只能访问同一个实例。
从概念上来说,其本质就是:
你只能被创造(出生)一次。
从此之后不管谁找你,找到的都是你,因为你是唯一的。
从实现的角度来说,就是把实际的真构造函数设置为私有,并且存储一个提供一个指向实例的指针,然后对外提供的构造函数有条件的引用这个构造函数。
当实例不存在(世界上还没有你)就创造一个你,并且把你的位置存储进指针,当实例存在(世界上已经有你),就返回实例引用(告诉调用者你的位置)
5.1.1.5 原型模式
原型模式取自于设备开发的“原型机”概念。
要便于理解的话其实使用“基础模板”这个说法更好理解。
当我们拥有一个“模板”,就可以参照模板生成出一模一样的产品(或半成品)。
例如假如我们有一个笔记本电脑模板了,它包含主板屏幕金属外壳和薄膜键盘以及触摸板。但并没有cpu和显卡网卡硬盘内存。
我们可以根据这个模板,生产出大量的半成品,然后为它们插上不同的cpu和显卡网卡硬盘内存,成为不同配置的产品。
这样一来我们甚至可以简化一些类和及其子类的构造
并且采取这种方式的话,我们甚至连未提供拷贝构造函数的类的外部无法访问的那些私有变量都可以拷贝复制。
而且原型的实现也非常简单,只要提供一个“自我复函数”就行了(当然,为了便于使用,最好设计的时候就提供一个统一的“自我复制接口”,然后在各个原型类继承接口并实现)
5.2. 结构型模式
5.1.1.1 适配器模式
适配器,又名转换器,转接器,转接头。
用来解决实际输入和提供的接口不适配的问题。
例如最常见的把三孔电源插座转换成两孔插座的转接头,就是一种适配器。
又比如接口只接受json数据,实际上报的却是xml,那么中间加的这个格式转换的类就叫做适配器
显然的,通过增加适配器类,可以避免对已有的两端代码的修改,并且实现了两端代码的解耦合
5.1.1.2 装饰器模式
装饰器,又名附加器,套壳。
就是在不改变原有对象结构情况下,扩展新功能的一个办法。
把新功能做成一层一层套壳,要追加什么功能就套什么壳,需要多个功能的话就多套几层壳。
实现原理上,首先首先内核类得是抽象的(或是接口),然后装饰器类也是抽象的,并且抽象的装饰器类继承(或实现)内核类,这样一来,根据里氏替换原则,每一个装饰器的输出实例都是内核。
然后真正的内核继承抽象内核,实例化出来。
真正的装饰器继承抽象装饰器 ,并持有一个抽像内核对象(或指针)这样就能装载传进来的的内核。然后再写上扩展的功能函数。实例化完就是增加了新功能的内核PLUS了
这样一来每当我们追加新内核类型或者追加新扩展功能时候,都不再需要修改已有的代码,遵守了OCP开放封闭原则。并且避免了嵌套继承导致的子类指数级别上升问题。
5.1.1.3 代理模式
也可以称之为经纪人模式。
经纪人代替你和外边交流,他实现了你对外交流的一切接口,接项目代替你谈,谈收益代替你出面,公开场合和招待会代替你说话。
大家需要对你说的话直接对他说就行,需要你合作的事直接和他商谈就行。
甚至于通过他交流相比直接和你交流,双方还都能更方便,对你来说经纪人可以帮你把信息过滤一遍还能解决你分身乏术的问题,对客户来说经纪人的金融和法律知识水平更专业!
甚至甲方和你还能解耦合,必要时候经纪人也可以和其他明星对接(bushi)。
实现上就是写一个替身类,实现原来“你”的所有对外接口,然后这个类再引用“你”进行操作。
所有需要你的地方,用这个类就行了。
5.1.1.4 外观模式
说的高大上点就是再封装,你也可以理解为代理模式PLUS。
比方说你要引用一个非常复杂的库,但只需要实现非常简单的功能,但库为了兼容各种需求需要非常繁复的操作流程来使用。
并且导致耦合
于是你给它套了个壳,弄了个新类把你要用的功能封装成几个单独的功能函数,然后通过这个类来操作那个复杂的库。
这个类就是所谓的外观。
省力、复用并且解耦。
5.1.1.5 桥接模式
就是文章开头“继承与组合”那一章节说的组合,“XX有YY”的逻辑。
5.1.1.6 组合模式
此组合非彼组合,和“继承与组合”的“组合名字一样却不是一个花色(高傲)”
这里的组合指的是把多个相同或不同的对象组合成一个可以树状展开的大对象。
比如文件夹下有文件和文件夹,里面的文件夹下又有各自文件和文件夹,这种的。
但这只是个树状结构吖,这不是数据结构吗,和设计模式有什么关系。
当然是还有别的要求啦,用户使用这个大对象要和使用小对象没有区别。
什么叫使用大对象和小对象没有区别呢?
比如用户问:你包含多少文件?
文件会说:1
小文件夹会遍历一下自己,然后把文件数给你
大文件夹(包含子文件夹的文件夹)会遍历一下自己(注意,子文件夹会递归!)然后告诉你总数
单个文件,小文件夹和大文件夹的层次结构并不同,但对用户来说,都是调用一下getfilesnum(),没有任何区别。(也就是说,树中不同类型的对象要都实现相同的接口“逻辑不一定相同,例如文件夹和文件的getfilesnum()处理逻辑就不同”)
5.1.1.7 享元模式
这个就是纯粹的代码复用。
如果多个对象具有共有的属性(就是多个对象的某个特点始终一致,例如游戏里每颗子弹可以使用一样的贴图),我们就可以把这个共有的属性单独抽出来存在外边,这样一来我们在游戏里射500发子弹就不用存储500个贴图,能有效降低性能需求。
5.3. 行为型模式
5.1.1.1 策略模式
就是最标准的解耦合。
举个栗子
你有一个类,它的功能是遍历二叉树。
它可以先序遍历二叉树,中序遍历二叉树,或者后序遍历二叉树
《数据结构内容》,如还未学可简单理解为通过三种不同的算法实现遍历功能
你要怎么做呢?
