软件逆向-刺杀vmp3.9.4混淆
推荐 原创【软件逆向-刺杀vmp3.9.4混淆】此文章归类为:软件逆向。
前言
实际上我想研究的工作是借助符号执行来完成vmp虚拟机里各 handler 的语义识别,不使用以往传统上的指令特征识别方法(而且现在的vmp似乎实现了单个 handler 里集成多个虚拟机操作原语的特性,这也导致根据特征识别到的 handler 的语义是不全面的),但是在分析 trace 中,还是会因为看到一大片被混淆后的指令数据而感到十分头大,因此一步步来,先把混淆解了再说。这些便是我写下此篇文章的动机,希望对大家能有所帮助。
使用工具
然后我依旧用到了自写的 x64dbg 插件 supertrace 和 supertrace-pybind 来生成信息更全面的 trace 数据以进行分析工作。
已观察到的混淆方式
分析观察被 vmprotect 3.9.4 保护的样本的trace,我主要发现了以下混淆手段:
- 垃圾代码
垃圾代码指的是前面一些指令执行所写入的寄存器或内存数据被后续指令的写入所覆盖,而这些数据直到下一次被覆盖前都没有任何的引用。这个就不必多说了,最稳定也是最经典的一种混淆手段。
mov eax, 0x66 add eax, ebx mov eax, 0x77
- 代码空间局部性混乱(或者也可以叫代码乱序)
指的是把本来好好的一块基本块硬生生地分割成两份基本块,并用直接控制流转移指令(如 jmp imm 或 call imm 指令)将其按顺序连接起来。这样达到的效果就是你在调试器里会看到rip寄存器左右反复横跳,上上下下左右左右BABA。
vmp里大量运用了此手段,并且还会搭配下面所说的永真永假型不透明谓词来强化混淆效果。
code A code B code C ...... ==> jmp labelA labelB: code B jmp labelC labelC: code C jmp next labelA: code A jmp labelB next: ......
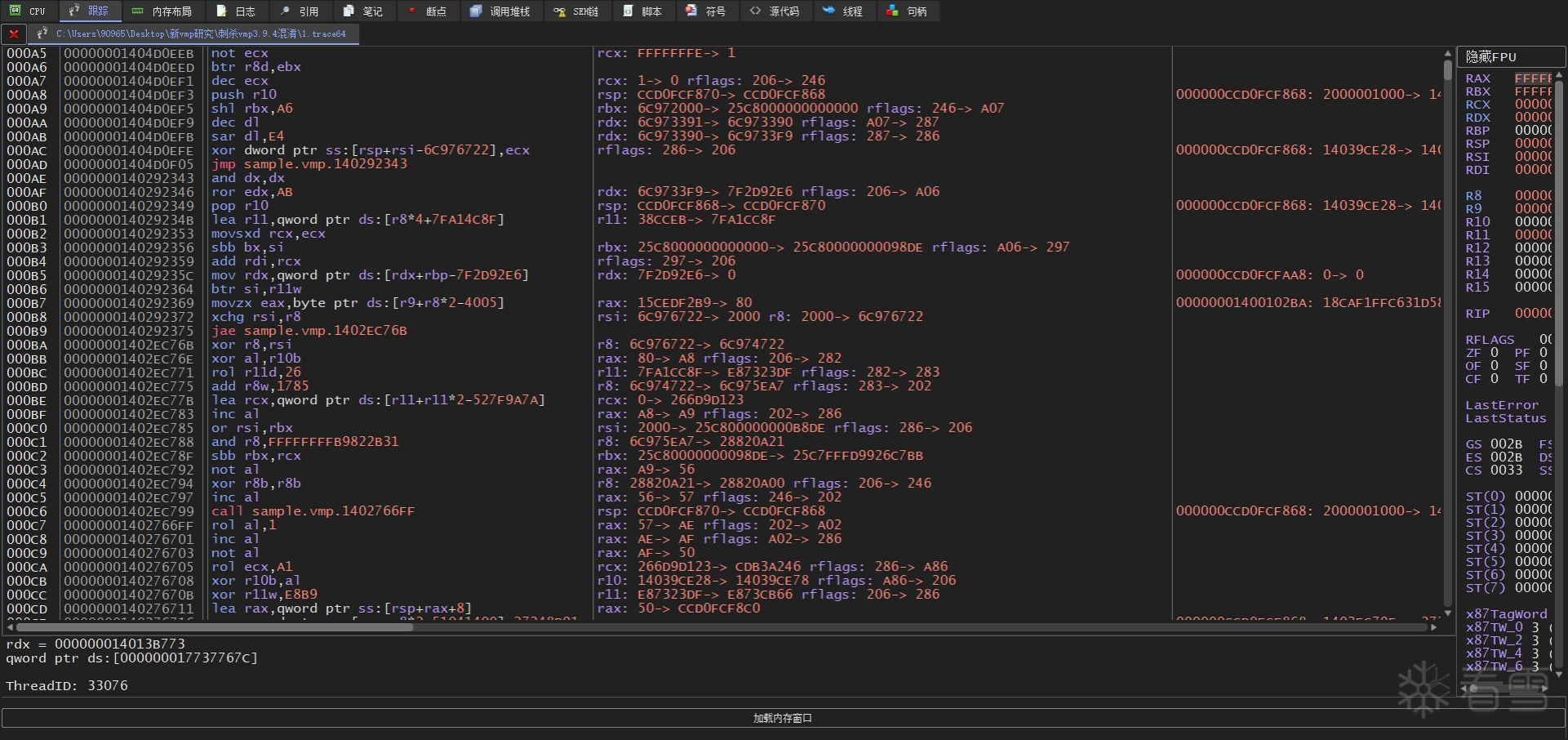
为了打字方便,我在下文都称其为 "代码乱序"
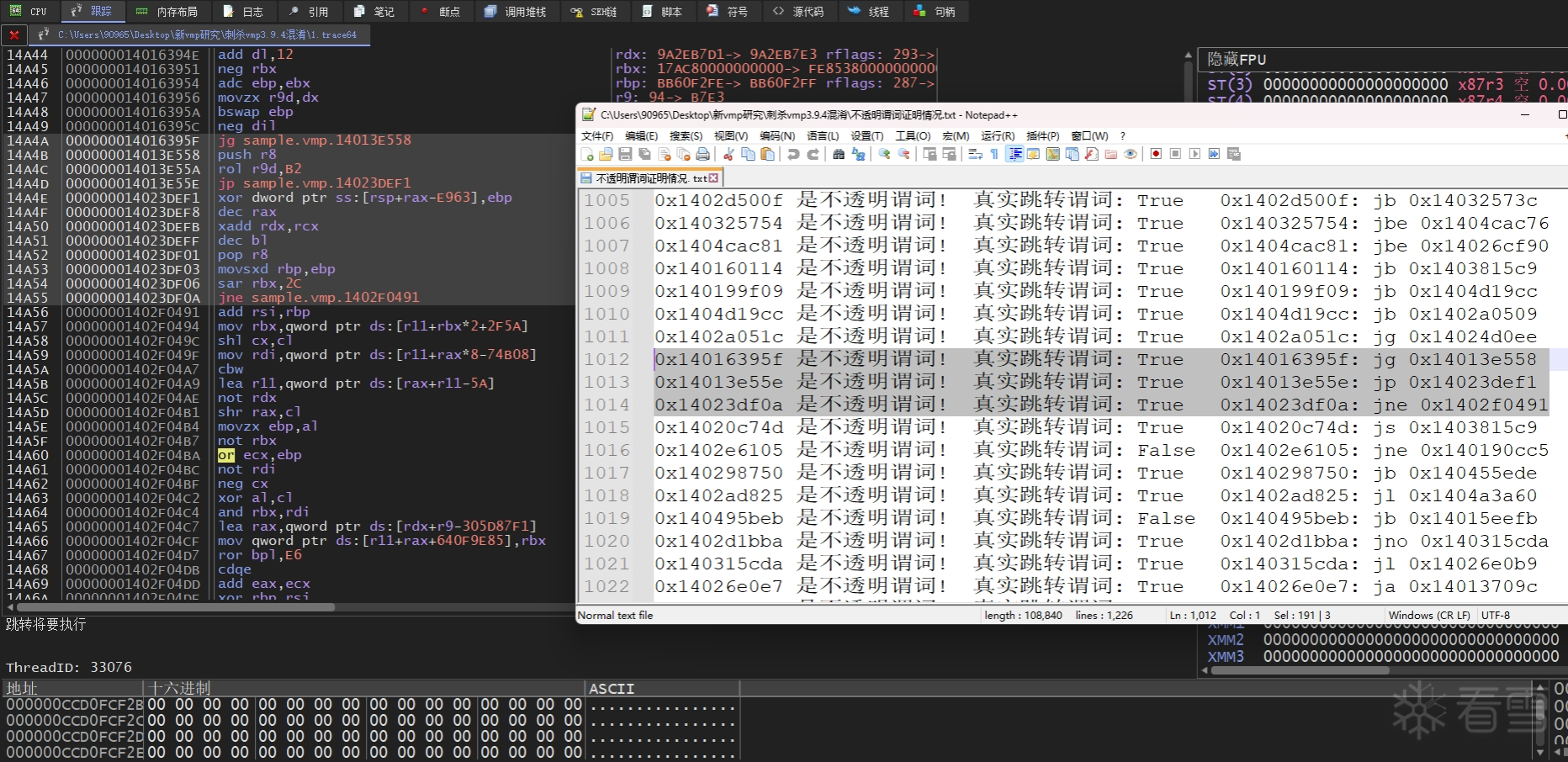
- 不透明谓词(永真永假型)
所谓不透明,就是对方难以推断的。不透明谓词就是代码的编写者知道是真是假是什么,但是攻击者难以从字面获悉。
vmp的不透明谓词采用的形式是永真永假型。然后观察发现并未使用到可真可假型的不透明谓词(不过我听说旧版本的vmp曾用过)。
所谓"永真永假型",指的是基本块里 jcc 指令的跳转事实从未发生改变,即要么跳转,要么不跳转,不存在有时会跳有时不会跳的情况(本质上讲就是跳转条件要么恒成立要么恒不成立)。
构造永真永假型的不透明谓词有两种形式,一种是跳转条件全是基于一系列常量合成。因为都是常量,所以跳转条件表达式的最终结果肯定也是恒不变的。
1 2 3 4 5 6 7 8 9 10 11 | /*5203 + 3 == 6256 ^ 127 != 382......*/if (cond) { // 正确的代码块} else { // 永不执行的代码块,若是执行必出错} |
另一种是代入用户可控变量到跳转条件表达式中,在表达式里,无论用户变量取值为多少,表达式的整体运算最终结果是恒不变的。
1 2 3 4 5 6 7 8 9 10 | /*x * (x + 1) % 2 == 0pow(x, 2) + pow(y, 2) >= 2*x*y // 高中学过的基本不等式......*/if (cond) { // 正确的代码块} else { // 永不执行的代码块,若是执行必出错} |
- 内存操作数常量隐藏混淆
vmp是基于栈的虚拟机,那么对于栈的访问以及从vm区块里读取虚拟机字节码,肯定会产生非常多的内存访问操作。然而vmp(这个混淆手法好像是在 3.8 以上的时候开始引入的)会在本来正常的内存访问操作数里插入一堆复杂的数值,并用寄存器来表示出来,例如 qword ptr ss:[rsp] 被变换成 qword ptr ss:[rsp + rdx - 0x76B2378A](rdx 此时为 0x76B2378A)。
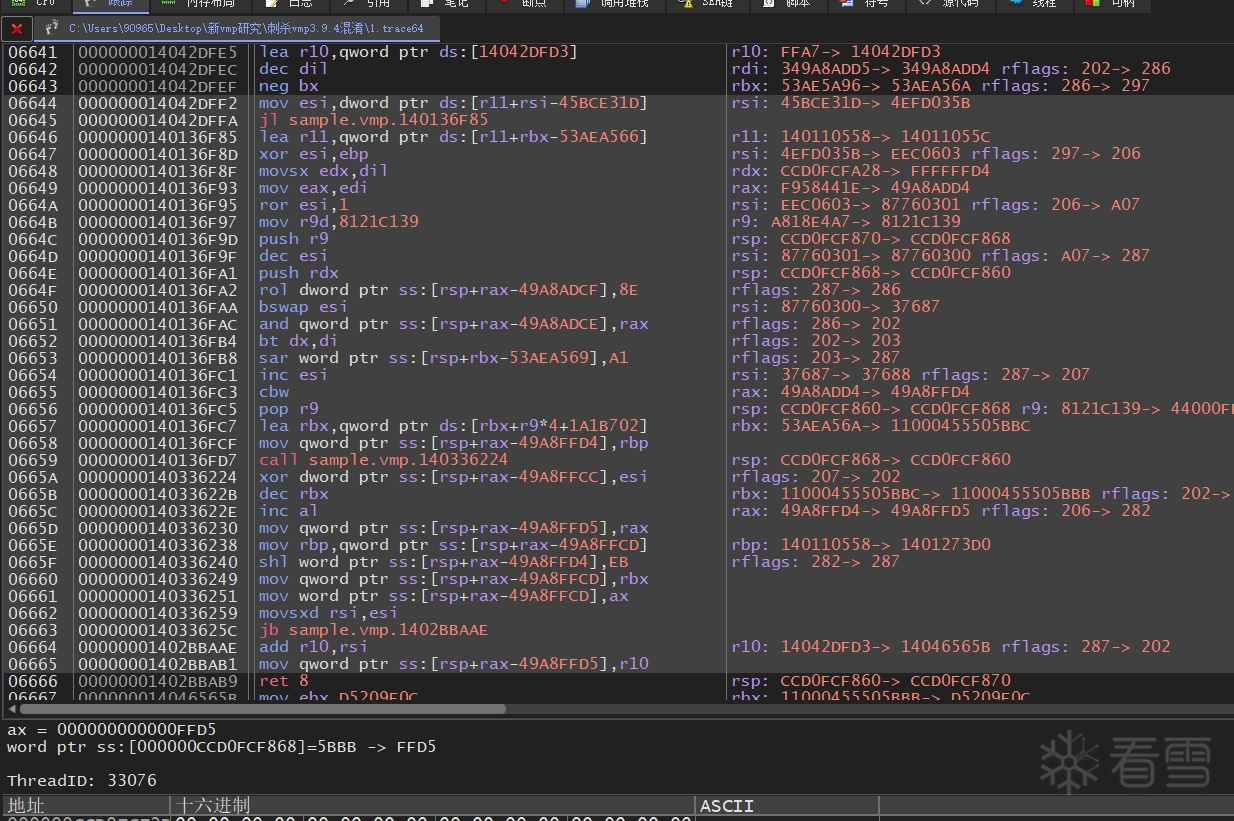
也就是说,vmp在内存操作数里引入的 index 寄存器或 base 寄存器都是已知量,进一步观察发现,这些数值都是从执行过的上部分指令的 imm 里一步步计算过来的。
任意一个常量的计算过程(针对 rax 的反向切片):
0663B | 000000014042DFC2 | mov rbx,0 rbx: 0000FFFFFFFFFFFF -> 0000000000000000 0663E | 000000014042DFD3 | mov ebx,53AE5A96 rbx: 0000000000000000 -> 0000000053AE5A96 0663F | 000000014042DFD8 | lea rdi,qword ptr ds:[rbx+rbx*8+58877E8F] rdi: 000000000000001F -> 0000000349A8ADD5 rbx: 0000000053AE5A96 06642 | 000000014042DFEC | dec dil rdi: 0000000349A8ADD5 -> 0000000349A8ADD4 06649 | 0000000140136F93 | mov eax,edi rax: 00000000F958441E -> 0000000049A8ADD4 rdi: 0000000349A8ADD4 0664F | 0000000140136FA2 | rol dword ptr ss:[rsp+rax-49A8ADCF],8E rax: 0000000049A8ADD4 rsp: 000000CCD0FCF860
- MBA混淆
将简单的表达式转换成复杂的算术糅合布尔运算的表达式,这个也不必多说了,数据流混淆的经典手段。
vmp里的万用门计算就大量运用了这种混淆手法。
1 2 3 4 5 6 7 | examples:x + y == (x | y) + y - (~x & y)x ^ y == (x | y) - y + (~x & y)x ^ y == (x & ~y) | (~x & y)x | y == (x ^ y) + y - (~x & y)x & y == -(x | y) + y + x...... |

- 间接跳转混淆
指的是间接跳转指令的目标地址实际上是已知的且目的地只有一处。vmp破坏了call指令的通俗使用约定(调用call指令会在栈中传入位于该call指令的下一条指令的地址,也就是返回地址,一般而言函数调用结束后会根据保存在 [rsp] 的返回地址通过retn指令返回到call调用处),它会从栈中取出返回地址并进行一系列运算,而后得到一个真正的目标地址,然后再跳转过去。

当然实际上vmp的间接跳转混淆也可以算是上面所讲到的代码乱序,因为call指令从语义上讲也是相当于入栈返回地址并修改 rip,即 push retAddr; jmp targetAddr
- 等价语义指令替换
在保持语义一致的前提下,将指令替换成另一条复杂的指令(或者是不太常见的指令)。比如 push rax 可被替换成 lea rsp, qword ptr ss:[rsp - 8]; mov qword ptr ss:[rsp], rax,mov rax,5 可被替换成 or rax,5(rax 必为 0)或 add rax,5(rax 必为 0)
第一个例子之所以用
lea rsp, qword ptr ss:[rsp - 8]而不用sub rsp, 8,是因为应用后者的话会额外引入修改标志位的语义行为,这就体现我们所说的要保持语义一致的说法,当然在实际中我们也可以视具体情况而选择忽略。第二个例子也同理。

校验反混淆效果的方法
稳定性检查: 既然我们要做反混淆,就肯定得想办法检查反混淆后的新代码是否还能正常工作。我的做法是首先关掉vmp的内存保护,将反混淆后的新指令覆盖掉原先的混淆指令,看最后程序是否能正常运行。
可靠性检查: 反混淆后手动观察代码是否还存在未被反混淆的指令,如果重新看到了混淆指令,就说明反混淆效果存在欠缺。
准备工作
还是在vs2022 用 release x64编译以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | #include <iostream>#include <Windows.h>#include "VMProtectSDK.h"void test(unsigned x) { VMProtectBegin("secret"); if (x == 0xDEADBEEF) { // 3735928559 MessageBoxA(NULL, "DEADBEEF", "", MB_OK); } VMProtectEnd();}int main(int ac, const char* av[]) { unsigned x = 0; printf("x: "); scanf("%d", &x); test(x); return 0;} |
然后用vmp 3.9.4进行加壳保护,参数如下:
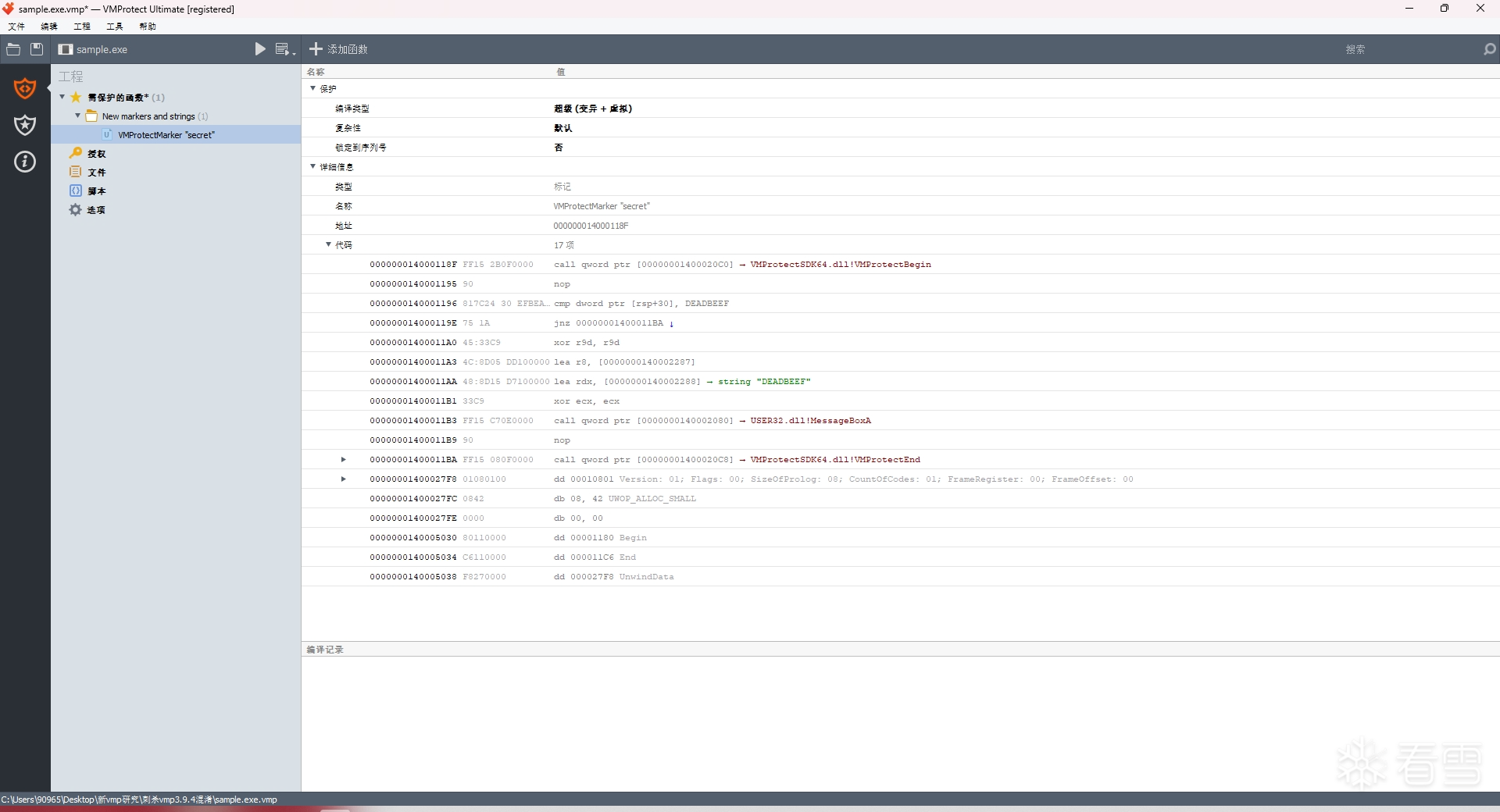
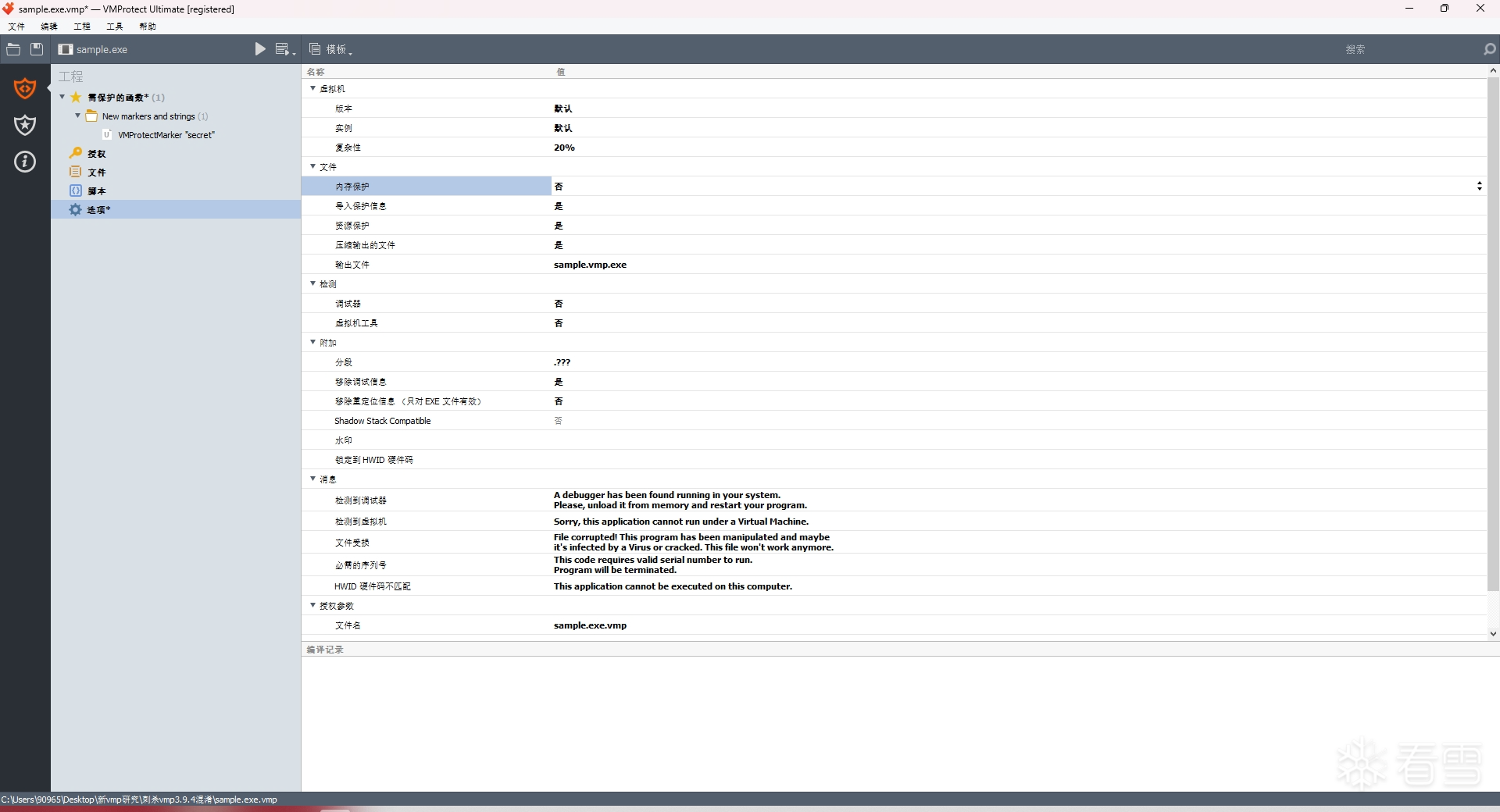
然后使用 x64dbg 的追踪功能来记录被vm函数的完整指令追踪记录,先找到vm函数,在vm函数的开头和结尾处下断点,然后开启x64dbg的跟踪,等到结尾处的断点被命中后就可以关闭跟踪得到完整的trace文件。
接下来就开始写代码了,先把trace信息读进来
