软件逆向-Pyd原理以及逆向实战 (一)函数
推荐 原创【软件逆向-Pyd原理以及逆向实战 (一)函数】此文章归类为:软件逆向。
一、前言
最近在分析一个国外某个体育游戏,热度最高的外挂样本。发现使用的是Python脚本并且Pyd编译后的,中间存在部分名称混淆并且Pyd的二进制函数量巨大,故而研究了一下Pyd逆向用来高效逆向这类样本。顺便记录一下方便后面查阅。(ps:pyd逆向内容还是挺多的,兜兜转转玩了一个月hhh)如果你觉得我的文章对你有帮助请帮忙点个赞吧。文章中有啥错误的位置欢迎指出。
二、Pyd原理
2.1Pyd是如何生成的
在研究Pyd逆向之前我们需要了解一下Python这种解释语言是如何变成Pyd的。
通过阅读Cython源码我了解一下,如下图:

本质上它是一个脚本语言向C语言转换的过程。所以在逆向之前我们需要能正确认识Python的二进制形式,也就是Cython的函数。
最关键的是,我们在Windows上编译出来的Pyd实际上就是一个动态库,同理linux平台下就是一个so。看图:

通过导出表就可以看出来导出了两个函数,一个是我们的dllmain,剩下一个文章下面会详细介绍。
2.2 Python函数
通过Cython源码我们梳理清楚我们的def 函数是怎么转换成C函数的。
这里就拿部分源码画图举例:

这是整个Cython的编译流程。
这个里面存在几个重要问题,
a. Python解释器如何知道Pyd中的函数信息?
b. python解释器怎么感知模块中的函数以及对象的信息
c. 虚拟机层和native层是如何互相调用以及交互的?
d. python函数最后会变成什么样子?
问题a :Python解释器如何知道Pyd中的函数信息
入口函数 PyInit_模块名
上面提到过,Pyd导出了两个一个是dllmain和一个PyInit_模块名的函数
PyInit_模块名就是关键。源码实现在ModuleNode.py,下面是部分实现代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | def generate_module_init_func(self, imported_modules, shared_utility_exporter, env, code): subfunction = self.mod_init_subfunction(self.pos, self.scope, code) self.generate_pymoduledef_struct(env, code) code.enter_cfunc_scope(self.scope) code.putln("") code.put_code_here(UtilityCode.load("PyModInitFuncType", "ModuleSetupCode.c")) modinit_func_name = EncodedString(f"PyInit_{env.module_name}") header3 = "__Pyx_PyMODINIT_FUNC %s(void)" % self.mod_init_func_cname('PyInit', env) # Optimise for small code size as the module init function is only executed once. code.putln("%s CYTHON_SMALL_CODE; /*proto*/" % header3) if self.scope.is_package: code.putln("#if !defined(CYTHON_NO_PYINIT_EXPORT) && (defined(_WIN32) || defined(WIN32) || defined(MS_WINDOWS))") code.putln("__Pyx_PyMODINIT_FUNC PyInit___init__(void) { return %s(); }" % ( self.mod_init_func_cname('PyInit', env))) code.putln("#endif")... .... |