三目运算符?if 条件判断?switch/case 结构?
当然可以这么做。
毕竟栗子只有三种算法并且并不复杂——但是如果算法非常多并且非常复杂,那你将得到一个非常庞大庞大庞大的类或者函数。
这显然非常不解耦合,并且非常难维护,一点也不OCP原则。
那么该怎么做呢?把算法全都抽离出去不就好了?
用哪个算法的时候就把哪个算法接进来。
后续要增加新的算法也不需要修改已有的代码。
维护某个算法的代码时候也不会影响其他的算法和功能代码。
设计模式的核心就是解耦合啊!
解耦合! 解耦合!还是他喵的解耦合!
5.1.1.2 模板方法模式
如果说策略模式是标准的解耦合,
那么模板方法模式就是标准的代码复用。
策略模式要解决的问题是一个功能要对接多个不同的算法,
模板方法模式要解决的问题是多个功能采用了非常相似的算法。
实现原理也很简单标准,把算法拆成步骤,把重复的部分抽离到一个函数或类中,然后调用。
5.1.1.3 观察者模式
二次元手游预约模式 be like。
假设你是个游戏厂商。
你希望对你的游戏感兴趣的人能收到你的消息推送。
并且你不想粗暴的到处乱发短信——成本高而且广告会影响路人好感。
那么你应该怎么做呢?
如果你不知道你就找个最近将要发售的手游官网看看。
他们会放一个预约按钮,让感兴趣的玩家来主动注册留下手机号。
然后,他们只需要给这些人发消息就行了。
目标用户主动留下注册信息(订阅/预约/关注),当有消息时,遍历这个注册用户列表把消息发给列表里的用户,这就叫观察者。
5.1.1.4 迭代器模式
好好学过 C++ 和 STL 的小伙伴想来对迭代器很熟悉了。
迭代器,顾名思义其实就是一个遍历工具。
通过这个工具,你可以以某种顺序遍历整个结构的每一个节点。
比如最简单的,容器 vector (没学过C++STL的可以简单理解成动态数组)的迭代器,可以通过++和--向前或者向后移动,到达 vector 的任何一个位置。
迭代器还会记录自己的位置,这样有多个迭代器的时候,就可以通过数学运算比较来判断它们的位置关系,例如 a 在 b 的前面 (a>b) , a 和 b 的距离 (a-b) 等。
通过使用统一接口的迭代器,可以降低代码与底层特定数据结构的耦合。
并且当需要以新的方式遍历时,可以直接创建新的迭代器类型,不需要改动现有代码。(良好的OCP实现)
5.1.1.5 责任链模式
让尾大的喵格索托斯换一种方式来将知识怼进乃的脑子。
如何理解责任链这一模式呢?
假设你是一个猫又,我是说CTO。
你带领着一支寄术团队开了一家小店。
这个团队有三个人
- 业务法师负责坐在店门口接受产品订单,
- 后勤炼金术士负责分析产品需要的材料,计划订单的合理性,到市场上采购和讨价还价,把买好的原材料运回来,初步加工为工业素材,根据产品需求二次加工材料为半成品,制成产品粗胚,精细加工打磨,刻画花纹,制作华美的包装用箱子,打包运送到客户家里。
- 清洁勇者负责挥舞
圣·伟大·众神赐福的屏退黑暗的光之扫帚确保店门口没有烟头什么的。
不知道是不用心还是态度不端正,后勤炼金术士总是时不时的犯一些错误,不像业务法师和清洁勇者一样一丝不苟从不出错——哪怕你已经生气的指责他很多次了。
有一天,后勤术士突然想开了辞职了。剩下三个呆比面面相觑。
这家店的问题到底出在什么地方呢?
其本质想来是这家店里有一个傻子。
但凡你不傻也不会把分工分成这样。
还记得SRP单一职责原则吗mybro?
一个人负责接收订单和分析订单,一个人负责采购材料和配单,一个人负责加工粗胚,一个人负责细化,任何一步出问题都可以及时发现并中断订单。
这样你的店才开的下去。
——而且也不会因为某个核心人物的缺失而导致所有环节都无以为继,真走了某个单环节工人也可以方便的招到替换。
5.1.1.6 命令模式
从便于理解的角度而言,我觉得订单模式是一个更好的名字。
通常情况下,两个不同系统(或者模块)之间的交流大致是这样的。
- 顾客:给我西湖醋鱼
- 餐厅:交出西湖醋鱼
- 顾客:给我筷子
- 餐厅:交出筷子
- 顾客:给我老北京豆汁
- 餐厅:交出老北京豆汁
这河狸吗?
看很河狸。
但更海狸的方式是
- 扫桌子上的二维码,选择西湖醋鱼+1,选择老北京豆汁+1,勾选需要餐具。把你所有的需求都写进订单就完事了。
这样一来一方面避免了顾客必须被锁死在窗口前和点单员进行长时间的交流,一方面让订单进入等待队列也缓解了点餐员人数不足的问题——一桌子菜可能得上半个小时,你占着收银员别人点不点餐了,得配多少收银员才够啊。
5.1.1.7 备忘录模式
备忘录模式当然非常不好理解的啦喵!