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 | import tritonimport keystoneimport SupertracePybind as Supertracefrom enum import Enumfrom collections import defaultdictimport graphvizfrom miasm.arch.x86.arch import mn_x86from miasm.expression.expression import ExprMem, ExprId, ExprInt, ExprOpfrom supertrace_util import initTritonCtxEnv, mergeRepeatIns, checkIndirectInsks = keystone.Ks(keystone.KS_ARCH_X86, keystone.KS_MODE_64)def asmDecode(CODE: bytes, addr = 0) -> bytes: try: encoding, count = ks.asm(CODE, addr, True) if (count <= 0): raise keystone.KsError return bytes(encoding) except keystone.KsError as e: print("ERROR: %s" %e) return b""tracepath = "1.trace64" # 读取trace文件trace = Supertrace.parse_x64dbg_trace(tracepath)record = trace.getRecord()print(f"trace instruction num: {len(record)}")'''trace instruction num: 110684'''ctx = triton.TritonContext()ctx.setArchitecture(triton.ARCH.X86_64)ctx.setMode(triton.MODE.ALIGNED_MEMORY, True)ctx.setMode(triton.MODE.AST_OPTIMIZATIONS, True)ctx.setMode(triton.MODE.CONSTANT_FOLDING, True)def newLiftDot(expr_node) -> str: temp_ctx = triton.TritonContext() temp_ctx.setArchitecture(ctx.getArchitecture()) return temp_ctx.liftToDot(expr_node)def initTritonCtxEnvSym( ctx: triton.TritonContext, init_refer_ins: Supertrace.InstructionRecord, teb_addr: int, symbolizeDF: bool = False, symbolizeTF: bool = False, symbolizeIF: bool = False): initTritonCtxEnv(ctx, init_refer_ins, teb_addr) # 初始化具体化环境 regs = ctx.registers if (ctx.getArchitecture() == triton.ARCH.X86): init_regdump = init_refer_ins.reg_dump32 elif ctx.getArchitecture() == triton.ARCH.X86_64: init_regdump = init_refer_ins.reg_dump64 else: print("unsurport arch") # 符号化所有寄存器 for ttreg in ctx.getAllRegisters(): ctx.symbolizeRegister(ttreg, ttreg.getName()) # 平坦模型 ctx.setConcreteRegisterValue(ctx.registers.ss, 0) ctx.setConcreteRegisterValue(ctx.registers.ds, 0) ctx.setConcreteRegisterValue(ctx.registers.es, 0) ctx.setConcreteRegisterValue(ctx.registers.cs, 0) if ctx.getArchitecture() == triton.ARCH.X86: ctx.setConcreteRegisterValue(ctx.registers.esp, init_regdump.regcontext.csp) ctx.setConcreteRegisterValue(ctx.registers.eip, init_regdump.regcontext.cip) ctx.setConcreteRegisterValue(regs.fs, teb_addr) ctx.setConcreteRegisterValue(regs.gs, 0) # 平坦模型 elif ctx.getArchitecture() == triton.ARCH.X86_64: ctx.setConcreteRegisterValue(ctx.registers.rsp, init_regdump.regcontext.csp) ctx.setConcreteRegisterValue(ctx.registers.rip, init_regdump.regcontext.cip) ctx.setConcreteRegisterValue(regs.fs, 0) # 平坦模型 ctx.setConcreteRegisterValue(regs.gs, teb_addr) if (symbolizeDF): ctx.setConcreteRegisterValue(ctx.registers.df, init_regdump.flags.d) if (symbolizeTF): ctx.setConcreteRegisterValue(ctx.registers.tf, init_regdump.flags.t) if (symbolizeIF): ctx.setConcreteRegisterValue(getattr(ctx.registers, "if"), init_regdump.flags.i) ctx.setConcreteRegisterValue(ctx.registers.nt, 0) ctx.setConcreteRegisterValue(ctx.registers.rf, 0) ctx.setConcreteRegisterValue(ctx.registers.id, 0) ctx.setConcreteRegisterValue(ctx.registers.vip, 0) ctx.setConcreteRegisterValue(ctx.registers.vif, 0) ctx.setConcreteRegisterValue(ctx.registers.ac, 0) ctx.setConcreteRegisterValue(ctx.registers.vm, 0)record = mergeRepeatIns(ctx, record, True)print(f"after mergeing 'rep' instructions, trace instruction num: {len(record)}") # 合并trace里的rep指令'''after mergeing 'rep' instructions, trace instruction num: 110684'''threads = trace.user.meta.getThreads()for th in threads: if th.id == record[0].thread_id: main_thread = th breakprint(f"main thread id: {main_thread.id} ({hex(main_thread.id)})")print(f"teb: {hex(main_thread.teb)}")initTritonCtxEnv(ctx, record[0], main_thread.teb)'''main thread id: 33076 (0x8134)teb: 0xccd10d8000''' |
开始反混淆
1. 获取基本块
首先我们需要从trace里获取基本块(我们做反混淆的对象就是基本块),因为是从trace里提取的,按照顺序提取的基本块肯定会有重复的(也就是重复的执行),所以我们用set集合来存储所有的基本块
先定义基本块的类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 | class ST_BasicBlock(): def __init__(self, instructions: list[Supertrace.InstructionRecord]): self.instructions: list[Supertrace.InstructionRecord] = instructions # 针对基本块最后一条指令而言 self.isControlflow: bool = None self.isBranch: bool = None self.isUnconditionalJump: bool = None self.isConditionalJump: bool = None self.isCall: bool = None self.isRet: bool = None self.isDirect: bool = None self.targetAddr: int = None self.fallThroughAddr: int = None # (indirectTargetAddrs 不是正式的控制流意义字段,因为其数据来源于trace而非指令本身,因此按照原则,writeBBControlIns 函数不会处理它) self.indirectTargetAddrs: set[int] = set() def __hash__(self): h: int = 0 for ins in self.instructions: h1 = hash(ins.bytes) h2 = hash(ins.ins_address) h += (h1 + h2) h += hash(len(self.instructions)) return h def __eq__(self, other): if not isinstance(other, ST_BasicBlock): return