PyInit_模块名 实际上会导出我们当前这个模块的函数信息。
Cython编译过程中对函数信息的处理:
这个是核心,通过源码来看,cython会经历这几个步骤:
1.收集函数信息
2.生成方法表
3.生成单个条目
4.生成模块定义
5.引用方法表
逆向我们需要关注的就是生成过程中的函数表__pyx_moduledef 和模块定义结构体__pyx_methods
这一部分定义是在我们的Python解释器的目录下,而Cython只是引入了这些结构,我拿3.11举例:
头文件路径:x:\xx\include\methodobject.h和moduleobject.h,methodobject.h
1 2 3 4 5 6 | struct PyMethodDef { const char *ml_name; /* The name of the built-in function/method */ PyCFunction ml_meth; /* The C function that implements it */ int ml_flags; /* Combination of METH_xxx flags */ const char *ml_doc; /* The __doc__ attribute, or NULL */}; |
1 2 3 4 5 6 7 8 9 10 11 | struct PyModuleDef { PyModuleDef_Base m_base; const char* m_name; const char* m_doc; Py_ssize_t m_size; PyMethodDef *m_methods; /* ← 指向函数表 */ PyModuleDef_Slot *m_slots; traverseproc m_traverse; inquiry m_clear; freefunc m_free;}; |
1 2 3 4 | #define METH_VARARGS 0x0001#define METH_KEYWORDS 0x0002#define METH_NOARGS 0x0004#define METH_O 0x0008 |
PyInit_模块名 在源码中的实现 ModuleNode.py:3092-3098:
1 2 3 4 5 6 7 | code.putln(header3)# CPython 3.5+ supports multi-phase module initialisation (gives access to __spec__, __file__, etc.)code.putln("#if CYTHON_PEP489_MULTI_PHASE_INIT")code.putln("{")code.putln("return PyModuleDef_Init(&%s);" % Naming.pymoduledef_cname)code.putln("}") |
生成出来的C代码应该是这样:
1 2 3 | PyMODINIT_FUNC PyInit_mymodule(void) { return PyModuleDef_Init(&__pyx_moduledef); /* ← 就这一行 */} |
在二进制底层中我们就可以通过导出函数,直接定位到我们想要的:
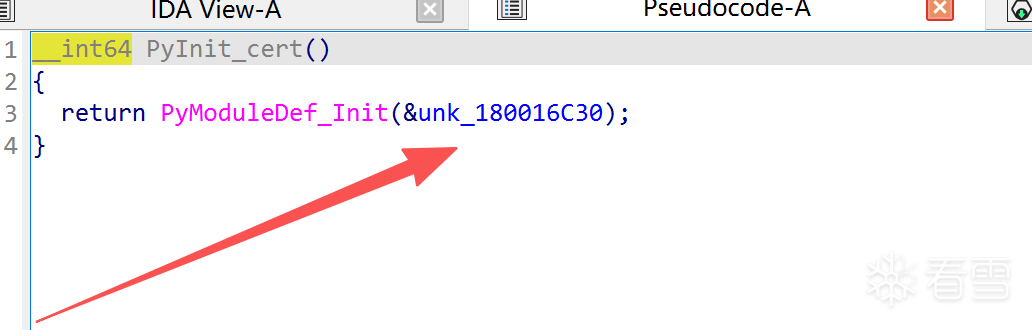
这个就是我们想要的__pyx_moduledef,这样就可以手工查看这个模块中的所有Python函数了。(如果不这样做,通过解释器层面需要import xxx,并且需要补环境才行,而且有时候可能还会遇到隐藏问题)
顺带定义一下ida的结构体