但是你把它叫历史记录模式或者恢复映像模式就很好理解啦喵!
参考 Windows 操作系统的系统还原点!
每当要做一些事情怕出错就备份一下,然后如果有问题,就可以读取这个还原点回退回去。
因为权限问题和封包问题,有些东西我们在外面访问不到,所以得让要备份状态的类自己备个份给我们(让Windows系统自己备份一个系统镜像给我们)管理,然后如果后面系统出问题了,我们就可以在存储的所有备份里找到一个出问题之前的备份,把它传回给Windows系统让它“恢复镜像”。
在这里面有三个关键点。
一是镜像要由系统(要备份的类)创建
因为由于权限和封包我们在外面有些数据不好访问,强行修改权限访问会导致闭包泄露(也就是不该被外界访问的数据还是被我们从外界访问了)这是不应当出现的。二是根据单一职责原则(SRP),原本的类不应该增加管理镜像这种与原本逻辑无关的功能
所以镜像需要用单独的管理类(例子中的我们)来管理三是出于安全性考虑,对于这个镜像,管理类只有管理权限,不能访问、操作和修改——至多可以通过镜像提供的公开接口读取一些公开的状态信息之类的。这样可以最大程度上保障闭包的完整。
5.1.1.8 状态模式
最标准的实现就是状态机(详见《计算机组成原理》)
能够根据设定的环境参数与状态参数的不同,执行不同的工作。
5.1.1.9 访问者模式
事情是这样的。
让我们假设你是一台打印机。
你能够将机械控制编码转换成图像。
目前有一份文档需要打印,这个文档中包含文字、图片、图表、页眉页脚。
显而易见,出于SRP原则,文档显然不应该包含转换为打印机机械控制编码的功能。
否则的话各种不同的打印机/激光雕刻机/cnc雕刻机的机械控制编码各不相同
全都塞进文档里会导致文档又大又不稳定又和各种打印机耦合太深并且还不好维护。
那么你该如何完成工作呢?
当然是使用你的驱动!
文档里的文字和图片、图标等元素只要实现同一个接口,允许驱动对接自己就行了。
这个接口只需要做一件事,接入驱动并且调用自己类型的处理函数
具体每种元素应该怎么转化成某个打印机的控制编码的处理函数,由驱动来实现。
这样不同的设备就可以实现不同的代码逻辑。
当要打印文档的时候,你找到你的驱动,你的驱动找到文档,文档遍历自己的所有元素,并且按顺序逐一和你的驱动对接。
这样一来就有了适合你的机械控制编码
5.1.1.10 中介者模式
众所周知,两个电话之间接一根线就能互相通话。
众所周知,三个电话之间只需要接三根线就能互相通话。
众所周知,四个电话之间只需要六根线就能通话。
...
众所周知,一百个电话之间只需要四千九百五十根线就能通话了。
...
那么为什么你家/你公司的电话上没有插着成万上亿根电话线呢?
因为有个尾巴很多的东西叫交换机。
你不需要连接到所有电话,你只需要连接到交换机。
其他人也只需要连接到交换机。
交换机就是“中介者”
它会把所有人的电话彼此解耦合。
免得你家的电话线缆直径比你家房子还粗。
5.1.1.11 解释器模式
最好理解的设计模式
最典型的实现是 JAVA 语言的 JVM 虚拟机,它会根据JAVA语言的文法规范分析 JAVA 代码,然后运行。
JVM 就是解释器,这个根据JAVA语言的文法规范分析 JAVA 代码 的过程就叫做解释。
六、你可卑微如尘土,不可屈膝向未知。如果玄幻的道路走不通,那就数学封神!出来吧!数字电路
七、阿萨托斯!馄饨与吃鱼之神啊,请赐予我永不浑噩的诅咒!我将直面一切知识——哪怕是计算机网络基础
一. 网络基础知识
1. 网络分层
网络模型大概有两种,一种是四层模型一种是七层模型。七层协议如果不做底层的话简单理解即可,通常的软件开发中实际会接触到的只有四层。
- OSI七层模型
- 应用层
- 表示层
- 会话层
- 传输层
- 网络层
- 数据链路层
- 物理层
- 四层 ,比方说浏览器发送http请求和服务器获取网页数据
- 应用层 (各种应用软件和工具软件)
- ping
- telent
- OSPF
- DNS
- 传输层 (数据传输协议)
- TCP 三次握手连接,稳定传输
- UDP 无连接直接发包,即时性强,不稳定可能丢包
- 网络层 (设备之间的网络通信协议)
- ICMP
- IP
- 数据链路层 (建立在硬件物理上的链接关系)
- ARP(IP和物理地址MAC之间的转换协议)
- Data Link
- RARP(IP和物理地址MAC之间的转换协议)
- 应用层 (各种应用软件和工具软件)
其中:
应用层就是一般各种应用发送的网络交互,比如ping、telent、http啊甚至dns解析之类的,这种软件的数据交互,就叫做应用层.