NotImplemented if (len(self.instructions) != len(other.instructions)): return False for i, ins in enumerate(self.instructions): if (ins.bytes != other.instructions[i].bytes): return False if (ins.ins_address != other.instructions[i].ins_address): return False return True def __repr__(self): return f"<{hex(self.getCurrentAddr())}> insCount: {len(self.instructions)}" def printbb(self): '''打印基本块里的所有指令''' for ins in self.instructions: print(f"{ins}\t{ins.ttins}") def getFirstIns(self) -> Supertrace.InstructionRecord: '''获取基本块的第一条指令''' return self.instructions[0] def getLastIns(self) -> Supertrace.InstructionRecord: '''获取基本块的最后一条指令''' return self.instructions[-1] def getCurrentAddr(self) -> int: '''获取当前基本块的地址''' return self.getFirstIns().ins_address def isReachMe(self, jumpAddr: int) -> bool: '''判断跳转地址是否能进入此基本块''' return jumpAddr == self.getFirstIns().ins_address def findSubIns(self, checkIns: Supertrace.InstructionRecord) -> int: '''如果包含,返回对应的索引位置,否则返回 -1''' for i, ins in enumerate(self.instructions): if (ins == checkIns): return i return -1 def isContainsAddr(self, checkAddr: int) -> int: '''如果包含,返回对应的索引位置,否则返回 -1''' for i, ins in enumerate(self.instructions): if (ins.ins_address == checkAddr): return i return -1 def findSubBasicBlock(self, otherBB) -> int: '''如果包含,返回对应在开头处的索引位置,否则返回 -1''' otherBB: ST_BasicBlock = otherBB if (self == otherBB): # 走上面的 __eq__ 方法 return 0 if (len(self.instructions) < len(otherBB.instructions)): return -1 startIdx = self.findSubIns(otherBB.instructions[0]) if (startIdx == -1): return -1 i = startIdx for otherBBIns in otherBB.instructions: if (self.instructions[i] != otherBBIns): return -1 i += 1 return startIdxdef writeBBControlIns(bb: ST_BasicBlock, ttins: triton.Instruction): bb.isControlflow = False bb.isBranch = False bb.isUnconditionalJump = False bb.isConditionalJump = False bb.isCall = False bb.isRet = False bb.isDirect = False bb.targetAddr = 0 bb.fallThroughAddr = 0 # --------- bb.isControlflow = ttins.isControlFlow() if (bb.isControlflow): ttinsType = ttins.getType() bb.isCall = (ttinsType == triton.OPCODE.X86.CALL) bb.isRet = (ttinsType == triton.OPCODE.X86.RET) bb.isBranch = ttins.isBranch() if (bb.isBranch): bb.isUnconditionalJump = (ttinsType == triton.OPCODE.X86.JMP) bb.isConditionalJump = (not bb.isUnconditionalJump) if (bb.isCall or bb.isBranch): # ret指令绝对不会是直接跳转 ops = ttins.getOperands() bb.isDirect = (len(ops) == 1 and ops[0].getType() == triton.OPERAND.IMM) if (bb.isDirect): immop: triton.Immediate = ops[0] if (ttins.getAddress() == 0): print("[警告] writeBBControlIns(): ttins.getAddress() 为 0") bb.targetAddr = immop.getValue() bb.fallThroughAddr = ttins.getNextAddress()bbs: set[ST_BasicBlock] = set() |
然后我们基本块的填入是这样的,从 record 里依次读取所有记录指令,遇到控制流指令就马上把收集到的记录指令写入到基本块,最后再调用 writeBBControlIns() 来写入基本块的跳转信息(也就是最后一条指令)并追加 bbs 里,由于 bbs 是set集合,python 自动帮我们做了基本块去重处理。(这时候的基本块就不再有 trace 时间的概念了)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | bbinsList: list[Supertrace.InstructionRecord] = []bbQuickDict = {} # 只是提高下性能for i, ins in enumerate(record): ttins = triton.Instruction() ttins.setOpcode(ins.bytes) ttins.setAddress(ins.ins_address) ctx.disassembly(ttins) ins.ttins = ttins bbinsList.append(ins) if (ttins.isControlFlow()): bb = ST_BasicBlock(bbinsList.copy()) if (bb in bbs): find = bbQuickDict[bb.getCurrentAddr()] if (checkIndirectIns(ttins) and (i + 1 < len(record))): # 单独填充 indirectTargetAddrs 的信息 find.indirectTargetAddrs.add(record[i + 1].ins_address) else: writeBBControlIns(bb, ttins) if (checkIndirectIns(ttins) and (i + 1 < len(record))): # 单独填充 indirectTargetAddrs 的信息 bb.indirectTargetAddrs.add(record[i + 1].ins_address) bbs.add(bb) bbQuickDict[bb.getCurrentAddr()] = bb bbinsList.clear()print(f"从trace采集到的基本块数量: {len(bbs)}")'''从trace采集到的基本块数量: 3577''' |
经过上述代码的处理,我们得到了 3577 个基本块。
这里补充下,实际上从 trace 获取基本块可能还会有大基本块包裹小基本块的情况,造成这种现象的原因是有跳转指令指向了某个基本块的内部,这样就必须做基本块拆分的工作,但根据观察(至少对该样本来说),vmp没有这种现象,所以就省略了。
2. 基本块合并
我们可以先画个图来看看反混淆前基本块互相间链接的样子:
先定义"edge"类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | class BBLinkType(Enum): INDIRECT_UNCOND = 0 # 无条件间接跳转 DIRECT_UNCOND = 1 # 无条件直接跳转 DIRECT_COND_TAKEN = 2 # 有条件直接跳转(跳转已发生) DIRECT_COND_NOTTAKEN = 3 # 有条件直接跳转(跳转未发生) DIRECT_FALLTHROUGH = 4 # 顺序接续跳转(用于无控制流指令的基本块) OBF_JUMP = 5 # 混淆跳转class BBLink(): def __init__(self, linkType: BBLinkType, linkAddress): self.type = linkType self.addr = linkAddress def __hash__(self): h: int = 0 h += hash(self.type.name) h += hash(hex(self.addr)) return h def __eq__(self, other): if not isinstance(other, BBLink): return NotImplemented if (other.type != self.type): return False if (other.addr != self.addr): return False return True def __repr__(self): return f"type: {self.type}\taddr: {hex(self.addr)}" |