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | struct PyMethodDef { __int64 ml_name; __int64 ml_meth; int ml_flags; int _pad; __int64 ml_doc;};struct PyModuleDef { __int64 ob_refcnt; __int64 ob_type; __int64 m_init; __int64 m_index; __int64 m_copy; __int64 m_name; __int64 m_doc; __int64 m_size; __int64 m_methods; __int64 m_slots; __int64 m_traverse; __int64 m_clear; __int64 m_free;}; |
实战看一下:

当前这个函数表是没有的因为这个是一个类模型,所以不存在单一的函数。
问题b.python函解释器怎么感知模块中的对象以及对象的信息
当我们外部的脚本语言需要调用Pyc是怎么做的呢?从源码中分析简化流程后就是这样:
1 2 3 4 5 6 7 8 9 10 | import cert │ ▼PyInit_cert() ← 模块入口函数 │ ├─→ PyModuleDef_Init() ← 创建模块对象 │ ├─→ PyType_Ready(Certificate) ← 初始化类的 PyTypeObject │ └─→ PyObject_SetAttr(module, "Certificate", &type) ← 把类加到模块里 |
核心还是这个 PyInit_模块 的函数。在此之前我们需要了解一下PyTypeObject这个就是存储类信息的结构体,我们了解一下结构:
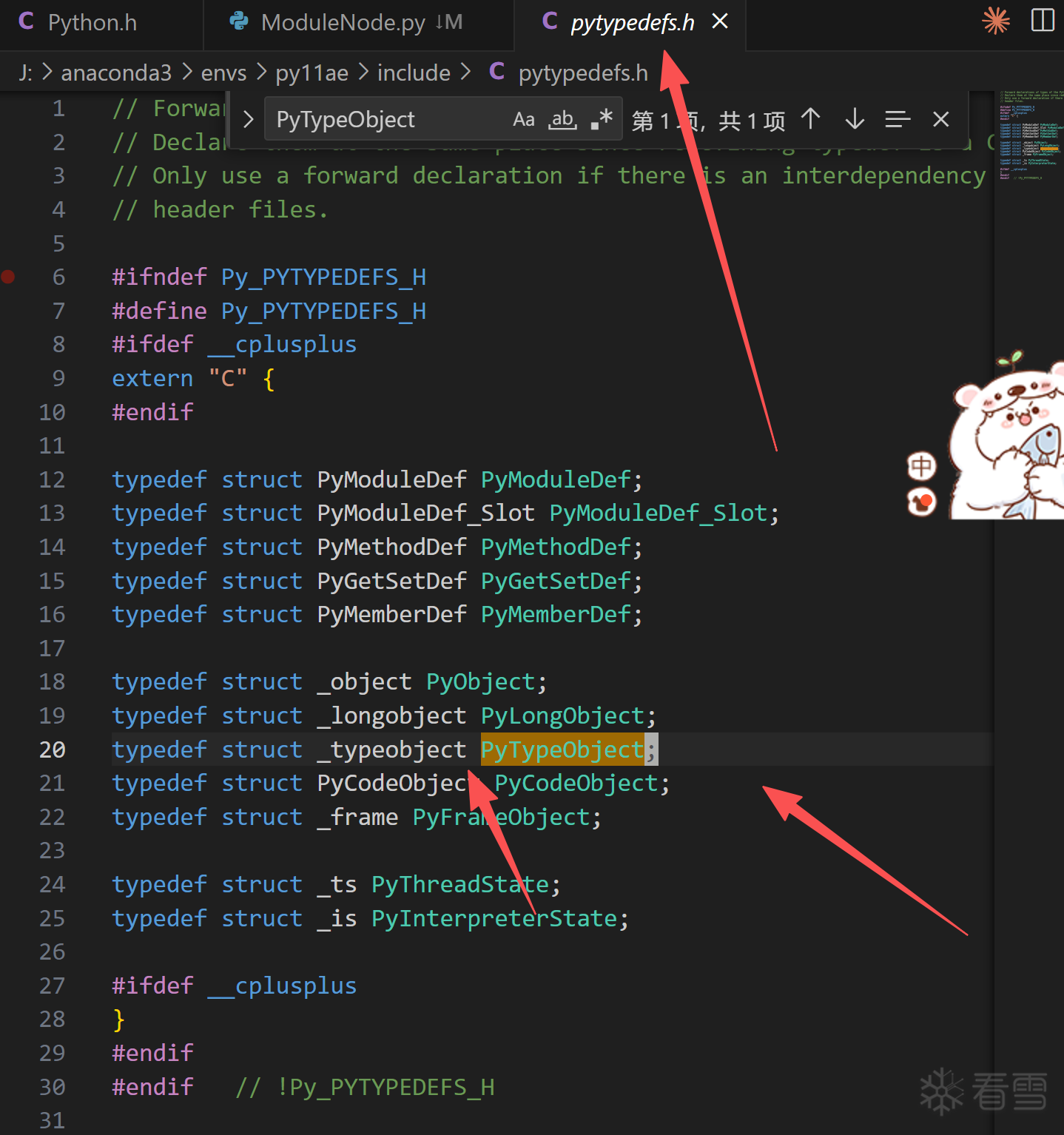
实现在cpython的解释器源码中(xxx:\xxx\cpython\Include\cpython\object.h):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 | struct _typeobject { PyObject_VAR_HEAD const char *tp_name; /* For printing, in format "<module>.<name>" */ Py_ssize_t tp_basicsize, tp_itemsize; /* For allocation */ /* Methods to implement standard operations */ destructor tp_dealloc; Py_ssize_t tp_vectorcall_offset; getattrfunc tp_getattr; setattrfunc tp_setattr; PyAsyncMethods *tp_as_async; /* formerly known as tp_compare (Python 2) or tp_reserved (Python 3) */ reprfunc tp_repr; /* Method suites for standard classes */ PyNumberMethods *tp_as_number; PySequenceMethods *tp_as_sequence; PyMappingMethods *tp_as_mapping; /* More standard operations (here for binary compatibility) */ hashfunc tp_hash; ternaryfunc tp_call; reprfunc tp_str; getattrofunc tp_getattro; setattrofunc tp_setattro; /* Functions