然后传输层就是数据具体怎么传输,常见的有tcp和udp。
其中tcp需要三次握手建立长连接,四次挥手断开连接,面向连接进行数据交互,数据稳定性很好,中间包数据出错会自动重传确保数据稳定,正常不会因为丢包导致数据缺失什么的。
udp的话就是我发出去了,你收没收到无所谓反正我发了,一般游戏之类要求实时性不太要求稳定性的就会用udp,因为tcp如果丢包就会重传会影响延迟,udp丢了就丢了,发下一包数据就行了,比方说有些游戏网卡的时候人物闪现,就是因为中间包的数据丢了,导致位置信息不连贯了。
到了网络层,就和网络通信的原理开始挂钩了,比方说IP协议用来区分网络地址啊,ICMP用来判断IP包状态啊之类的。
再往下就是数据链路层,这一层已经与网络驱动与物理设备直接相关了,比方说接入网络的设备一般都有一串(通常用十六进制表示的)物理地址(MAC),ARP 和 RARP 就是处理网络IP地址和物理MAC 地址之间的转换的协议
2. IP地址
- ipv4
- 点分十进制,每段一字节 示例:192.168.1.123
- 四字节(每段一字节)
- ipv6
- 冒号分隔16进制,每段二字节 示例:2408:8207:7890:4dd0:d8f1:ce1d:c6ea:1d01
- 十六字节(每段两字节)
3. 端口
16位整数(0-65535),分配给应用或者服务用来进行网络通信的端口。
例如可以通过netstat查看端口
4. 字节序
- 大端(网络字节序)
- 高位地址存低位数据 (例如 12 56 89 AB)
- 小端(主机字节序)
- 高位地址存高位数据 (例如 AB 89 56 12)
4.1 转序函数(Linux 环境下)
1. 整数转序
1 2 3 4 5 | #include <arpa/inet.h>htons() //16位主机到网络(序)转换htonl() //32位主机到网络(序)转换ntohs() //16位网络到主机(序)转换ntohl() //32位网络到主机(序)转换 |
2. IP地址转序
1 2 3 4 | inet_pton(地址类型,地址字符串,用于输出的内存指针) \\IP地址转网络序inet_ntop(地址类型,网络序字符串,用于输出的字符串指针,字符串指针指向内存的大小) \\网络序转IP地址,调用成功返回字符串指针,失败返回nullinet_addr(字符串) \\IP转网络序(仅ipv4)inet_ntoa(结构体) \\网络序转ip(仅ipv4) |
- 地址类型:
AF_INET(ipv4),AF_INET6(ipv6)
5. 数据包结构
PS:实际上就是上文的四层结构一层层套起来。
这里我们用wireshark软件抓取包进行分析
![[Pasted image 20251114210654.png]]
注意看左下方的包结构
首先是下面的应用层传输的数据。
![[Pasted image 20251114212811.png]]
然后,在这个数据前面,增加了一部分TCP协议有关的内容,这一部分如上文所说的,属于传输层
![[Pasted image 20251114213039.png]]
再之前是IP协议对应的内容,显而易见的这部分属于网络层。
![[Pasted image 20251114213338.png]]
最后,对应最开头的这部分数据,我们发现这里的src(源地址)和dst(目标地址)不再是IP地址了,而是MAC物理地址,这里我们来到了数据链路层
![[Pasted image 20251114213823.png]]
由此可见我们可以得出如下的网络数据包结构(实际上就是网络四层结构)
![[Pasted image 20251114214204.png]]
二、通信流程
2.1. Socket
2.1.1 Socket是什么
工作在OSI七层模型、TCPIP五层模型中的传输层与应用层之间,TCP协议的封装(详见基础篇-计算机网络原理)
2.1.2 Socket通信基本流程
2.1.2.1 流程描述(文字)
服务端
- socket 创建插槽
- bind 绑定本机IP结构体
- listen 监听连接请求
- accept 接受请求并分配一个新插槽用于通信(因为服务器要同时面对多个客户端,不能直接把监听那个套接字堵塞)
- read write 通信
客户端
- socket 创建插槽
- connect 把插槽怼进服务器(连接到服务器)
- read write 通信
通信结束后双方断开
close 结束连接
2.1.2.2 流程描述(图)
![[Socket1.2.2.png]]
2.1.2.3 快速理解(如果你前俩看不懂就看这个)
医院=服务器
病人=客户端
医院方:
医院创建一个挂号导诊台 socket
挂号导诊台设立在此医院门口 bind
挂号导诊台等待病人来问诊 listen
当病人来时为其挂号安排科室医生 accept(不能让病人全都堵在导诊台聊天)
病人和科室医生交流诊治 read write
病人走了 close
病人方:
病人患了一种病 socket
病人来到医院导寻求诊治 connect
与导诊台分配的适宜科室医生交流 read write
诊治完走了 close
2.2. IO模型
2.2.1 同步/异步、阻塞/非阻塞
2.2.1.1 关系图
![[IO2.1.png]]
NOTE:异步情况下一定非阻塞,所以异步根本没有阻塞概念,<font color=red>异步阻塞与异步非阻塞都是错的</font>,异步就是异步!
2.2.2.2 同步与异步
同步与异步是指我们进行一个任务时,任务是否等待执行结果。
同步情况下任务会一直等待到结果,然后返回。
异步情况下任务把请求送达之后直接不管了,等执行结果出来了我们会收到通知,这个时候我们再去取结果。
2.2.2.3 阻塞与非阻塞
阻塞是当我们进行一个任务时,我们是否等待任务结果。
阻塞情况下我们一直等到任务完成结果回来。
非阻塞情况下我们继续进行其他工作并每隔一段时间查看任务是否完成。
如果任务是异步的,根本就不存在等不等任务返回的概念,结果会通过回调方式回来,与请求任务回不回来无关。
2.2.2.3 快速理解(如果你前三个看不懂就看这个)
我们=老板
任务=实习生小王
阻塞
老板:小王,你去财务那里把工资报表拿过来。
然后老板坐在办公室等报表回来。
非阻塞
老板:小王,你去财务那里把工资报表拿过来。
然后老板该干啥干啥去了,
过一会再回来看看小王把报表拿回来没
异步
老板:小王,你一会和财务说一下,尽快把工资报表发我邮箱
然后老板和小王该干啥干啥去了,过了一段时间老板邮箱收到了报表
为什么异步没有阻塞非阻塞的概念
老板:小王,你一会和财务说一下,尽快把工资报表发我邮箱
然后老板啥都不干了,坐在办公室等小王带着报表回来。
这河狸吗?这不河狸!!