然后是主要的画图代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 | def drawBBLinkGraph(bbs: set[ST_BasicBlock], createUnkNodeWhenBBInvalid: bool = False): '''createUnkNodeWhenBBInvalid: 检查目标节点是否存在,若不存在则根据此参数创建对应的UNK节点再绘制edge,否则取消edge绘制。''' g = graphviz.Digraph('BasicBlockLinkGraph', graph_attr={'rankdir': 'LR'}) valids = set() # 用于快速检查某一个基本块是否存在 for bb in bbs: node = bb.getCurrentAddr() valids.add(node) g.node(hex(node), label=f'{hex(node)}: {len(bb.instructions)}', color="") precursors = defaultdict(set[BBLink]) # 前驱 successors = defaultdict(set[BBLink]) # 后继 for bb in bbs: current = bb.getCurrentAddr() if (bb.isControlflow): if (bb.isDirect): if (bb.isConditionalJump): # 针对有条件跳转 if not (hasattr(bb, "obfOPStatus") and bb.obfOPStatus == True): # ObfOP 反混淆 taken1 = BBLink(BBLinkType.DIRECT_COND_TAKEN, bb.targetAddr) taken2 = BBLink(BBLinkType.DIRECT_COND_NOTTAKEN, bb.fallThroughAddr) target = set({taken1, taken2}) else: if (bb.obfOPCondTaken): taken = BBLink(BBLinkType.OBF_JUMP, bb.targetAddr) else: taken = BBLink(BBLinkType.OBF_JUMP, bb.fallThroughAddr) target = set({taken}) else: # 针对无条件跳转 到这里的基本块的跳转指令是 jmp imm 或 call imm taken = BBLink(BBLinkType.DIRECT_UNCOND, bb.targetAddr) target = set({taken}) else: # 间接跳转 if not (hasattr(bb, "obfIndirectStatus") and bb.obfIndirectStatus == True): # ObfIndirect 反混淆 target = set() for indirectTargetAddr in bb.indirectTargetAddrs: taken = BBLink(BBLinkType.INDIRECT_UNCOND, indirectTargetAddr) target.add(taken) else: taken = BBLink(BBLinkType.OBF_JUMP, bb.obfIndirectAddr) target = set({taken}) else: # 到这里的基本块是没有控制流指令的 taken = BBLink(BBLinkType.DIRECT_FALLTHROUGH, bb.fallThroughAddr) target = set({taken}) successors[current] = successors[current].union(target) for taken in target: precursors[taken.addr].add(BBLink(taken.type, current)) for succSrc in successors: succDests = successors[succSrc] for succDestTaken in succDests: if (succDestTaken.type == BBLinkType.INDIRECT_UNCOND): color, style = "blue", "dashed" elif (succDestTaken.type == BBLinkType.DIRECT_UNCOND): color, style = "blue", "solid" elif (succDestTaken.type == BBLinkType.DIRECT_COND_TAKEN): color, style = "green", "solid" elif (succDestTaken.type == BBLinkType.DIRECT_COND_NOTTAKEN): color, style = "red", "solid" elif (succDestTaken.type == BBLinkType.DIRECT_FALLTHROUGH): color, style = "grey", "solid" elif (succDestTaken.type == BBLinkType.OBF_JUMP): color, style = "pink", "solid" else: raise RuntimeError() if (succDestTaken.addr in valids): # 只画后继线条 g.edge(hex(succSrc), hex(succDestTaken.addr), color=color, style=style) else: if (createUnkNodeWhenBBInvalid): g.edge(hex(succSrc), hex(succDestTaken.addr), color=color, style=style) g.node(hex(succDestTaken.addr), label=f'UNK_{hex(succDestTaken.addr)}', color="red") return g |
我们规定以下线条样式:
- 间接无条件跳转(如 call reg、jmp reg)是 蓝色虚线
- 直接无条件跳转是(如 jmp imm、call imm) 蓝色实线
- 决定跳转的直接分支跳转是(跳转的 jcc) 绿色实线
- 决定不跳转的直接分支跳转是(不跳转的 jcc) 红色实线
- fallthrough是 灰色实线
- 被证实为混淆的跳转是 粉色实线

瞧瞧这,实在是太大了,所以这里我们只截取几张局部的来看:
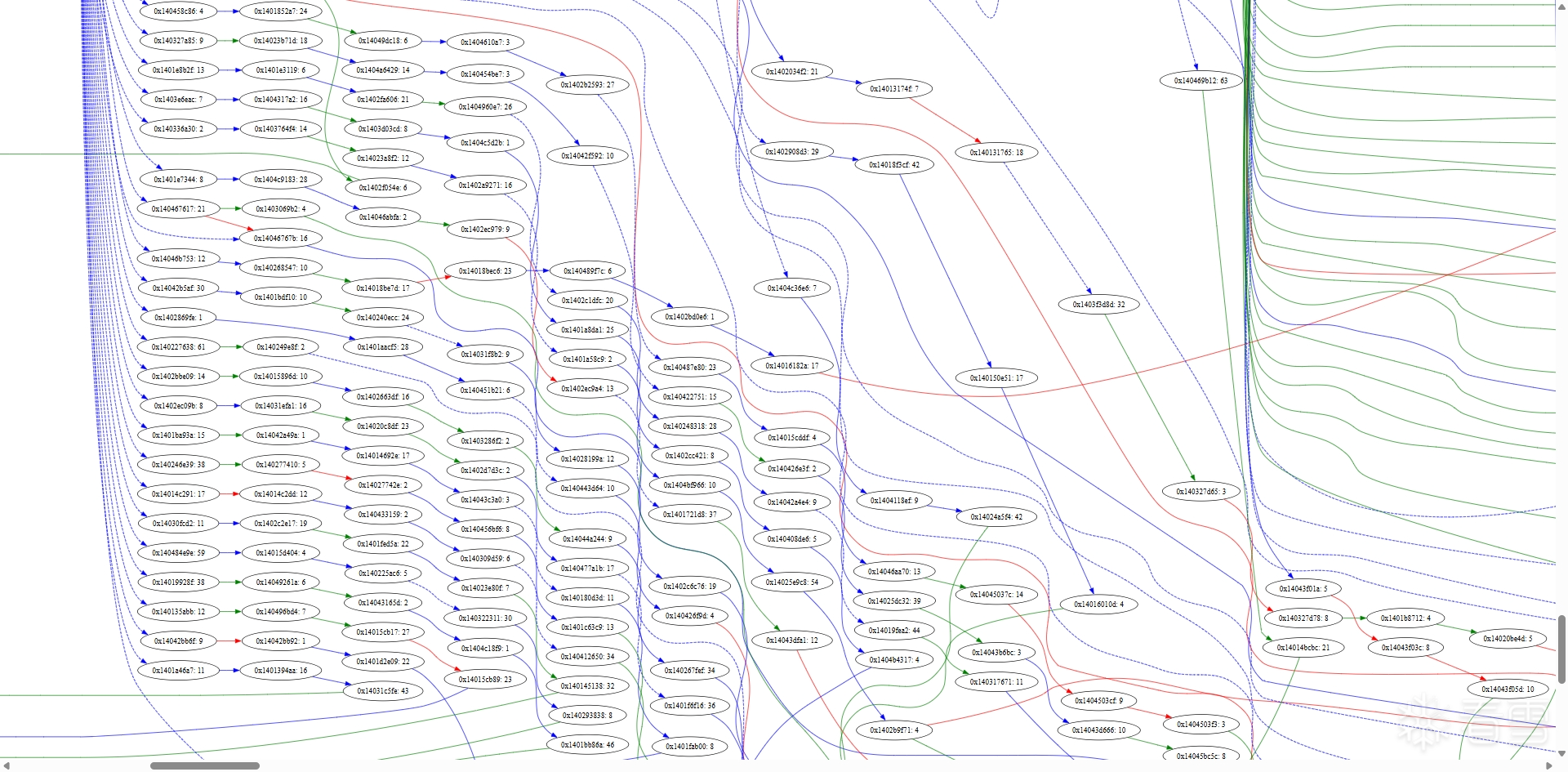
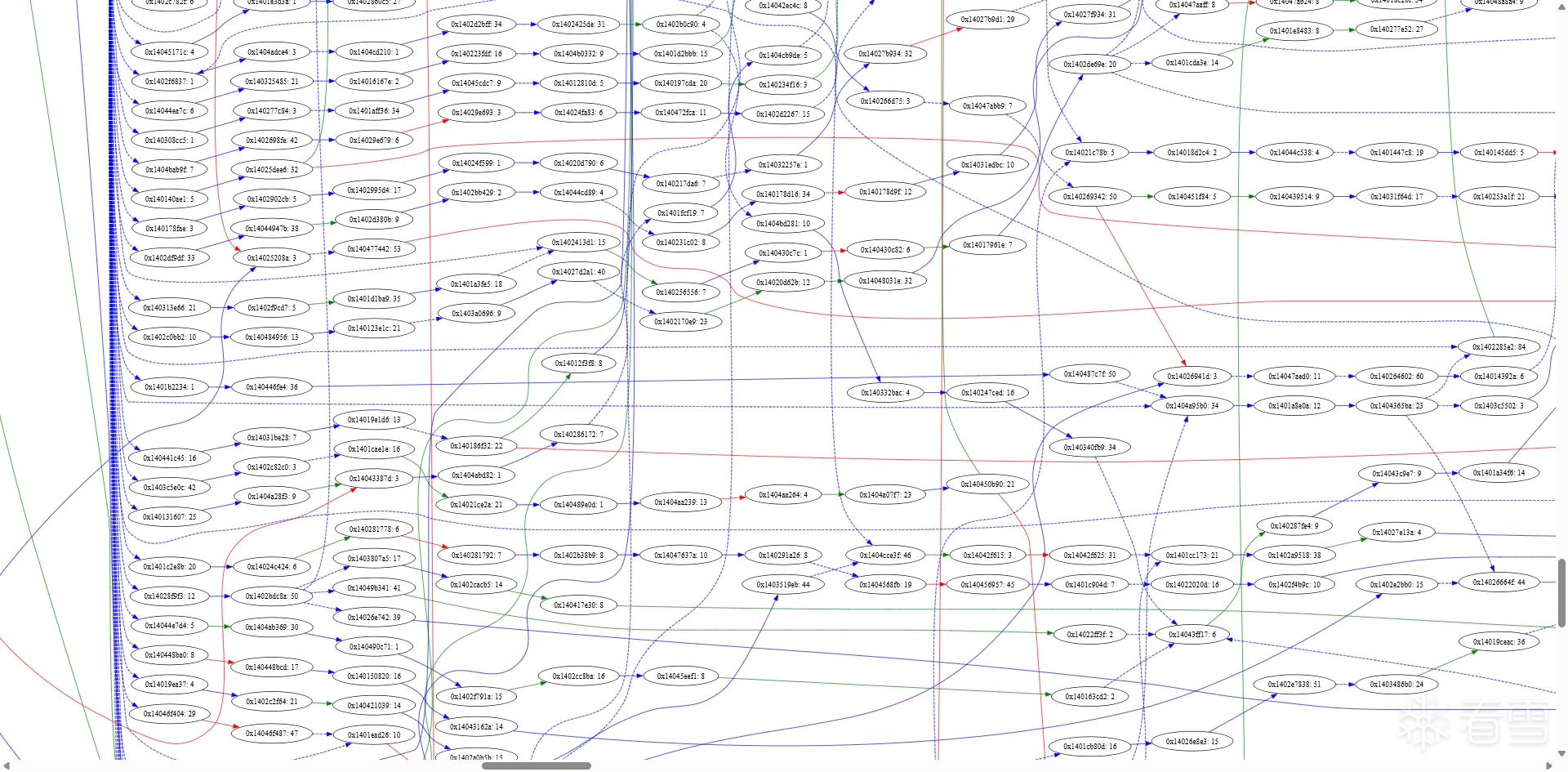
对于基本块合并,我们的合并规则是一个基本块有且仅有一个后继,且该后继仅有此前驱(即无分支或合并点);此外,若基本块间无控制流中断(如跳转)且逻辑连续,也可合并。
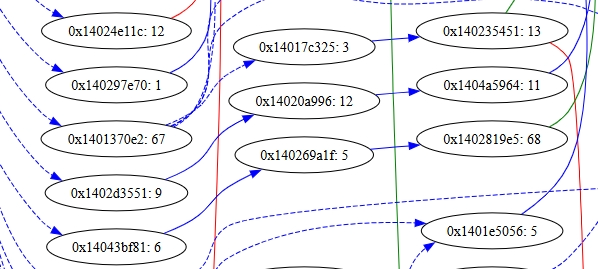
例如在上图中,0x14043bf81: 6 有且只有一个后继基本块 0x140269a1f: 5,而 0x140269a1f: 5 也有且只有一个前驱基本块 0x14043bf81: 6,且链接关系为蓝色实线的直接无条件跳转。因此 0x14043bf81: 6 与 0x140269a1f: 5 之间可以合并,变成一个全新的基本块 0x14043bf81: 11。这个基本块的前驱关系继承自 0x14043bf81: 6,后继关系继承自 0x140269a1f: 5。
基本块的合并是可以不断迭代下去的,合并的新基本块 0x14043bf81: 11 与 0x1402819e5: 68 符合合并规则,因此它们又能合并为 0x14043bf81: 79。
合并基本块的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 | def merge_basic_block(bbs: set[ST_BasicBlock]) -> tuple[set[ST_BasicBlock], bool]: hasChange = False bbs = set(bbs) def mergeBasicBlock(a: ST_BasicBlock, b: ST_BasicBlock) -> ST_BasicBlock: '''将基本块b追加到a的后面,新的基本块继承b的属性''' newbb = ST_BasicBlock(a.instructions + b.instructions) writeBBControlIns(newbb, b.getLastIns().ttins) newbb.indirectTargetAddrs = b.indirectTargetAddrs return newbb def getPrec(precAddr: int, checkAddr: int) -> BBLink: for prec in precursors[precAddr]: if (prec.addr == checkAddr): return prec return None precursors = defaultdict(set[BBLink]) # 前驱 successors = defaultdict(set[BBLink]) # 后继 for bb in bbs: current = bb.getCurrentAddr() if (bb.isControlflow): if (bb.isDirect): if (bb.isConditionalJump): # 针对有条件跳转 if not (hasattr(bb, "obfOPStatus") and bb.obfOPStatus == True): # ObfOP 反混淆 taken1 = BBLink(BBLinkType.DIRECT_COND_TAKEN, bb.targetAddr) taken2 = BBLink(BBLinkType.DIRECT_COND_NOTTAKEN, bb.fallThroughAddr) target = set({taken1, taken2}) else: if (bb.obfOPCondTaken): taken = BBLink(BBLinkType.DIRECT_UNCOND, bb.targetAddr) else: taken = BBLink(BBLinkType.DIRECT_FALLTHROUGH, bb.fallThroughAddr) target = set({taken}) else: # 针对无条件跳转 到这里的基本块的跳转指令是 jmp imm 或 call imm taken = BBLink(BBLinkType.DIRECT_UNCOND, bb.targetAddr) target = set({taken}) else: # 间接跳转 if not (hasattr(bb, "obfIndirectStatus") and bb.obfIndirectStatus == True): # ObfIndirect 反混淆 target = set() for indirectTargetAddr in bb.indirectTargetAddrs: taken = BBLink(BBLinkType.INDIRECT_UNCOND, indirectTargetAddr) target.add(taken) else: taken = BBLink(BBLinkType.DIRECT_UNCOND, bb.obfIndirectAddr) target = set({taken}) else: # 到这里的基本块是没有控制流指令的 taken = BBLink(BBLinkType.DIRECT_FALLTHROUGH, bb.fallThroughAddr) target = set({taken}) successors[current] = successors[current].union(target) for taken in target: precursors[taken.addr].add(BBLink(taken.type, current)) goNext = True while(goNext): goNext = False for bb in bbs: current = bb.getCurrentAddr() for succ in successors[current]: target = succ.addr succCheck = (len(successors[current]) == 1) and \ (succ.type == BBLinkType.DIRECT_UNCOND or succ.type == BBLinkType.DIRECT_FALLTHROUGH) precCheck = (target in precursors) and \ (len(precursors[target]) == 1) and \ (getPrec(target, current) != None) and \ (getPrec(target, current).type == BBLinkType.DIRECT_UNCOND or getPrec(target, current).type == BBLinkType.DIRECT_FALLTHROUGH) if (succCheck and precCheck): targetBB = FindBB(bbs, target) if (targetBB == None): print(f"异常! target: {hex(target)} 不存在 bb: {bb}") continue mergebb = mergeBasicBlock(bb, targetBB) mergeAddr = mergebb.getCurrentAddr() assert(mergeAddr == current) successors[mergeAddr] = successors[target].copy() successors[target].clear() precursors[target].clear() for newSucc in successors[mergeAddr]: removePrec = getPrec(newSucc.addr, target) assert(removePrec != None) precursors[newSucc.addr].remove(removePrec) precursors[newSucc.addr].add(BBLink(newSucc.type, mergeAddr)) bbs.remove(targetBB) bbs.remove(bb) bbs.add(mergebb) goNext = True hasChange = True break if (goNext): break return bbs, hasChange |
接下来我们得为反混淆做个代码逻辑模型。一般而言,代码混淆是可以迭代进行的,且迭代的过程一定会有个迭代轮数限制(一般视用户在保护器里的参数设置来决定取值)。基于这个本质,我们的反混淆就是应该做其逆操作,即做了多少次混淆,我们就反过来做对应次数的反混淆。但在实际情况中我们往往不知道具体的迭代轮数是多少,于是我们可以用 当前反混淆操作是否有效 这一指标作为标准,如果应用一次反混淆,发现指标有效,我们就开始继续下一轮的反混淆;直到指标为无效,我们才宣布结束循环。
为了协和每个反混淆 processor 之间,可以允许 processor 读取由其他 processor 所设置的混淆标识属性,但每个 processor 都只能独立完成自己所负责的反混淆任务,不能说某个 processor 的反混淆执行需要依赖另一个 processor 的混淆标识设置。
(比如在下文中,merge_basic_block 可以使用由 prove_opaque_predicate 所设置的 obfOPStatus 及 obfOPCondTaken 标识,但即使没有这些标识,它也应能继续合并基本块)
根据描述,我们编写出以下代码模型:
1 2 3 4 5 6 7 8 9 10 11 12 13 | # 反混淆迭代循环keepRun = TruerunCount = 0 # 迭代次数processors: list = [...]while(keepRun): runCount += 1 keepRun = False for processor in processors: hasChange = False bbs, hasChange = processor(bbs) if (hasChange): keepRun = True |
keepRun 变量指示反混淆迭代循环是否继续循环执行,局部变量 hasChange 变量则表示 processor 是否应用反混淆成功。只要 processors 里有任意一个调用 processor 后返回的 hasChange 为 True,整个反混淆循环就应该继续执行下去,直到没有任何 processor 成功,我们就能结束循环了。
现在我们把 merge_basic_block 加入到 processors 中运行试试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # 反混淆迭代循环keepRun = TruerunCount = 0 # 迭代次数processors: list = [merge_basic_block]while(keepRun): runCount += 1 keepRun = False for processor in processors: hasChange = False bbs, hasChange = processor(bbs) if (hasChange): keepRun = Trueprint(f"反混淆循环结束! 共周转执行 {runCount} 次")'''反混淆循环结束! 共周转执行 2 次''' |
现在让我们调用 drawBBLinkGraph(bbs) 来看看现在合并了基本块了的链接图是怎么样的

现在看起来至少比上面原始的基本块链接图精小了不少。
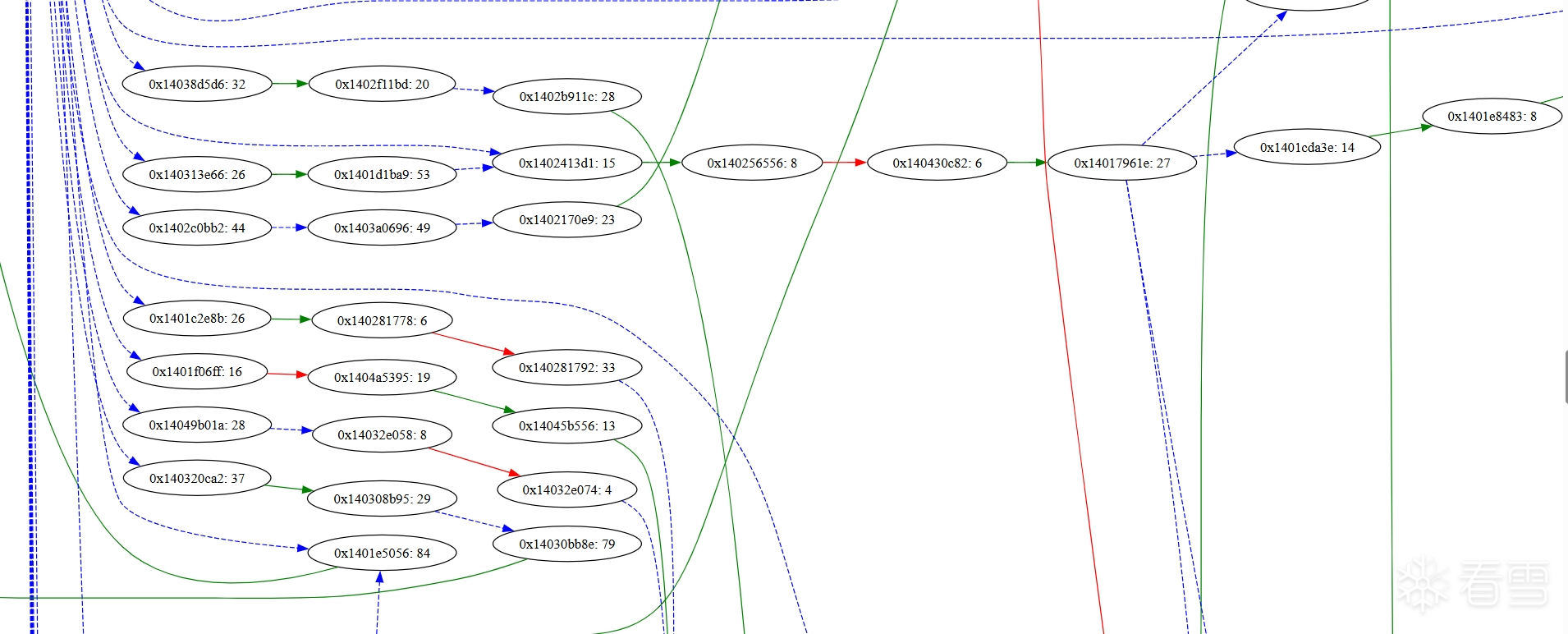
到此,借助基本块合并,我们成功刺杀了基于直接无条件跳转构造的代码乱序混淆。
3. 证明不透明谓词
正如上文所说的,vmp十分地狡猾,它会利用永真永假型不透明谓词来强化代码乱序的混淆效果。显然,刚刚的基本块合并并不能解决由它构造的代码乱序,因为jcc跳转的后继有两处,要么jump,要么fallthrough,但基本块合并的规则是后继只能有一个。因此,我们必须想办法找出不透明谓词的真正跳转事实,然后基于此把它真正的跳转后继改成 DIRECT_UNCOND 或 DIRECT_FALLTHROUGH,把虚假的跳转后继给删除掉。
永真永假型不透明谓词有两种形式,跳转条件表达式为常量 以及 跳转条件表达式为恒成立或恒不成立运算式,那我们的思路是这样的,我们可以把一切都符号化(全部寄存器和内存),然后再去符号执行有jcc跳转的基本块,最后当符号引擎执行到最后一条指令的时候,我们就判断当前的路径谓词是否已被符号化。
如果未被符号化,就说明我们是第一种情况 —— 跳转条件表达式为常量,这时候就能直接判定 jcc 跳转是不透明谓词;
如果被符号化,就说明我们可能是第二种情况 —— 跳转条件表达式为恒成立或恒不成立运算式,这时候我们还需要进一步用 SMT 求解器去证明它最终是不是不透明谓词。证明内容则是证明两条分支路径是否存在有一条是不可达的分支路径,如果有一条分支路径被证明为不可达,这时候就能判定 jcc 跳转是不透明谓词。