to access object as input/output buffer */ PyBufferProcs *tp_as_buffer; /* Flags to define presence of optional/expanded features */ unsigned long tp_flags; const char *tp_doc; /* Documentation string */ /* Assigned meaning in release 2.0 */ /* call function for all accessible objects */ traverseproc tp_traverse; /* delete references to contained objects */ inquiry tp_clear; /* Assigned meaning in release 2.1 */ /* rich comparisons */ richcmpfunc tp_richcompare; /* weak reference enabler */ Py_ssize_t tp_weaklistoffset; /* Iterators */ getiterfunc tp_iter; iternextfunc tp_iternext; /* Attribute descriptor and subclassing stuff */ PyMethodDef *tp_methods; PyMemberDef *tp_members; PyGetSetDef *tp_getset; // Strong reference on a heap type, borrowed reference on a static type PyTypeObject *tp_base; PyObject *tp_dict; descrgetfunc tp_descr_get; descrsetfunc tp_descr_set; Py_ssize_t tp_dictoffset; initproc tp_init; allocfunc tp_alloc; newfunc tp_new; freefunc tp_free; /* Low-level free-memory routine */ inquiry tp_is_gc; /* For PyObject_IS_GC */ PyObject *tp_bases; PyObject *tp_mro; /* method resolution order */ PyObject *tp_cache; PyObject *tp_subclasses; PyObject *tp_weaklist; destructor tp_del; /* Type attribute cache version tag. Added in version 2.6 */ unsigned int tp_version_tag; destructor tp_finalize; vectorcallfunc tp_vectorcall;}; |
这个结构体就包含了当前这个模块这个类的所有信息:
比较重要的有这些
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | struct _typeobject { // 基本信息 const char *tp_name; // 类名 "cert.Certificate" Py_ssize_t tp_basicsize; // 实例对象大小 // 特殊方法 destructor tp_dealloc; // 析构函数 (__del__) reprfunc tp_repr; // __repr__ hashfunc tp_hash; // __hash__ ternaryfunc tp_call; // __call__ reprfunc tp_str; // __str__ getiterfunc tp_iter; // __iter__ iternextfunc tp_iternext; // __next__ initproc tp_init; // __init__ newfunc tp_new; // __new__ // ★ 最重要的 ★ PyMethodDef *tp_methods; // 类的所有方法表! PyMemberDef *tp_members; // 成员变量 PyGetSetDef *tp_getset; // property // 继承信息 PyTypeObject *tp_base; // 父类 PyObject *tp_bases; // 所有基类 PyObject *tp_mro; // 方法解析顺序}; |
基于这个我们就可以完整解析这个模块里面的内容了。
怎么找到这个表结构体?回到最开始的问题系统如何加载的。如图,(梳理的调用,链篇幅有限我就不一个一个找了):\
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | PyInit_cert() │ ModuleNode.py:3097 └─→ return PyModuleDef_Init(&__pyx_moduledef); │ │ ModuleNode.py:3668 └─→ m_slots = __pyx_moduledef_slots[] │ │ ModuleNode.py:3630 └─→ {Py_mod_exec, exec_func} │ │ ModuleNode.py:3227-3228 └─→ generate_type_init_code() │ │ ModuleNode.py:3907-3914 └─→ for entry in c_class_entries: generate_type_ready_code(entry) │ │ Nodes.py:5889 └─→ __Pyx_PyType_Ready(&PyTypeObject) |
所以在ida中我们可以通过PyModuleDef -> m_slots -> exec函数 -> PyType_Ready 调用,就能找到 PyTypeObject也就是我们的_typeobject。
slots的结构体定义:
1 2 3 4 | struct PyModuleDef_Slot { int slot; void *value;}; |
slots就是加载这个模块之前需要执行的函数来对整个pyd进行初始化。通过源码分析可以知道我们这个模块的类的初始化是在m_slots[1],并且是一个可变长的,遇到0则结束。生成的源码位置在这里:cython\Cython\Compiler\ModuleNode.py
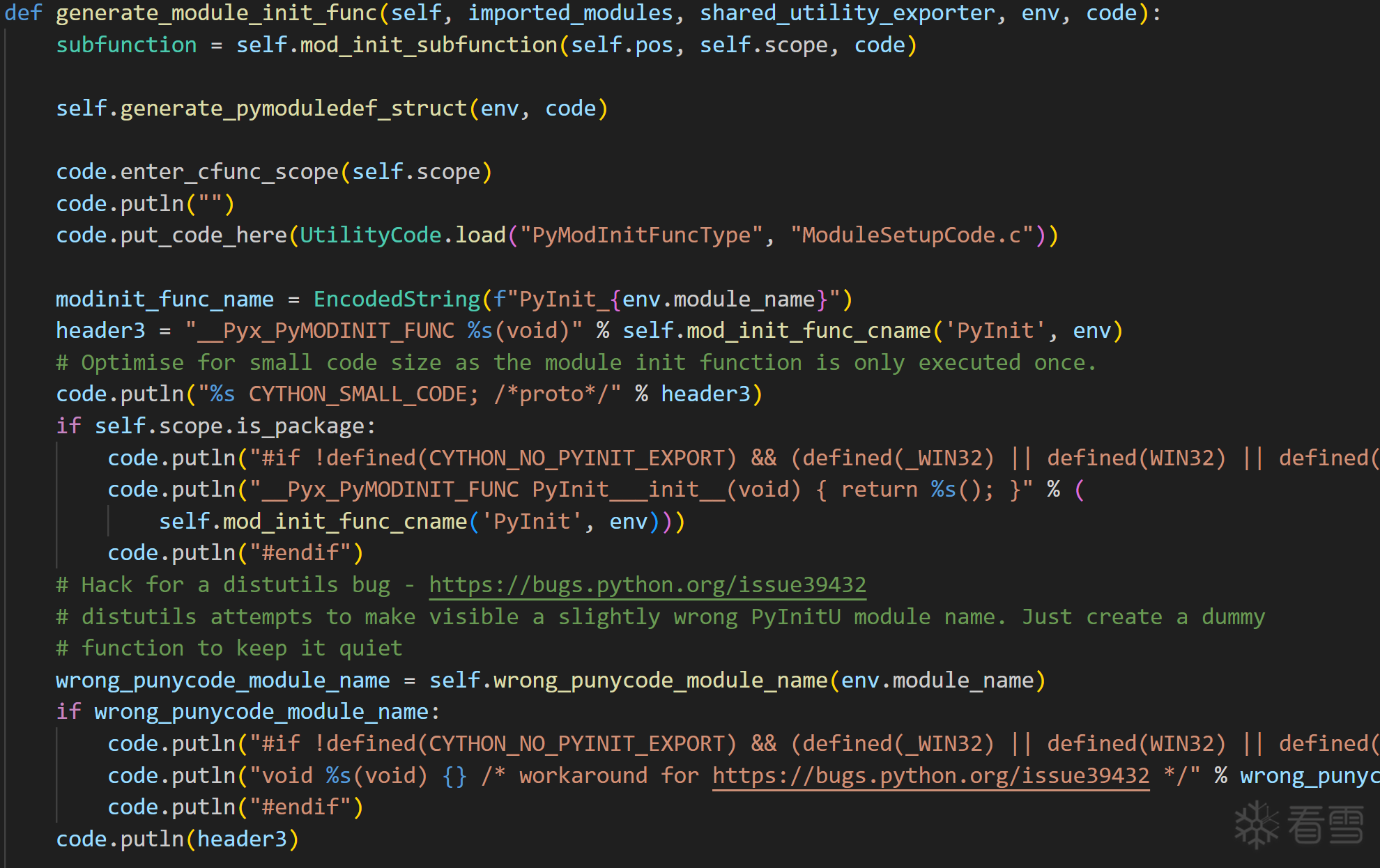
这个code.putln就是插入一行生成的代码,经过整理部分伪代码(如果存在好几个类的话):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | static CYTHON_SMALL_CODE int __pyx_pymod_exec_cert(PyObject *__pyx_m){ /*--- Global type/function init code ---*/ // 类1: Certificate if (__Pyx_PyType_Ready(&__pyx_type_4cert_Certificate) < 0) __PYX_ERR(...) if (PyObject_SetAttr(__pyx_m, __pyx_n_s_Certificate, (PyObject *)&__pyx_type_4cert_Certificate) < 0) __PYX_ERR(...) // 类2: User if (__Pyx_PyType_Ready(&__pyx_type_4cert_User) < 0) __PYX_ERR(...) if (PyObject_SetAttr(__pyx_m, __pyx_n_s_User, (PyObject *)&__pyx_type_4cert_User) < 0) __PYX_ERR(...) // 类3: Session if (__Pyx_PyType_Ready(&__pyx_type_4cert_Session) < 0) __PYX_ERR(...) if (PyObject_SetAttr(__pyx_m, __pyx_n_s_Session, (PyObject *)&__pyx_type_4cert_Session) < 0) __PYX_ERR(...) // 类N... return 0;} |
通过ida 跟踪验证一下上面的流程

这里就是slot
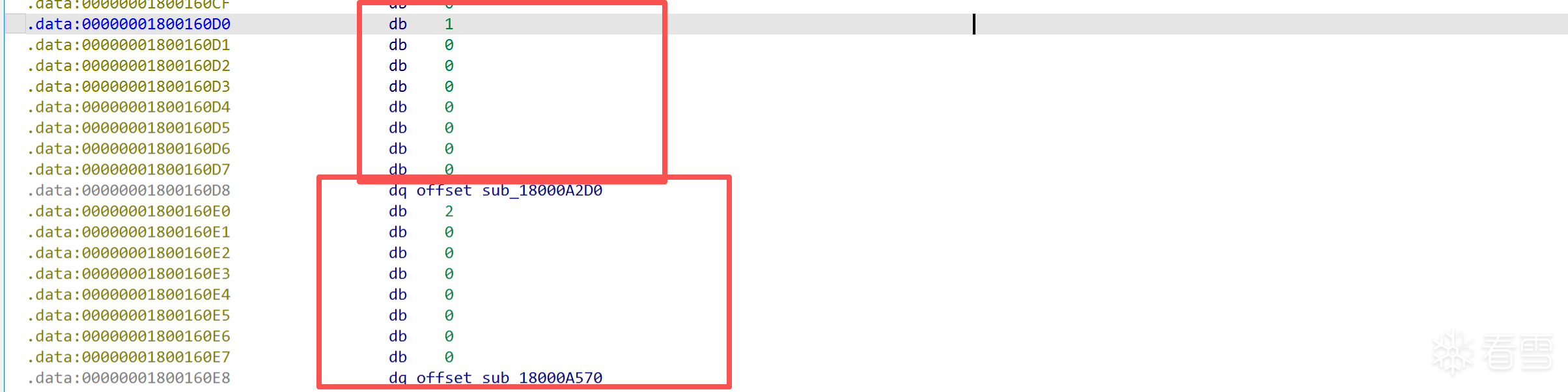
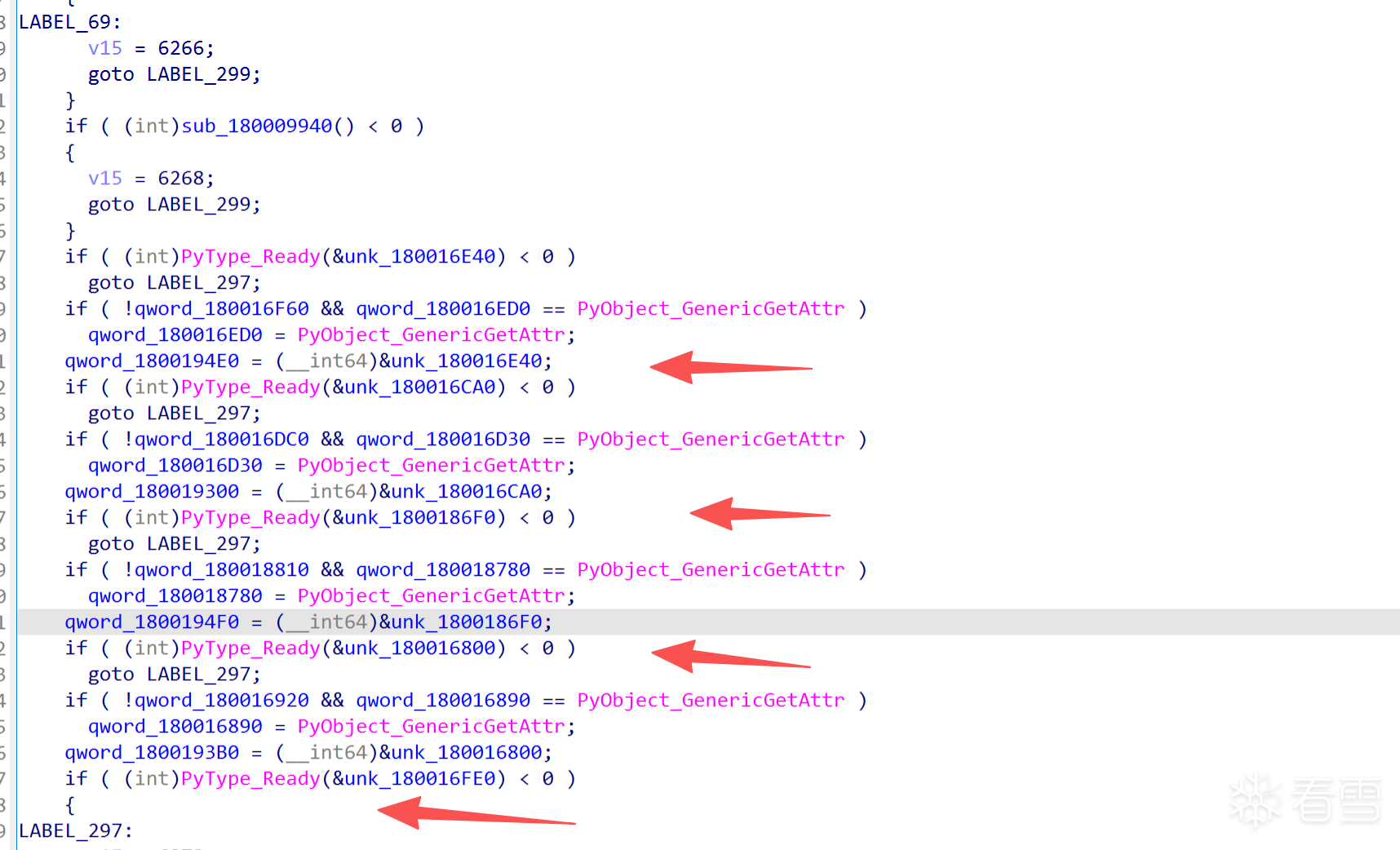
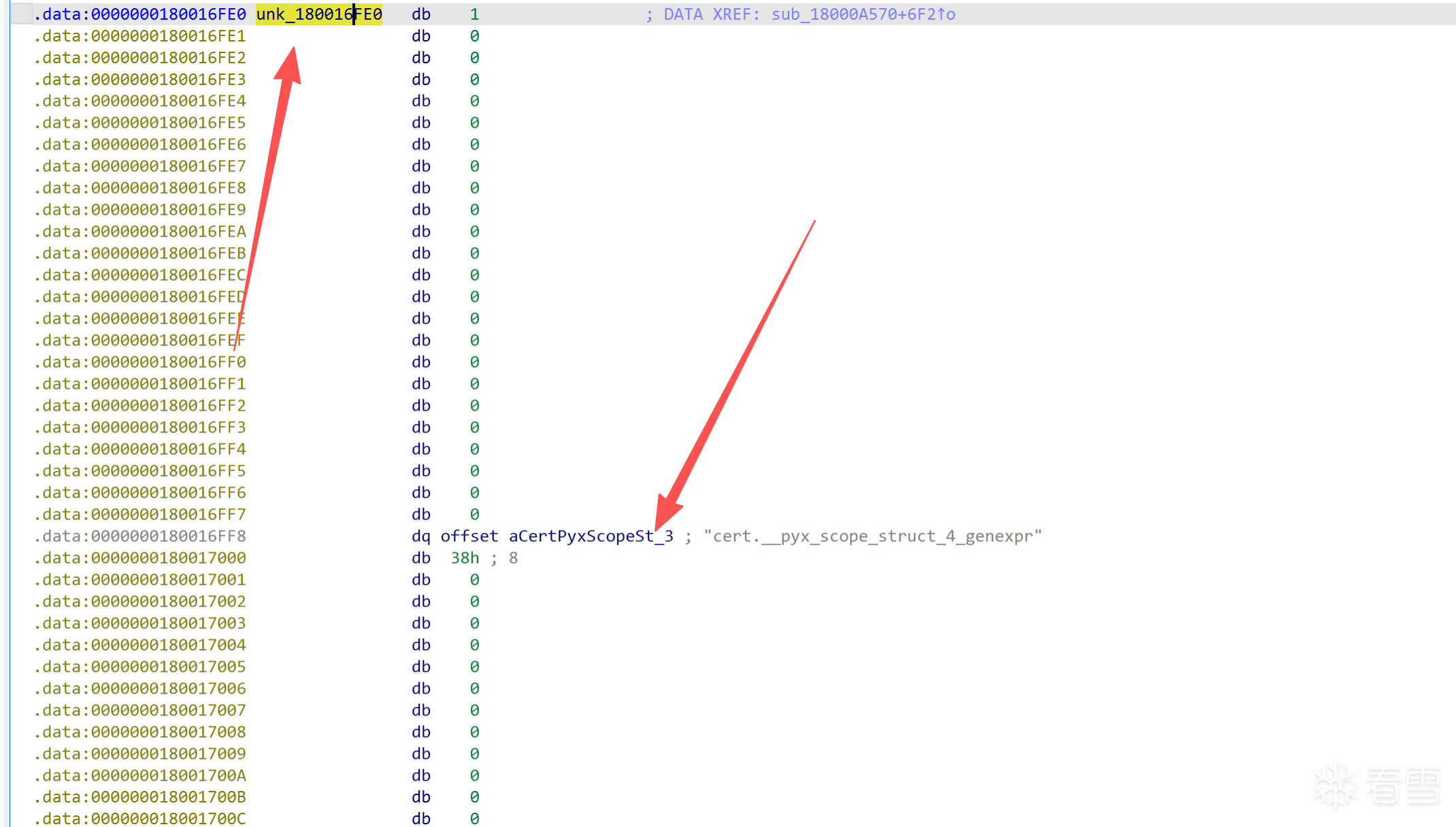
定义一下PyTypeObject结构体来解析一下它:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 | typedef __int64 Py_ssize_t;typedef unsigned __int64 size_t;struct PyObject { Py_ssize_t ob_refcnt; void *ob_type;};struct PyVarObject { struct PyObject ob_base; Py_ssize_t ob_size;};struct PyMethodDef { const char *ml_name; void *ml_meth; int ml_flags; const char *ml_doc;};struct PyTypeObject { struct PyVarObject ob_base; const char *tp_name; Py_ssize_t tp_basicsize; Py_ssize_t tp_itemsize; void *tp_dealloc; Py_ssize_t tp_vectorcall_offset; void *tp_getattr; void *tp_setattr; void *tp_as_async; void *tp_repr; void *tp_as_number; void *tp_as_sequence; void *tp_as_mapping; void *tp_hash; void *tp_call; void *tp_str; void *tp_getattro; void *tp_setattro; void *tp_as_buffer; unsigned __int64 tp_flags; const char *tp_doc; void *tp_traverse; void *tp_clear; void *tp_richcompare; Py_ssize_t tp_weaklistoffset; void *tp_iter; void *tp_iternext; struct PyMethodDef *tp_methods; void *tp_members; void *tp_getset; struct PyTypeObject *tp_base; struct PyObject *tp_dict; void *tp_descr_get; void *tp_descr_set; Py_ssize_t tp_dictoffset; void *tp_init; void *tp_alloc; void *tp_new; void *tp_free; void *tp_is_gc; struct PyObject *tp_bases; struct PyObject *tp_mro; struct PyObject *tp_cache; struct PyObject *tp_subclasses; struct PyObject *tp_weaklist; void *tp_del; unsigned int tp_version_tag; int _padding; void *tp_finalize; void *tp_vectorcall;}; |

注意!!!这样找到的是静态创建的对象,实际上都是一些内部对象,并不是导出的!!!
导出的是动态创建的!!
接下来讲一下动态创建。
什么时机会创建?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import cert │ ▼PyInit_cert() ← Python 调用入口 │ ▼返回 PyModuleDef (带 m_slots) │ ▼Python 解释器看到 Py_mod_exec slot │ ▼调用 exec 函数 (sub_18000A570) ← 这时候开始创建! │ ├── 1. 初始化内部 scope struct (PyType_Ready) ├── 2. 导入依赖模块 ├── 3. 创建方法字典 dict = {} ├── 4. 创建每个方法对象,放入 dict ├── 5. type("Certificate", (), dict) ← 类在这里诞生! └── 6. module.__dict__["Certificate"] = class ▼import 完成,Certificate 可用 |
说白了也在exec里面,对实现感兴趣可以重点看一下这个函数generate_execution_code,这里展示稍微一下动态创建的Cython代码是什么:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 | /* ==================== 第1步:创建类字典 ==================== */// 来源: Nodes.py:5334 - self.dict.generate_evaluation_code(code)// ObjectHandling.c:1419 - PyDict_New__pyx_t_1 = PyDict_New(); // 创建空字典if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 10, __pyx_L1_error)__Pyx_GOTREF(__pyx_t_1);/* ==================== 第2步:创建方法并添加到字典 ==================== */// 来源: CythonFunction.c:1335 - __Pyx_CyFunction_New// 来源: ObjectHandling.c:1423 - __Pyx_SetNameInClass// 创建 __init__ 方法__pyx_t_2 = __Pyx_CyFunction_New( &__pyx_mdef_4cert_11Certificate_1__init__, // PyMethodDef* 0, // flags __pyx_n_s_Certificate___init__, // qualname NULL, // closure __pyx_n_s_cert, // module name __pyx_d, // globals NULL // code);if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 11, __pyx_L1_error)__Pyx_GOTREF(__pyx_t_2);// 