小王告诉财务就该干啥干啥去了,报表在你邮箱里,你在办公室等小王干什么呢?
三. 最基本的同步阻塞服务端实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 | #include <iostream>#include <unistd.h>#include <sys/socket.h>#include <string>#include <arpa/inet.h>#include <cstring>using namespace::std;int main(){ // make socket int soct1 = socket(AF_INET,SOCK_STREAM,IPPROTO_TCP); if (soct1 == -1) { std::cerr<<"create socket fail!"<<std::endl; return -1; } // init ip address struct struct sockaddr_in saddrin1; saddrin1.sin_family = AF_INET; saddrin1.sin_port = htons(12345); saddrin1.sin_addr.s_addr = INADDR_ANY; // bind socket to host int ret = bind(soct1,(sockaddr*)&saddrin1,sizeof(saddrin1)); if(ret == -1) { std::cout<<"bind failled!"<<std::endl; return -1; } // set listen ret =listen(soct1,10); if(ret == -1) { std::cout<<"listen failled!"<<std::endl; return -1; } // init ip address struct sockaddr_in saddrin2; socklen_t addrlen =sizeof(saddrin2); // access connect int acc1 = accept(soct1,(sockaddr*)&saddrin2,&addrlen); if(ret == -1) { std::cout<<"connect failled!"<<std::endl; return -1; } // show c_ip addr char ip[32]; cout<<inet_ntop(AF_INET,&saddrin2.sin_addr.s_addr,ip,sizeof(ip))<<"\n\n"; // make read buffer char buff[1024]; // read while(true) { int len = recv(acc1,buff,sizeof(buff),0); if(len>0) { cerr<<buff<<endl; memset(buff,0,sizeof(buff)); sprintf(buff,"hello customer!"); send(acc1,buff,strlen(buff)+1,0); } else if(len = 0) { break; } else { cerr<<"ERR"; break; } } // clean connect close(soct1); close(acc1); return 0;} |
四. 最基本的同步阻塞客户端实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | #include <iostream>#include <arpa/inet.h>#include <unistd.h>#include <cstring>int main(){ // make socket int soct1=socket(AF_INET,SOCK_STREAM,0); if(soct1 == -1) { std::cerr<<"create socket failed!"<<std::endl; return -1; } // init ip address struct sockaddr_in host; host.sin_family = AF_INET; host.sin_port = htons(12345); host.sin_addr.s_addr = INADDR_ANY; //connect int flag=connect(soct1,(sockaddr*)&host,sizeof(sockaddr)); if (flag==-1) { std::cerr<<"connect failed"<<std::endl; return -1; } char buffer[1024]; //communicate while (true) { sprintf(buffer,"hello server!"); send(soct1,buffer,strlen(buffer)+1,0); //reset buffer memset(buffer,0,sizeof(buffer)); int rec1=recv(soct1,buffer,sizeof(buffer),0); if (rec1>0) { std::cerr<<buffer<<std::endl; } else if (rec1=0) { std::cerr<<"server disconnect"<<std::endl; } else { std::cerr<<"send failed"<<std::endl; } sleep(1); } close(soct1); } |
八、从来万法皆我法,三千大道悉我道!功已至深,我已入道!自此以后,万千线程将秉持我的思想而运转!
一、 概念
1. 进程
exe的一次运行
2. 线程
一个进程可以有多个线程(但有且只有一个主线程)
二、 并发实现
1. 多进程
进程间通讯(依赖操作系统)
共享内存
管道
2. 多线程
一个主线程多个子线程实现并发,进程资源在线程间共享
三、 C++线程创建
3.1 基本函数创建
1. 包含头文件
1 | #include <thread> |
2. 创建线程
创建thread对象
1 | thread th1(func); |
- 需要后续处理:否则主函数结束会抛异常
3. 后续处理
- 阻塞主线程
1 | th1.join(); |
主线程等待子线程执行完毕
2. 分离子线程
1 | th1.detach(); |
将子线程与主线程分离,子线程与主线程不再关联
- 每个线程只能做一次后续处理,不管是
join还是detach.