证明不透明谓词代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | def checkOpaquePredicate(bb: ST_BasicBlock): insList = bb.instructions tmpctx = triton.TritonContext() tmpctx.setArchitecture(ctx.getArchitecture()) tmpctx.setMode(triton.MODE.ALIGNED_MEMORY, True) tmpctx.setMode(triton.MODE.AST_OPTIMIZATIONS, True) tmpctx.setMode(triton.MODE.CONSTANT_FOLDING, True) tmpctx.setMode(triton.MODE.SYMBOLIZE_INDEX_ROTATION, True) tmpctx.setMode(triton.MODE.PC_TRACKING_SYMBOLIC, False) # 不建议开启符号内存,这会导致求解时间显著增长 tmpastctx = tmpctx.getAstContext() # 符号化寄存器环境 initTritonCtxEnvSym(tmpctx, bb.getFirstIns(), main_thread.teb) for i, ins in enumerate(insList): ttins = triton.Instruction() ttins.setAddress(ins.ins_address) ttins.setOpcode(ins.bytes) for memAcc in ins.mem_accs: if (memAcc.type != Supertrace.AccessType.READ): continue for i in range(memAcc.acc_size): memi = triton.MemoryAccess(memAcc.acc_address + i, triton.CPUSIZE.BYTE) if (not tmpctx.isConcreteMemoryValueDefined(memi)): oldby = (memAcc.old_data >> (i * 8)) & 0xFF tmpctx.setConcreteMemoryValue(memi, oldby) tmpctx.symbolizeMemory(memi, hex(memAcc.acc_address + i)) tmpctx.processing(ttins) if ((i == len(insList) - 1) and ttins.isBranch() and ttins.getType() != triton.OPCODE.X86.JMP): # 筛选JCC有条件跳转指令 if (hasattr(ins, "obfOPStatus") and ins.obfOPStatus == True): # 已经证明过了,跳过此次证明过程 continue ins.obfOPStatus = False ins.obfOPCondTaken = False pathPredicate = tmpctx.getPathPredicate() satCount = 0 if (pathPredicate.isSymbolized()): if (tmpctx.isSat(pathPredicate)): satCount += 1 if (tmpctx.isSat(tmpastctx.lnot(pathPredicate))): satCount += 1 else: satCount = 1 if (satCount == 1): # 是不透明谓词 ins.obfOPStatus = True ins.obfOPCondTaken = (ttins.getNextAddress() != record[ins.id + 1].ins_address) # print(f"{hex(ins.ins_address)} 是不透明谓词!跳转情况: {ins.obfOPCondTaken} {ttins}")def prove_opaque_predicate(bbs: set[ST_BasicBlock]) -> tuple[set[ST_BasicBlock], bool]: hasChange = False bbs = set(bbs) for bb in bbs: if (bb.isConditionalJump): lastIns = bb.getLastIns() if (hasattr(lastIns, "obfOPStatus") and lastIns.obfOPStatus == True): continue # 已证明过,跳过 checkOpaquePredicate(bb) if (hasattr(lastIns, "obfOPStatus") and lastIns.obfOPStatus == True): # print(f"{hex(bb.getCurrentAddr())} 存在OP: {lastIns.ttins}") # 将指令的不透明谓词的信息保存到基本块上 bb.obfOPStatus = lastIns.obfOPStatus bb.obfOPCondTaken = lastIns.obfOPCondTaken hasChange = True return bbs, hasChange |
好的,这次我们把 prove_opaque_predicate 也加入到 processors 里来,然后再重新反混淆一次:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # 反混淆迭代循环keepRun = TruerunCount = 0 # 迭代次数processors: list = [merge_basic_block, prove_opaque_predicate]while(keepRun): runCount += 1 keepRun = False for processor in processors: hasChange = False bbs, hasChange = processor(bbs) if (hasChange): keepRun = Trueprint(f"反混淆循环结束! 共周转执行 {runCount} 次")'''反混淆循环结束! 共周转执行 7 次''' |
现在让我们调用 drawBBLinkGraph(bbs) 来看看现在的基本块链接图是怎么样的:
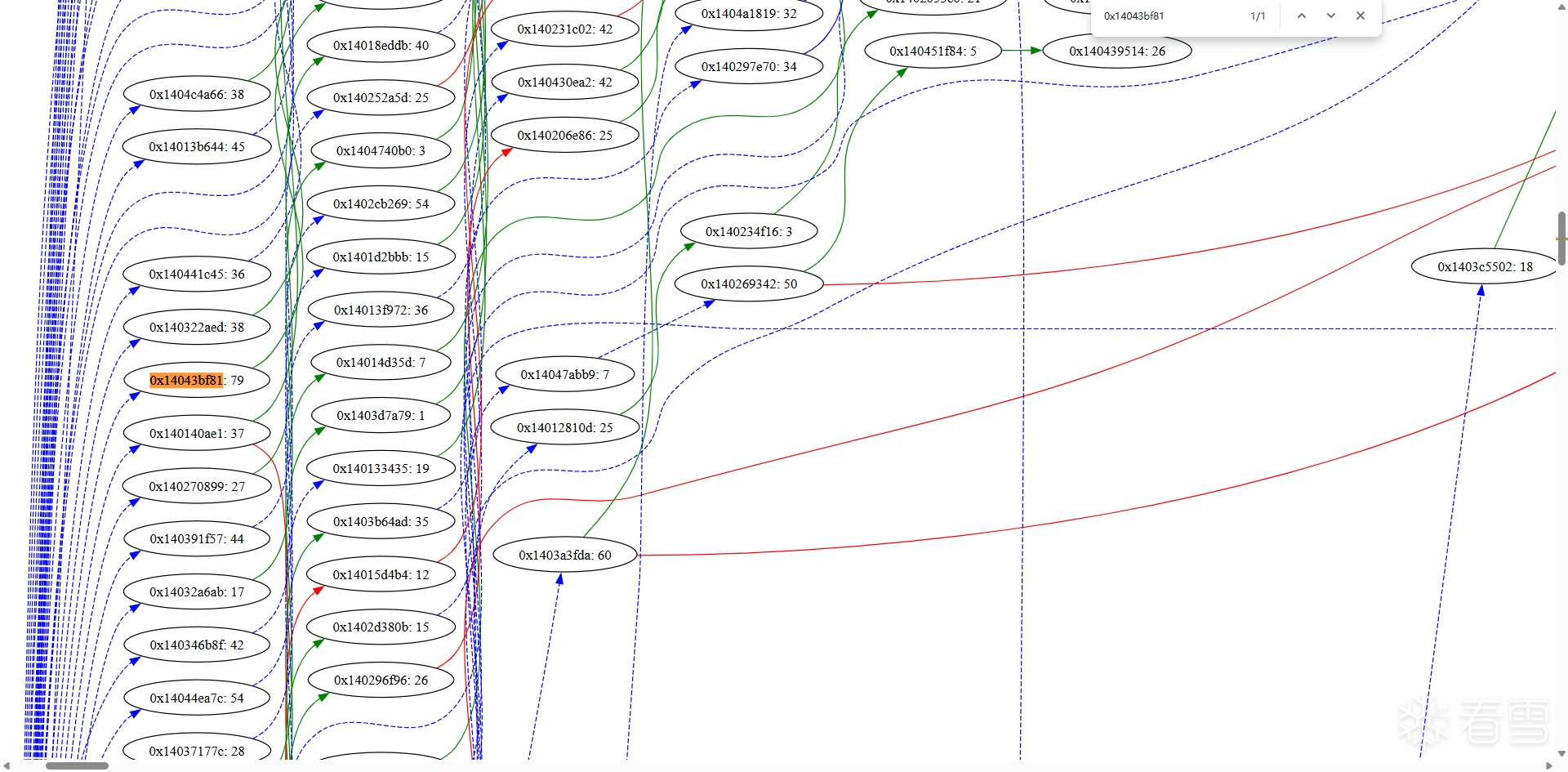
又变得精细了,让我们看看之前举的基本块例子 0x14043bf81
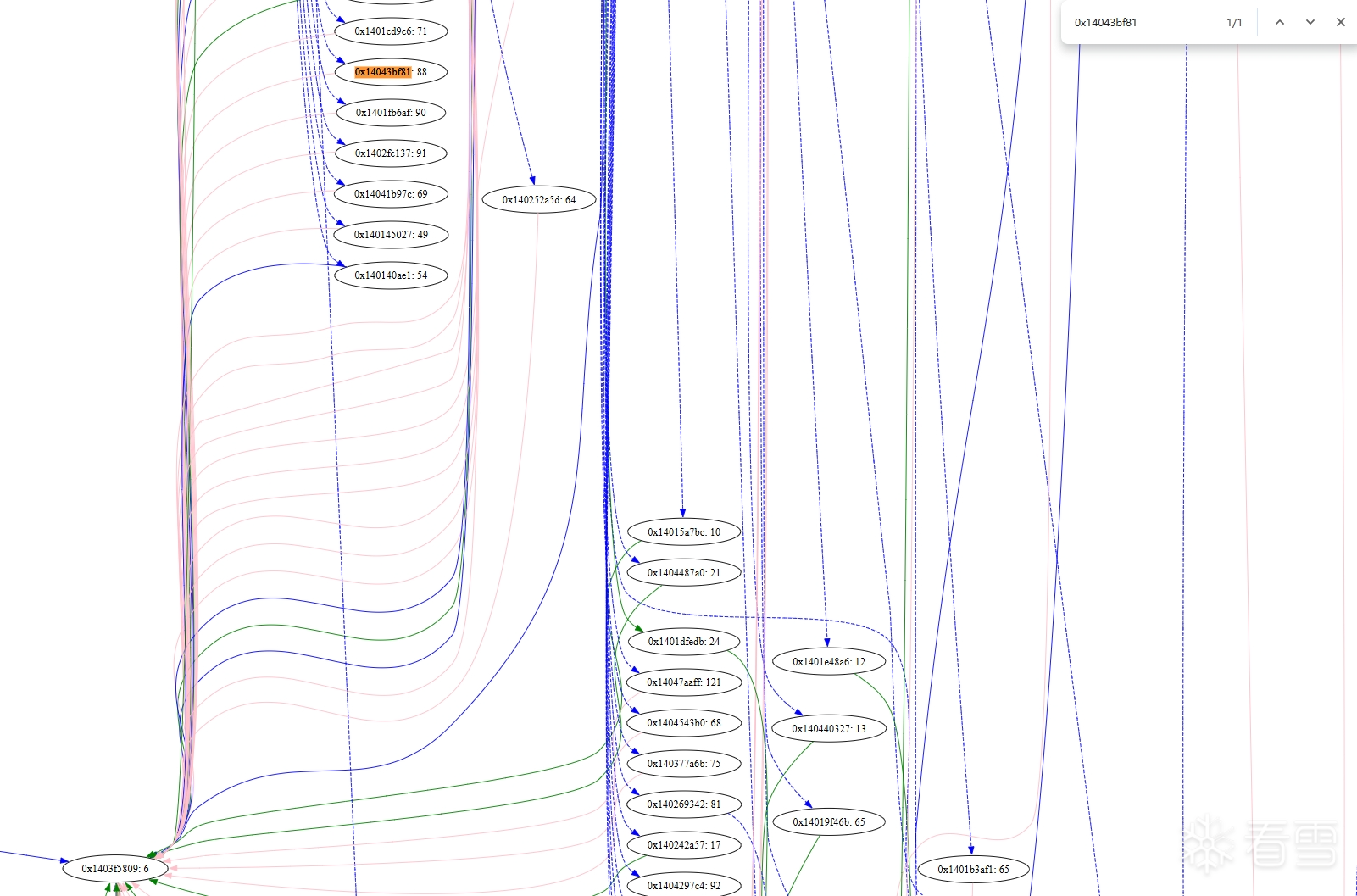
很好,这下基本块 0x14043bf81: 88 已经是打回原形了,它已经没有后继基本块了。
到此,我们又成功刺杀了永真永假型不透明谓词混淆,以及基于它所构造的代码乱序混淆。
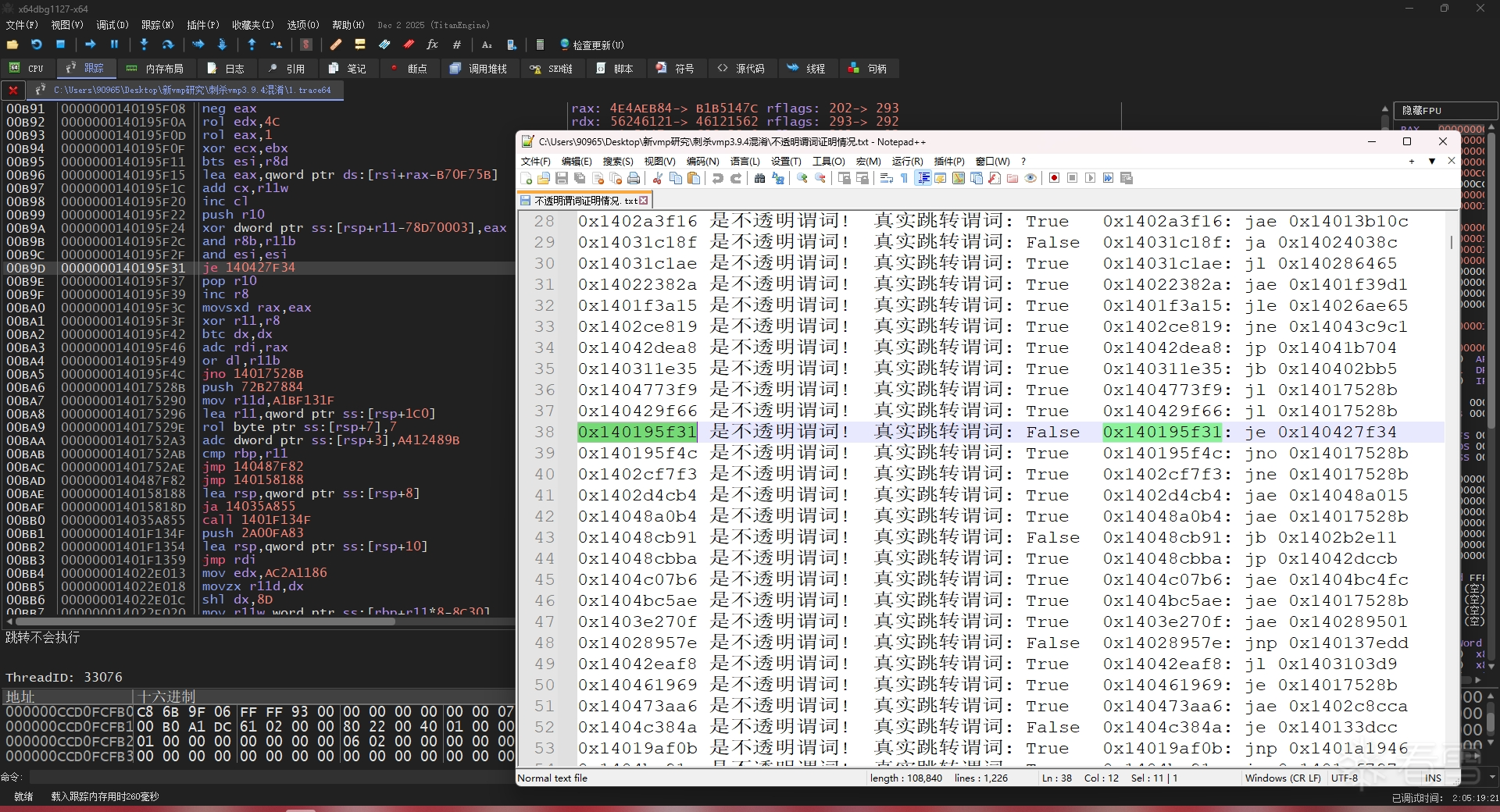
4. 间接跳转混淆
如果你仔细看过上面的基本块链接图,你会发现有些基本块尽管其后继基本块的链接是间接跳转,但它们看起来也"像"是符合合并规则的样子。是的,有的确实能合并,因为它们是真直接跳转的假间接跳转。
vmp的间接跳转混淆似乎都是基于篡改call指令在栈中压入的地址来实现:因此可以用类似证明不透明谓词的那样,先符号化一切(寄存器和内存),然后判断间接跳转指令是否被符号化。如果未被符号化,则说明该间接跳转是混淆的。
证明间接跳转混淆代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | def checkObfIndirect(bb: ST_BasicBlock): insList = bb.instructions tmpctx = triton.TritonContext() tmpctx.setArchitecture(ctx.getArchitecture()) tmpctx.setMode(triton.MODE.ALIGNED_MEMORY, True) tmpctx.setMode(triton.MODE.AST_OPTIMIZATIONS, True) tmpctx.setMode(triton.MODE.CONSTANT_FOLDING, True) tmpctx.setMode(triton.MODE.SYMBOLIZE_INDEX_ROTATION, True) # 符号化寄存器环境 initTritonCtxEnvSym(tmpctx, bb.getFirstIns(), main_thread.teb) for i, ins in enumerate(insList): ttins = triton.Instruction() ttins.setAddress(ins.ins_address) ttins.setOpcode(ins.bytes) for memAcc in ins.mem_accs: if (memAcc.type != Supertrace.AccessType.READ): continue for i in range(memAcc.acc_size): memi = triton.MemoryAccess(memAcc.acc_address + i, triton.CPUSIZE.BYTE) if (not tmpctx.isConcreteMemoryValueDefined(memi)): oldby = (memAcc.old_data >> (i * 8)) & 0xFF tmpctx.setConcreteMemoryValue(memi, oldby) tmpctx.symbolizeMemory(memi, hex(memAcc.acc_address + i)) tmpctx.processing(ttins) if ((i == len(insList) - 1) and checkIndirectIns(ttins)): if (hasattr(ins, "obfIndirectStatus") and ins.obfIndirectStatus == True): # 已经证明过了,跳过此次证明过程 continue ins.obfIndirectStatus = False ins.obfIndirectAddr = 0 if (not ttins.isSymbolized()): ins.obfIndirectStatus = True ins.obfIndirectAddr = record[ins.id + 1].ins_address # print(f"{hex(ins.ins_address)} 是间接跳转混淆! 