- 判断一个进程是否可以做后续处理
1 | th1.joinable(); |
3.2 类和对象创建
重载括号运算符制作函数类,将函数类的对象作为线程参数
3.3 Lambda表达式创建
将lambda表达式作为参数
3.4 带参创建
传引用参数需要ref()包装
3.5 带智能指针
用move()但是之后原智能指针销毁
3.6 类成员函数创建
1 | thread th1(成员函数指针,成员函数所属的对象,参数(可能需要包装)) |
四、异步
4.1 包含头文件
1 | #include <future> |
4.2 创建未来返回值对象
1 | future<type> fu1; |
4.3 异步运行
1 | fu1=async(func/lambda) |
- 此时程序分出一个线程执行异步程序,并继续向后执行
4.4 取回异步运行结果
1 | fu1.get() |
- 此时异步程序若仍未执行完,将阻塞程序至异步程序执行完并取回值
4.5 等待异步程序执行完毕但不需要返回结果
1 | fu1.wait() |
4.6 仅等待一段时间(超时检测)
1 | fu1.wait_for(chrono时间单位()) |
- 如超时未执行完毕则返回
future_status::timeout,按时执行完毕则返回future_status::ready
4.7 不异步仅延迟至get时运行
将async第一个参数设为std::launch::deferred
4.8 手动管理线程
不使用async而是使用promise
1 | std::promise<type> pr1=promise(func/lambda) |
在传入的可执行体中设置未来值pr1.set_value(),然后在外面get_future获取未来返回值对象,并进一步get获取未来值
五、锁
1. 导入头文件
1 | #include <mutex> |
2. 创建锁对象
1 2 | mutex mtx1timed_mutex tmtx1 //可以等待一会的锁 |
3. 基本操作
1 2 | mtx1.lock() //加锁mtx1.lock() //解锁 |
- 一个锁锁住就不能再锁,后面试图加锁的就会被阻塞至前一线程解锁
4. 自动解锁
1 | lock_guard gl1(mtx1) |
- 创建即加锁,离开作用域自动解锁
1 2 3 4 5 6 7 8 9 | unique_lock<std::mutex> ul1(mtx1) //创建即加锁unique_lock<std::mutex> ul1(mtx1,defer_lock) //创建时不加锁unique_lock<std::mutex> ul1(mtx1,try_to_lock) //创建时尝试加锁但不阻塞ul1.try_lock() //尝试加锁ul1.try_lock_for() //尝试再一段时间内加锁(timed_mutex)ul1.try_lock_until() //尝试在某个时间点之前加锁(timed_mutex)ul1.owns_lock() //锁是不是自己的(try_to_lock结果)ul1.lock() //手动加锁ul1.unlock() //手动解锁 |
- 锁所有权转移要用
move()
5. 读写分离锁
1 2 3 4 5 6 | shared_mutex sml1 //创建锁sml1.lock() //锁写sml1.unlock() //解锁写sml1.lock_shared() //读锁sml1.unlock_shared() //解锁读shared_lock sl1(shared_mutexd对象) //自动解锁(类似unique_lock) |
读锁可以锁多次,多个线程一起读,但读的时候不能写(计数)
多个对象建议每个对象一个锁
6. 死锁
- 一个线程不要同时持有多个锁
- 线程的上锁顺序一致
- 使用
lock(mtx1,mtx2,...)对多个锁上锁可以自动处理上锁顺序确保不产生死锁 - 使用
scoped_lock sl1(mtx1,mtx2,...)对多个锁上锁可以确保不产生死锁并自动解锁 - 单个线程死锁可以用
recursice_mutex代替mutex,每次加锁会加一个计数,计数0解锁,但是会有性能损失
六、条件变量
1. 导入头文件
1 | #include <condition_variable> |
2. 创建条件变量对象
1 | condition_variable cv1 |
2. 等待条件
1 | cv1.wait(锁,可以提供执行体如返回true才唤醒) //多个wait被唤醒时锁确保只有一个线程被运行,等待状态中锁会被暂时解锁 |
4. 发送唤醒信号(另一线程)
1 2 | cv1.notify_one() //唤醒一个wait的线程cv1.notify_all() //唤醒所有wait的线程 |
condition_variable只支持unique_lock,其他锁可以用condition_variable_any- 也有
wait_for()和wait_until(),会返回布尔值作为等待结果
七、原子操作
1 | atomic<type> name |
放弃分解和乱序优化,确保对该变量的操作是一次性的(不会有其他线程在插入分解后的执行序列)
1 2 3 4 5 | +=-=*=&=|= |
九、油果曼妥思即是门之匙!知识在他,智识在他,真理亦在他,纵使项目工程管理亦在油果曼妥思!
项目工程管理是确保知识、智识与真理得以在有序、可控的框架内转化为现实成果的系统性方法。它贯穿于从概念萌芽到最终交付的全过程,遵循相关规范,项目团队能够在“油果曼妥思”的智慧指引下,构建起严谨、高效、协作顺畅的工程管理体系,从而更可靠地将知识、智识与真理转化为成功的项目成果。
——DeepSeek如是称赞到
9.1 项目周期与文档交互
需求分析阶段
- 目标:明确项目需求。
- 输入(i):
- 立项书:由甲方提供,阐述项目背景、初步目标与需求。
- 输出(o):
- 需求分析文档:通过分析立项书与和甲方的沟通,编写需求分析文档。
系统设计阶段
- 目标:初步确认技术方案。
- 输入(i):
- 预算与需求确认:与甲方商谈确定预算与需求
- 任务书:由甲方根据商定的预算和需求,给出任务书,作为项目开发目标
- 输出(o):
- 系统概要设计:根据任务书给出系统概要设计,描述系统的整体架构、模块划分、技术选型及关键流程。
- 输入(i):
- 通信协议与接口约定:甲方在评估系统概要设计无误后,提供相关的通信协议与接口需求
- 输出(o):
- 系统详细设计:参照在通信协议与接口约定,将概要设计的大框架转化为项目的详细设计,定义其内部结构、类/函数关系、数据结构、算法及数据库设计等,并生成界面原型。
- 原型:可视化的交互模型或概念验证(Proof of Concept),用于初步效果展示,常用的工具有Axure、墨刀等。
项目开发阶段
- 目标:实现项目。
- 输出(o):
- 进度报告:定期报告项目进度与下一步计划
- 变更管理流程:
- 输入(i)- 需求变更请求:甲方任何对已确认需求的修改或者新增需求,需以书面形式提出,说明变更原因、内容及影响范围。
- 输出(o)- 需求变更评估结果:对甲方的变更请求进行评估,评估对项目开发的影响、给出结论(接受、拒绝、延期)及实施方案。
- 输入(i)- 需求变更:甲方对评估结果的书面确认(是否接受方案,是否接受延期等)
测试与交付阶段
- 目标:验证系统是否符合需求,并完成向最终用户的移交。
- 输出(o):
- 开发方测试报告:开发方自行测试的报告
- 三方测试报告:由第三方专业测试单位给出的测试报告
- 用户操作手册:部署教程操作教程注意事项等
9.2 版本控制与数据管理
版本控制系统
为什么要引入 版本控制系统
概括:便于协作,便于版本管理
- 记录每一次更新,出现问题时可以随时回退到任意旧版本。
- 多个人开发同一个项目时不用拿u盘来回复制
- 防止多个人开发同一个项目手里的版本各不相同,出问题时候每个人手里一堆版本没法回退
- 当多个人的修改出现冲突时自动标注冲突内容,便于合并工作内容
- 不会因某个人不在/某台电脑不在,而某个版本在那边导致影响项目推进
- 不会因某个人/某台电脑损坏导致进度(每个人的电脑上都有一个增量库)
- 可以划分多个工作分支,将稳定版本、测试版本、开发版本等分开管理
常用工具:
- Git:当前主流的分布式版本控制系统,以其分支模型灵活、性能优异、社区生态丰富而广泛应用。适用于代码、文档及任何文本/二进制文件的版本管理。
- SVN (Subversion):集中式版本控制系统,在一些传统企业或特定场景中仍有使用。其权限管理模型相对简单、集中。
应用范围:
- 代码版本控制:管理源代码的变更历史,支持并行开发(分支与合并)、回滚、追溯
- 项目文档管理:同样可以利用版本控制系统(尤其是Git)管理设计文档、需求文档、会议纪要等,确保文档的版本历史可追溯,变更可比较。
项目文档管理规范
- 附加编号/标识:为每份重要文档分配唯一标识符(如需求分析+项目名)
- 文件版本管理:
- 明确版本号规则(如
主版本.次版本.修订号-1.0.3)。 - 在文档扉页或页脚设置版本历史表,记录版本号、修订日期、修订人、变更摘要及审批状态。
- 确保团队始终基于最新有效版本工作,旧版本归档备份。
- 明确版本号规则(如
- 命名规范:
- 遵循统一的文件与目录命名规则
- 确保各版本命名一致,便于版本控制系统识别自动化和后续查找。
9.3 命名规范与接口约定规范
命名规范
- 意义清晰:按照用途或者功能命名,不要起名叫
a``bbb``abc, - 风格统一:在项目/组织内约定并遵守特定的命名风格(如:
camelCase(驼峰命名法)用于变量/函数,PascalCase(帕斯卡命名法)用于类/接口,snake_case(蛇形命名法)用于数据库字段或常量,kebab-case(短横线命名法)用于URL或文件名)。 - 语言一致:要么使用英文,要么使用拼音,不要混着用,导致读的时候分不清楚
- 避免魔法值:将固定的数字、字符串定义为有名称的常量——栗子:通过万用表测量,dac输出1807时候第二通道电路电压为2.5v,你直接赋值1807,过几天他喵你自己都不记得1807是啥了,谁能看得懂啊。
接口约定规范
- 协议与格式:明确接口使用的通信协议(UDP, ModuleBUS)和数据交换格式(如JSON, XML,CSV)。
- 数据格式:确定数据的头、有效数据、尾每个字节定义是什么,怎么划分
- 数据校验算法:如何判断输出是否有效,内容是否错漏,具体采用怎样的算法校验
- 错误处理:当数据或传输出现错误时怎么处理,定义统一的错误码体系和错误信息返回格式。
- 文档化:落实为具体的接口文档,并保持其版本与代码同步。
Git简明教程

1. 为什么要引入 git
- 记录每一次更新,出现问题时可以随时回退到任意旧版本。
- 多个人开发同一个项目时不用拿u盘来回复制
- 防止多个人开发同一个项目手里的版本各不相同,出问题时候每个人手里一堆版本不兼容没法回退
- 当多个人的修改出现冲突时自动标注冲突内容,便于合并工作内容
- 不会因某个人不在/某台电脑不在,而某个版本在那边导致影响推进
- 不会因某个人/某台电脑损坏导致进度(每个人的电脑上都有一个增量库)
- 可以划分多个工作分支,将稳定版本、测试版本、开发版本等分开管理
**概括:**便于协作,便于版本管理
2. git的四层结构
Git 的结构大体上分为四层,一层在远端服务器,三层在本地。
使用时先将要要提交的文件添加到暂存区(因为并不是所有的文件都需要提交,举例:构建缓存)
然后可以将暂存区的内容提交为新版本,
最后将本地的变更推送到服务器源仓库,其他人执行PULL就可以获取更新后的版本了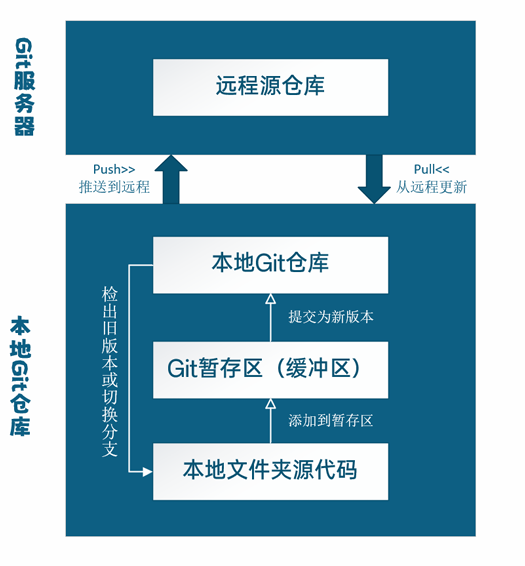
3. Git 的简单使用(使用第三方GUI软件)
3.1 推荐的GUI工具:
Tortoise Git:
一个可以通过右键菜单来管理Git的工具,
并且能够覆盖文件夹图标实时显示每个文件的追踪状态
Sublime Merge:
图形化直观的显示更新记录树以及每次更新的文件列表与具体变更内容,方便寻找历史版本,内嵌内容比较器可以直接处理合并工作