地址: {hex(ins.obfIndirectAddr)} {ttins}")def prove_obfuse_indirect(bbs: set[ST_BasicBlock]) -> tuple[set[ST_BasicBlock], bool]: hasChange = False bbs = set(bbs) for bb in bbs: lastIns = bb.getLastIns() if (hasattr(lastIns, "obfIndirectStatus") and lastIns.obfIndirectStatus == True): continue # 已证明过,跳过 checkObfIndirect(bb) if (hasattr(lastIns, "obfIndirectStatus") and lastIns.obfIndirectStatus == True): bb.obfIndirectStatus = lastIns.obfIndirectStatus bb.obfIndirectAddr = lastIns.obfIndirectAddr hasChange = True return bbs, hasChange |
代入 processors 并运行:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # 反混淆迭代循环keepRun = TruerunCount = 0 # 迭代次数processors: list = [merge_basic_block, prove_opaque_predicate, prove_obfuse_indirect]while(keepRun): runCount += 1 keepRun = False for processor in processors: hasChange = False bbs, hasChange = processor(bbs) if (hasChange): keepRun = Trueprint(f"反混淆循环结束! 共周转执行 {runCount} 次")'''反混淆循环结束! 共周转执行 8 次''' |
调用 drawBBLinkGraph(bbs) 来看看现在的基本块链接图是怎么样的:

到此,我们又成功刺杀了间接跳转混淆,以及基于它所构造的代码乱序混淆。
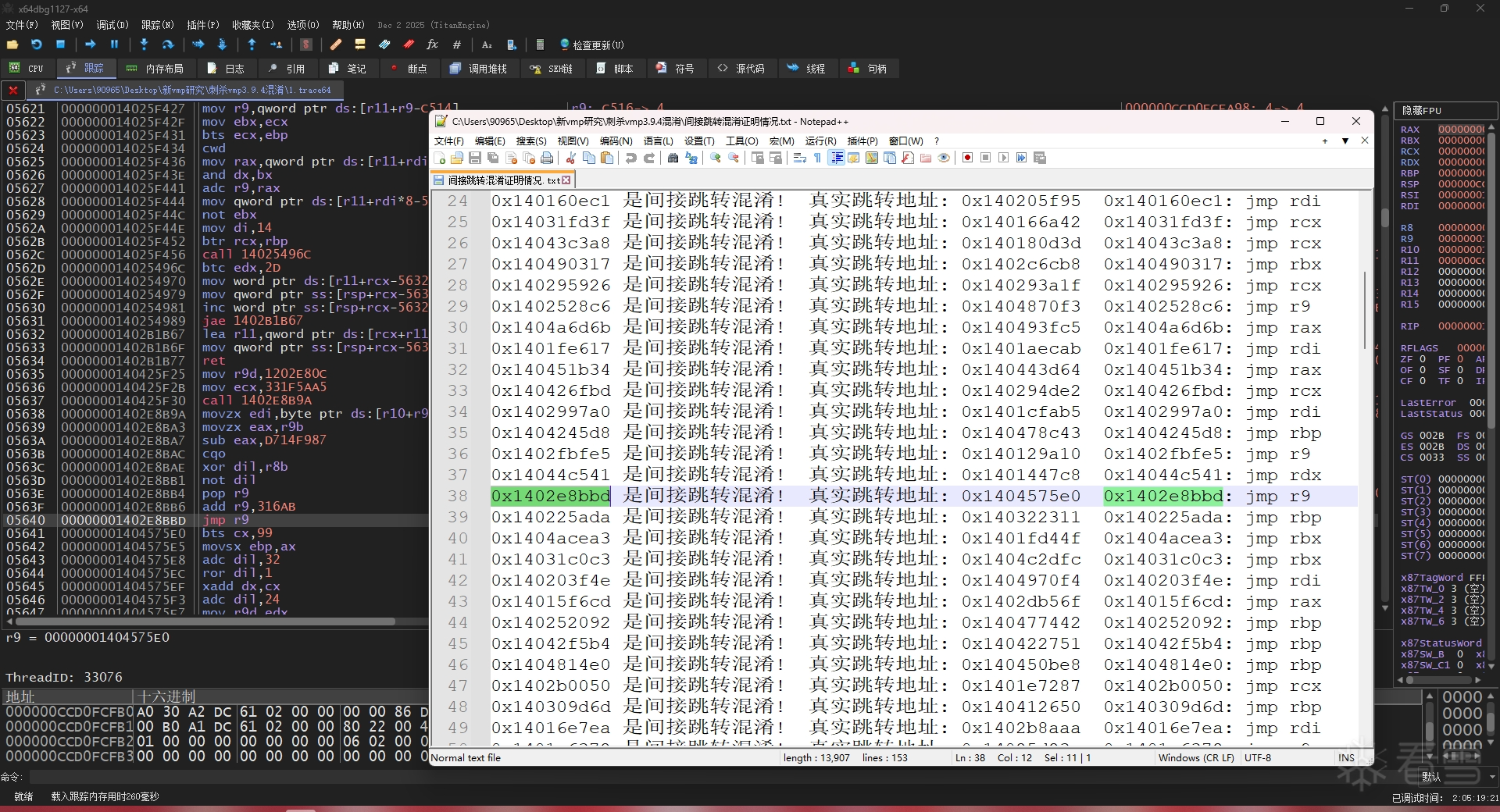
5. 内存操作数常量隐藏混淆
这是新版本vmp最新引入的混淆手段,不过根据观察,它们在内存操作数里代入 index 或 base 寄存器里的数值的初始来源几乎都是来自上部分指令的imm,因此,还是可以用类似证明不透明谓词的那样,先符号化一切(寄存器和内存),然后判断 index 或 base 寄存器是否被符号化。如果未被符号化,则说明该寄存器的值是已知的,是可以直接替换的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 | def checkMemOpConstHide(bb: ST_BasicBlock) -> bool: hasChange = False insList = bb.instructions tmpctx = triton.TritonContext() tmpctx.setArchitecture(ctx.getArchitecture()) tmpctx.setMode(triton.MODE.ALIGNED_MEMORY, True) tmpctx.setMode(triton.MODE.AST_OPTIMIZATIONS, True) tmpctx.setMode(triton.MODE.CONSTANT_FOLDING, True) tmpctx.setMode(triton.MODE.SYMBOLIZE_INDEX_ROTATION, True) initTritonCtxEnvSym(tmpctx, bb.getFirstIns(), main_thread.teb) # 初始化具体化环境 tmpctx.symbolizeRegister(tmpctx.registers.rsp, tmpctx.registers.rsp.getName()) for i, ins in enumerate(insList): ttins = triton.Instruction() ttins.setAddress(ins.ins_address) ttins.setOpcode(ins.bytes) tmpctx.disassembly(ttins) ops = ttins.getOperands() for op in ops: if (op.getType() != triton.OPERAND.MEM): continue memop: triton.MemoryAccess = op baseReg = memop.getBaseRegister() indexReg = memop.getIndexRegister() ins.obfMemConstHideStatus = False ins.obfMemConstHideDetail = set() # (TTRegID, TTRegName, RealValue) if (tmpctx.isRegisterValid(baseReg) and tmpctx.isRegisterValid(indexReg) and baseReg == indexReg and (not tmpctx.isRegisterSymbolized(baseReg))): # 如果是相同寄存器 if (tmpctx.isRegisterValid(baseReg) and not tmpctx.isRegisterSymbolized(baseReg)): hasChange = True ins.obfMemConstHideStatus = True real = tmpctx.getConcreteRegisterValue(baseReg) ins.obfMemConstHideDetail.add( (baseReg.getId(), baseReg.getName(), real)) # print(f"{hex(ins.dbg_id)} {ins.ttins}\t\t的内存操作数的 {baseReg.getName()} 寄存器是常量 {hex(real)}") else: if (tmpctx.isRegisterValid(baseReg) and not tmpctx.isRegisterSymbolized(baseReg)): hasChange = True ins.obfMemConstHideStatus = True real = tmpctx.getConcreteRegisterValue(baseReg) ins.obfMemConstHideDetail.add( (baseReg.getId(), baseReg.getName(), real)) # print(f"{hex(ins.dbg_id)} {ins.ttins}\t\t的内存操作数的 {baseReg.getName()} 寄存器是常量 {hex(real)}") if (tmpctx.isRegisterValid(indexReg) and not tmpctx.isRegisterSymbolized(indexReg)): hasChange = True ins.obfMemConstHideStatus = True real = tmpctx.getConcreteRegisterValue(indexReg) ins.obfMemConstHideDetail.add( (indexReg.getId(), indexReg.getName(), real)) # print(f"{hex(ins.dbg_id)} {ins.ttins}\t\t的内存操作数的 {indexReg.getName()} 寄存器是常量 {hex(real)}") for memAcc in ins.mem_accs: if (memAcc.type != Supertrace.AccessType.READ): continue for i in range(memAcc.acc_size): memi = triton.MemoryAccess(memAcc.acc_address + i, triton.CPUSIZE.BYTE) if (not tmpctx.isConcreteMemoryValueDefined(memi)): oldby = (memAcc.old_data >> (i * 8)) & 0xFF tmpctx.setConcreteMemoryValue(memi, oldby) tmpctx.symbolizeMemory(memi, hex(memAcc.acc_address + i)) tmpctx.buildSemantics(ttins) return hasChangedef prove_obfuse_memopConstHide(bbs: set[ST_BasicBlock]) -> tuple[set[ST_BasicBlock], bool]: hasChange = False bbs = set(bbs) for bb in bbs: if (checkMemOpConstHide(bb)): hasChange = True return bbs, hasChange |
因为这个反混淆 processor 和控制流混淆没啥关系,因此可以单独执行它,不需要将其放入到反混淆迭代循环里。