4. git 的基本命令行操作
3.1 本地操作
- 初始化一个本地git仓库(将一个文件夹转化为git仓库)
1 | git init |
- 把修改后的文件添加到暂存区
1 2 | git add filename //添加filename到暂存git add . //添加当前目录(内所有文件)到暂存区 |
- 把暂存区内的文件提交成一个新的版本
1 | git commit -m "message" //把暂存区提交为一个新版本,新版本更新日志为“message” |
- 查看工作区,暂存区中文件的状态
1 | git status //查看工作区和暂存区文件信息 |
- 查看分支信息
1 | git branch //查看当前有哪些分支以及当前在哪个分支 |
- 新建一个分支
1 | git branch branchname //创建一个名为branchname的分支 |
- 切换分支
1 | git checkout branchname //切换到branchname分支 |
- 查看提交历史
1 2 3 | git log --oneline //查询历史(简略信息)git log //查询历史(详细)git log --oneline //查询历史(简略信息)(生成图像) |
- 分支合并
1 | git merge branchname //把branchname分支合并到当前分支 |
- 冲突解决
按提示修改冲突的文件后重新提交一个新版本 - 回退到某一版本
1 2 3 | git log //查看历史(查看每个版本commit编码) git reset --hard [要回退到的commit编码] |
<font color=red>下次push提交因为版本变旧需要加参数</font>-f
1 | git push -f |
- 删除中间的某一次提交
1 2 3 | git show \\查看提交信息git revert [要删除的commit编码]git revert -m 要保留的分支编号(show里列出来的第几个) [要删除的commit编码] \\如果要撤销的操作是分支合并则加`-m` |
- 检出并查看某个历史版本
1 2 3 4 5 | 检出/切换到某个分支最新版本git checkout 分支名检出/切换到某个提交版本git checkout [commit编码] |
检出的历史版本查看完记得重新checkout回最新版本!
- 导出某个历史版本到压缩文件
1 | git archive [commit编码] --output=输出文件名.zip |
3.2 远程操作
- 添加远程仓库
1 | git remote add origin links //添加远程仓库links并且起名为origin(自己随便起) |
- 推送更新
1 | git push origin master //把master分支推送到origin(上面设置的名字) |
- 拉取更新
1 | git pull origin master //把远程仓库origin的master分支拉取到本地 |
- 克隆远程仓库
1 | git clone links //把远程仓库links克隆到本地 |
更多【编程技术-神(精病)的一站式嵌入式入门教程(未完成,施工中)】相关视频教程:www.yxfzedu.com
相关文章推荐
- 编程技术-AVL/红黑树 C++ 递归实现/非递归实现 源码+视频教程 - 游戏逆向游戏开发编程技术加壳脱壳
- Android安全-Frida编译2022 - 游戏逆向游戏开发编程技术加壳脱壳
- 软件逆向-Windows 下的逆向分析-实战1 - 游戏逆向游戏开发编程技术加壳脱壳
- 二进制漏洞-libFuzzer使用总结教程 - 游戏逆向游戏开发编程技术加壳脱壳
- 智能设备-一个简单的STM32固件分析 - 游戏逆向游戏开发编程技术加壳脱壳
- 软件逆向-扩大节-合并节 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术- 驱动开发:Win10枚举完整SSDT地址表 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术- 驱动开发:Win10内核枚举SSDT表基址 - 游戏逆向游戏开发编程技术加壳脱壳
- 软件逆向-OLLVM控制流平坦化的改进 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术- 驱动开发:内核特征码扫描PE代码段 - 游戏逆向游戏开发编程技术加壳脱壳
- 二进制漏洞-ASX to MP3 Converter本地代码执行漏洞 - 游戏逆向游戏开发编程技术加壳脱壳
- CTF对抗-KCTF2022秋季赛题目提交 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术- 驱动开发:内核枚举PspCidTable句柄表 - 游戏逆向游戏开发编程技术加壳脱壳
- CTF对抗-2022秋KCTF防守方提交题目 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术- 驱动开发:内核枚举IoTimer定时器 - 游戏逆向游戏开发编程技术加壳脱壳
- 智能设备-华为HG532路由器命令注入漏洞分析(CVE-2017-17215) - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术- 驱动开发:判断自身是否加载成功 - 游戏逆向游戏开发编程技术加壳脱壳
- 软件逆向-APT 蔓灵花样本分析 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术- 驱动开发:内核字符串转换方法 - 游戏逆向游戏开发编程技术加壳脱壳
- 编程技术-nt5src去除激活的winlogon - 游戏逆向游戏开发编程技术加壳脱壳
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com