1 | bbs, _ = prove_obfuse_memopConstHide(bbs) |
执行完成后,它会在每个包含有内存操作数常量隐藏混淆的指令里添加混淆标识(obfMemConstHideStatus 和 obfMemConstHideDetail),这可以为后来生成 x64dbg 反混淆脚本代码提供帮助。
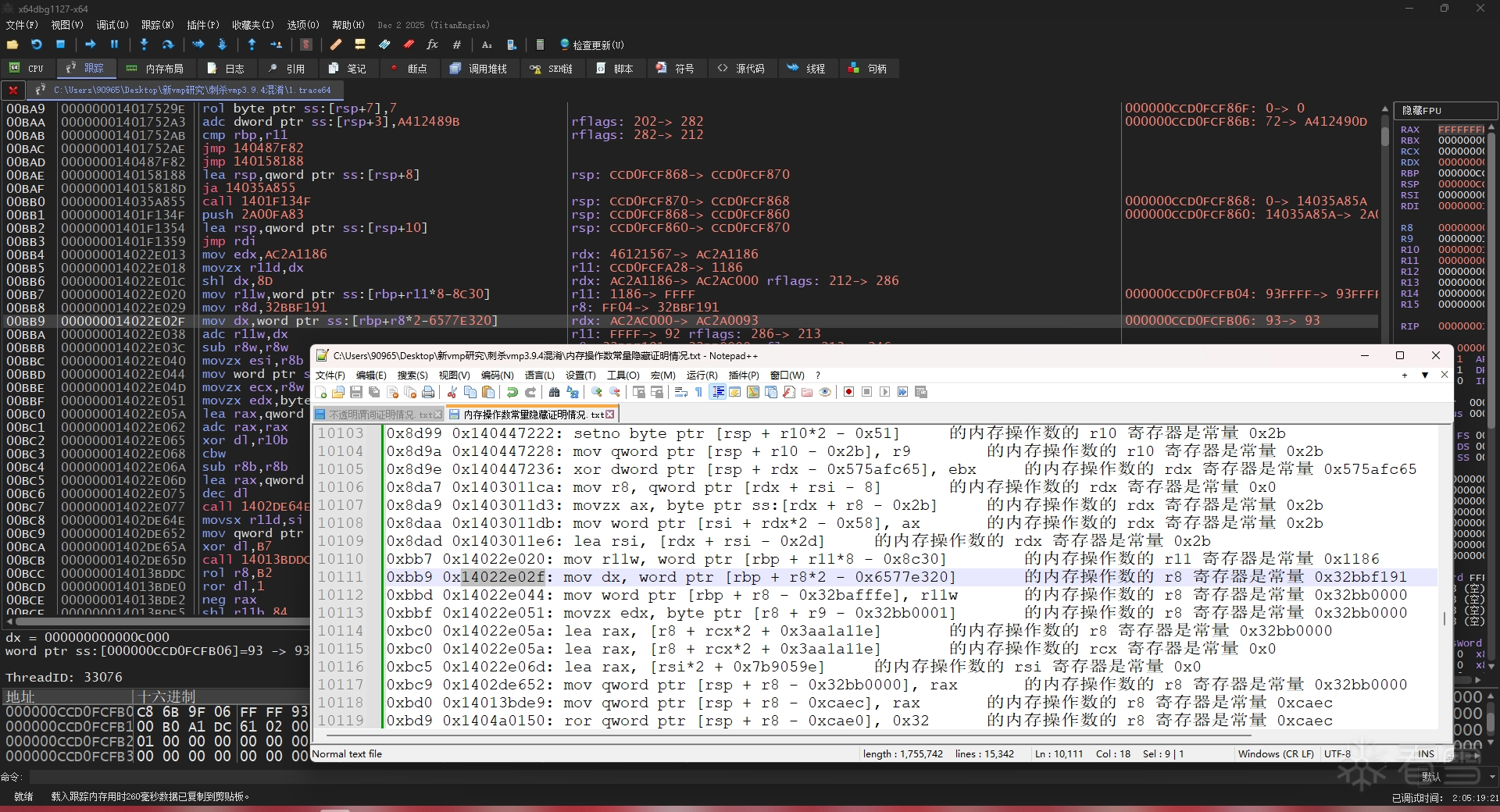
校验反混淆效果
到目前为止,我们总共刺杀了四种混淆,分别是代码乱序、不透明谓词、间接跳转混淆以及内存操作数常量隐藏,现在我们可以尝试写个 x64dbg 脚本,把反混淆后的新字节写进去,看看程序还能不能正常运行。
首先说明一下,代码乱序和间接跳转混淆是没办法写成脚本还原的,代码乱序是因为它是保证每个基本块的正确顺序执行,也没啥可以还原,除非我们能开辟一个新区块,再按照原始顺序还原控制流,但这样工作量太大了,也没啥意义。
然后是间接跳转混淆,解混淆肯定就是把间接跳转改成直接跳转,但是指令字节数不够(才两个字节)

不透明谓词可以解,我们直接根据跳转事实,来改成 nop 或者 jmp targetAddr:
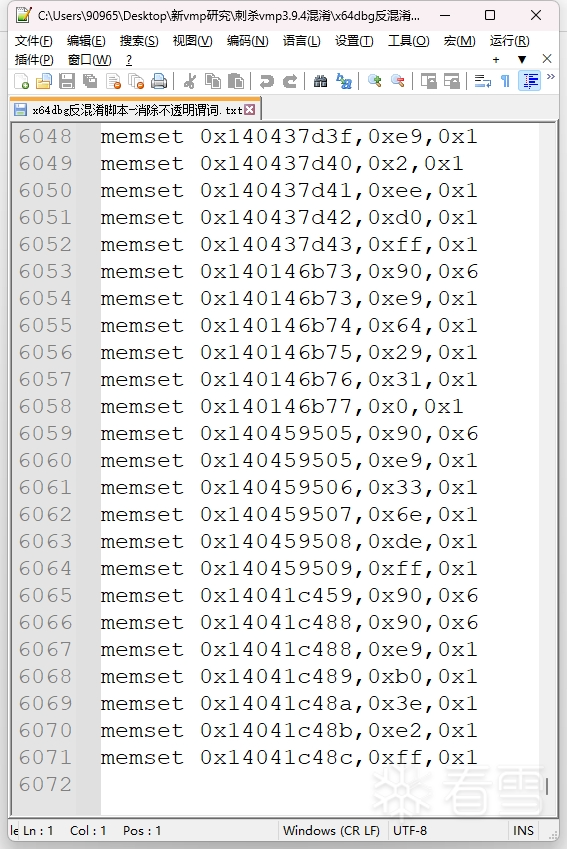
1 2 3 4 5 6 7 | def writeBytesX64dbg(insaddr: int, bys: bytes) -> str: result = "" for i, by in enumerate(bys): result += f"memset {hex(insaddr + i)},{hex(by)},0x1" if (i != len(bys) - 1): result += "\n" return result |
我直接复制打印输出的命令再自行复制到文件里保存:
1 2 3 4 5 6 7 8 9 | for ins in record: if (hasattr(ins, "obfOPStatus") and ins.obfOPStatus == True): print(f"memset {hex(ins.ins_address)},0x90,{hex(len(ins.bytes))}") if (ins.obfOPCondTaken): ops = ins.ttins.getOperands() immop: triton.Immediate = ops[0] writestr = f"jmp {hex(immop.getValue())}" bys = asmDecode(writestr, ins.ins_address) print(writeBytesX64dbg(ins.ins_address, bys)) |
紧接着是 内存操作数常量隐藏,这里我们得用到一个框架 —— miasm,我们需要它支持指令的结构化重装卸的功能,来改写内存操作数里的寄存器为数值(不得不说这功能是真的方便)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | for bb in bbs: for ins in bb.instructions: if (hasattr(ins, "obfMemConstHideStatus") and ins.obfMemConstHideStatus == True): mmins = mn_x86.dis(ins.bytes, 64) rep = {} for detail in ins.obfMemConstHideDetail: bit = ctx.getRegister(detail[0]).getBitSize() rep[ExprId(detail[1].upper(), bit)] = ExprInt(detail[2], bit) for i, arg in enumerate(mmins.args): if (arg.is_mem()): mmins.args[i] = arg.replace_expr(rep) try: asm = mn_x86.asm(mmins) ins.obfMemConstHideRep = asm except ValueError: print(f"{ins} 错误!\t{mmins}") continue'''<DbgId: 102c4> ip: 1401a6eea insSize: 8 错误! LEA RBX, QWORD PTR [0xFFFFFF8D * 0x2 + 0x30AA5D90]<DbgId: 102f0> ip: 140158a35 insSize: 8 错误! LEA R10, QWORD PTR [0x46AA06EA + 0x4B380F72 * 0x8 + 0x5D0D370A]......''' |
这里存在一个 BUG,我也不知道应该怎么修复,问题在于 lea 指令也算是用到内存操作数的指令,但vmp经常用它做数值运算,所以解混淆后的内存操作数的数值可能会超出64位界限,导致 miasm 无法编码提示报错,所以这里直接忽略掉它们。
1 2 3 4 5 6 7 8 9 10 11 12 | for bb in bbs: for ins in bb.instructions: if (hasattr(ins, "obfMemConstHideStatus") and ins.obfMemConstHideStatus == True and hasattr(ins, "obfMemConstHideRep")): if (not len(ins.obfMemConstHideRep) > 0): # print("数量异常") continue rep: bytes = ins.obfMemConstHideRep[0] # 第一个默认是最短的 if (len(rep) > len(ins.bytes)): # print("长度不够") continue print(f"memset {hex(ins.ins_address)},0x90,{hex(len(ins.bytes))}") print(writeBytesX64dbg(ins.ins_address, rep)) |
然后我们输入 3735928559 让他正确弹出信息框
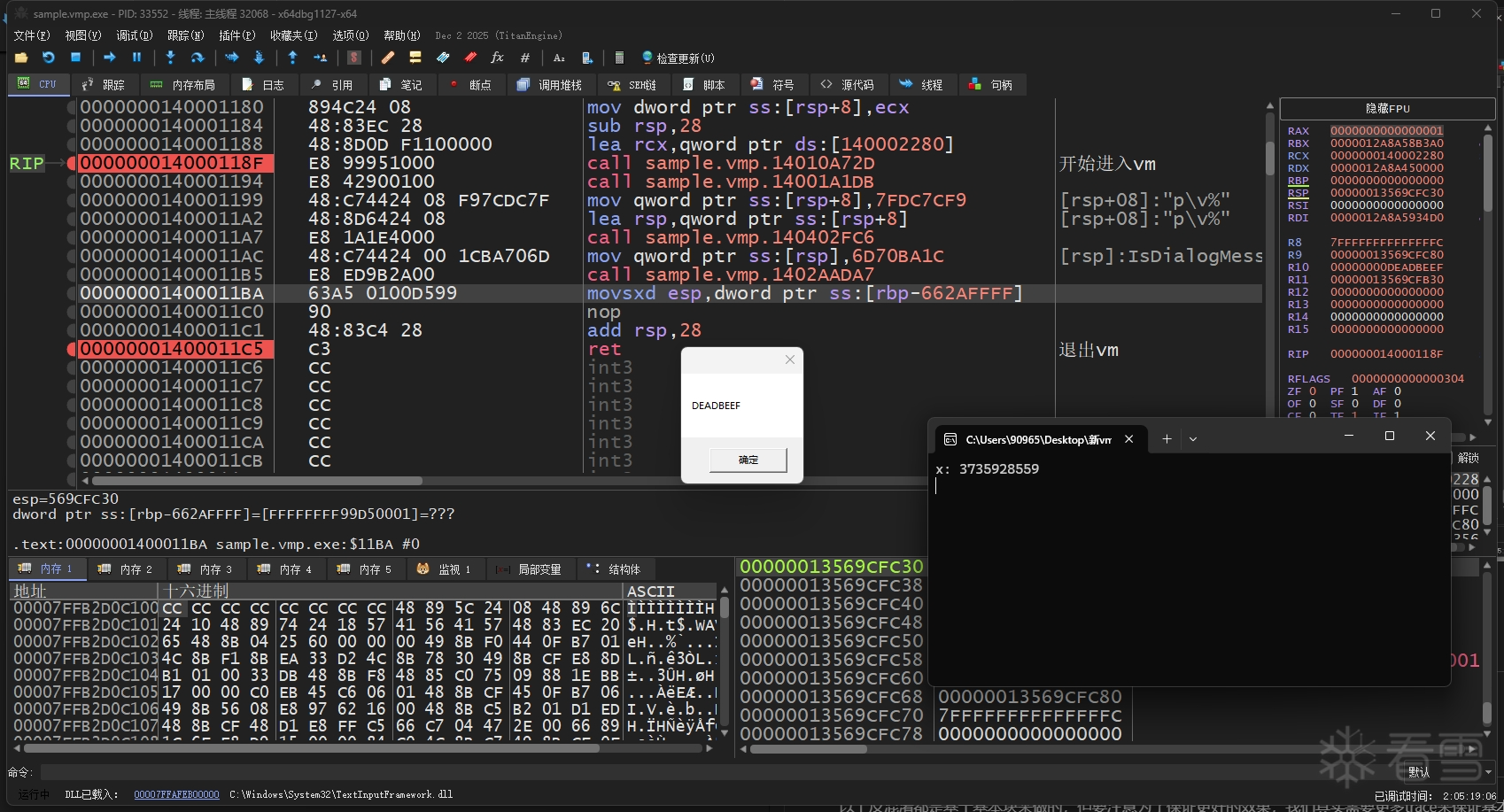
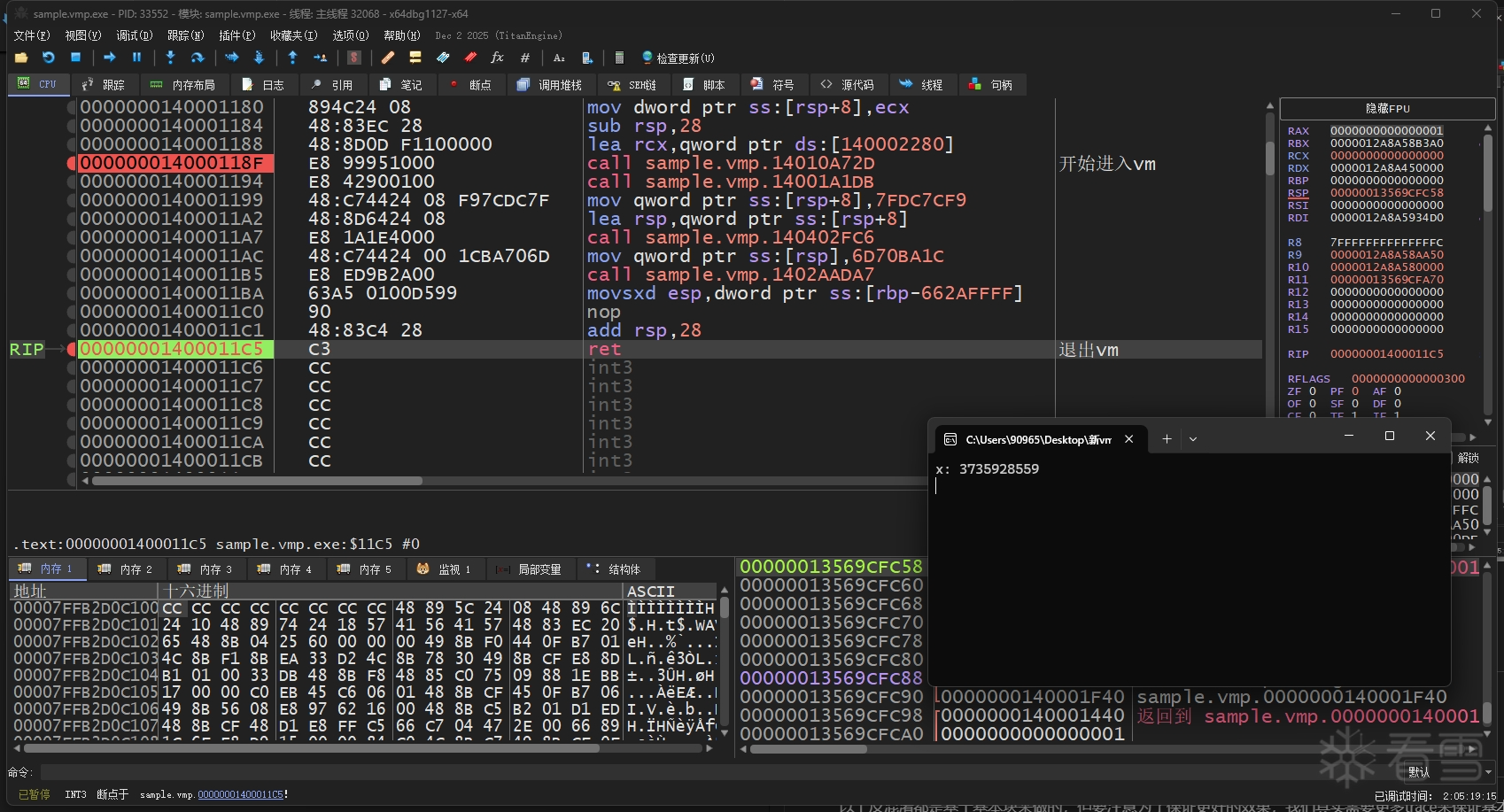
结果显示运行正常。
这时候我们再录制个反混淆后的 trace,与原始 trace 做个对比: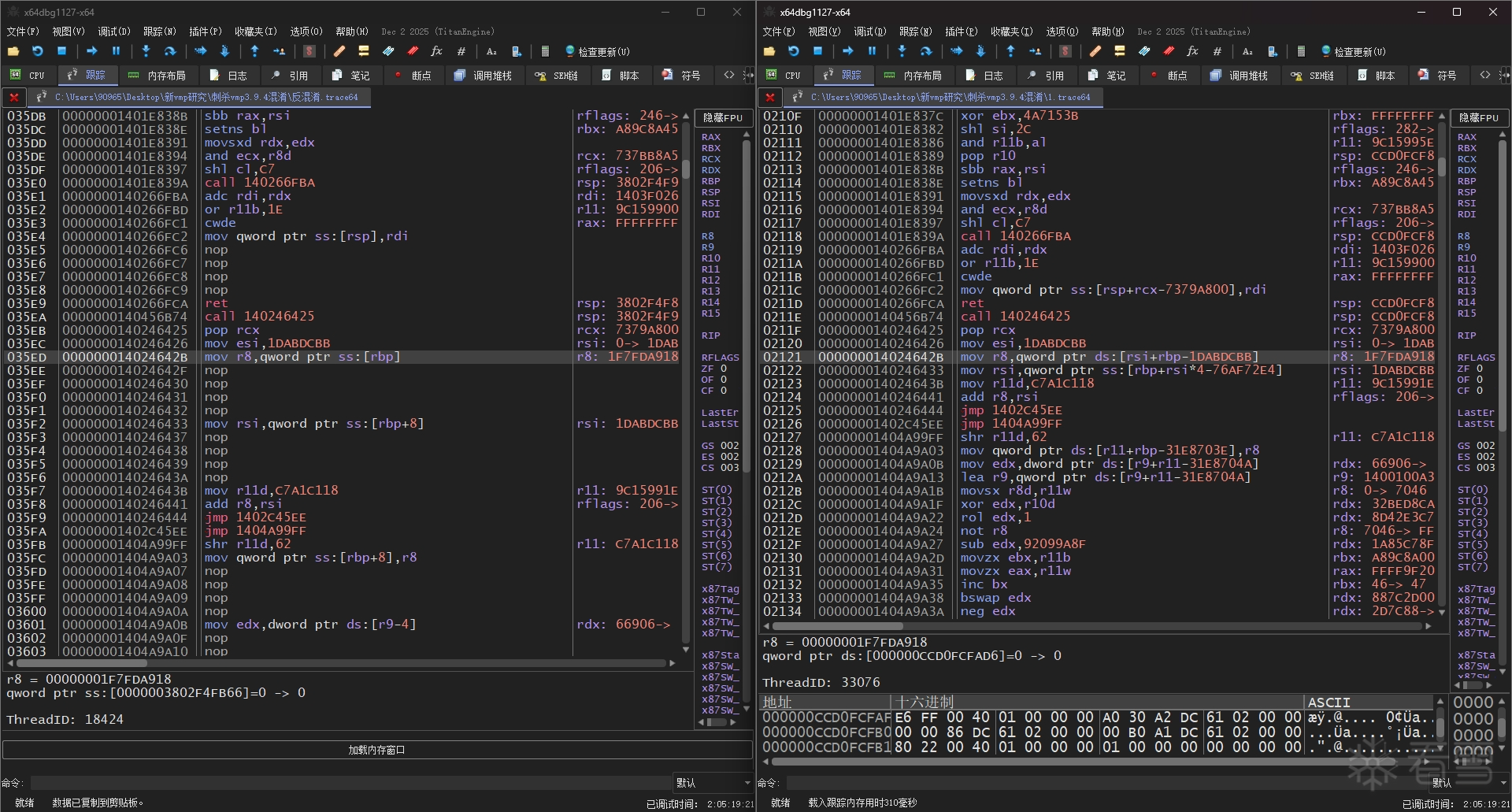
关于其他剩余的混淆
像垃圾代码、MBA 混淆这些,我打算后续在 IR 层面上来实现了,在这里我没做实现(有点懒了),在这里说下我的思路:垃圾代码就是用活跃变量分析来清除;MBA 混淆就用 SMT 求解或者灰盒合成等手段来化简;等价语义指令替换需要自己收集特征做替换,然后一定要慎重判断语义行为是否一致,除非能证明出语义不一致对程序的运行没有影响(比如替换新指令后额外引入了标志位改写的行为,但后续标志位会被覆盖且在此之前没有任何引用)。
参考资料
更多【软件逆向-刺杀vmp3.9.4混淆】相关视频教程:www.yxfzedu.com
相关文章推荐
- 驱动出租及驱动定制价格 - 游戏逆向软件逆向Windows内核驱动出租
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——TypeConfusion - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——IntegerOverflow - PwnHarmonyOSWeb安全软件逆向
- 软件逆向-LMCompatibilityLevel 安全隐患 - PwnHarmonyOSWeb安全软件逆向
- Android安全-记一次完整的Android native层动态调试--使用avd虚拟机 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-零基础入门V8——CVE-2021-38001漏洞利用 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——UAF - PwnHarmonyOSWeb安全软件逆向
- Pwn-glibc高版本堆题攻击之safe unlink - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-CVE-2020-1054提权漏洞学习笔记 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——BufferOverflowNonPagedPool - PwnHarmonyOSWeb安全软件逆向
- CTF对抗-2022DASCTF Apr X FATE 防疫挑战赛-Reverse-奇怪的交易 - PwnHarmonyOSWeb安全软件逆向
- 编程技术-一个规避安装包在当前目录下被DLL劫持的想法 - PwnHarmonyOSWeb安全软件逆向
- CTF对抗-sql注入学习笔记 - PwnHarmonyOSWeb安全软件逆向
- Pwn-DamCTF and Midnight Sun CTF Qualifiers pwn部分wp - PwnHarmonyOSWeb安全软件逆向
- 软件逆向-OLLVM-deflat 脚本学习 - PwnHarmonyOSWeb安全软件逆向
- 软件逆向-3CX供应链攻击样本分析 - PwnHarmonyOSWeb安全软件逆向
- Android安全-某艺TV版 apk 破解去广告及源码分析 - PwnHarmonyOSWeb安全软件逆向
- Pwn-Hack-A-Sat 4 Qualifiers pwn部分wp - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞- AFL 源代码速通笔记 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-Netatalk CVE-2018-1160 复现及漏洞利用思路 - PwnHarmonyOSWeb安全软件逆向
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com