把 __init__ 添加到类字典if (__Pyx_SetNameInClass(__pyx_t_1, __pyx_n_s_init, __pyx_t_2) < 0) __PYX_ERR(0, 11, __pyx_L1_error)__Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;// 创建 verify 方法__pyx_t_2 = __Pyx_CyFunction_New( &__pyx_mdef_4cert_11Certificate_3verify, // PyMethodDef* 0, __pyx_n_s_Certificate_verify, NULL, __pyx_n_s_cert, __pyx_d, NULL);if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 14, __pyx_L1_error)__Pyx_GOTREF(__pyx_t_2);// 把 verify 添加到类字典if (__Pyx_SetNameInClass(__pyx_t_1, __pyx_n_s_verify, __pyx_t_2) < 0) __PYX_ERR(0, 14, __pyx_L1_error)__Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0;/* ==================== 第3步:调用 type() 创建类 ==================== */// 来源: ExprNodes.py:10180 - __Pyx_Py3ClassCreate// 来源: ObjectHandling.c:1257__pyx_t_2 = __Pyx_Py3ClassCreate( (PyObject*)&PyType_Type, // metaclass = type __pyx_n_s_Certificate, // name = "Certificate" __pyx_empty_tuple, // bases = () __pyx_t_1, // dict = {__init__: func, verify: func} NULL, // mkw = NULL 0, // calculate_metaclass 0 // allow_py2_metaclass);if (unlikely(!__pyx_t_2)) __PYX_ERR(0, 10, __pyx_L1_error)__Pyx_GOTREF(__pyx_t_2);__Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;/* ==================== 第4步:注册到模块字典 ==================== */// 来源: Nodes.py:5364 - self.target.generate_assignment_codeif (PyDict_SetItem(__pyx_d, __pyx_n_s_Certificate, __pyx_t_2) < 0) __PYX_ERR(0, 10, __pyx_L1_error)__Pyx_DECREF(__pyx_t_2); __pyx_t_2 = 0; |
如何找到呢?重点就是这个,在函数内找到这个 PyObject_Call(PyType_Type....)核心就是它PyType_Type

所以动态创建的也就是普通类是没有静态对象信息的结构体,但是我们还是可以从代码中分析找到函数表,核心就是找到 _Pyx_CyFunction_New。

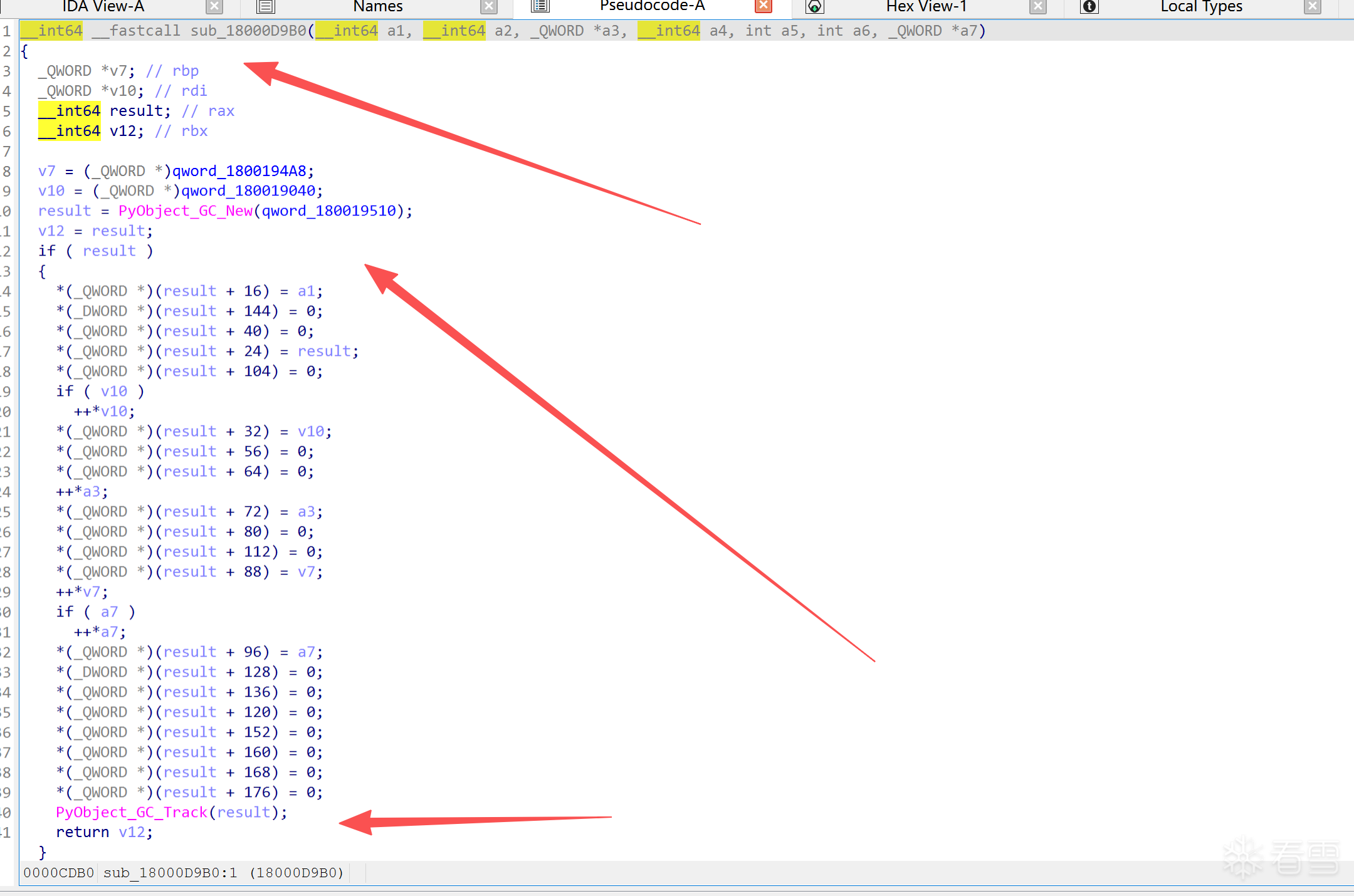
根据特征码可以吧整个类信息都给分析出来,不用补全环境,并且打印函数地址。这些都是这个模块里面的成员方法:
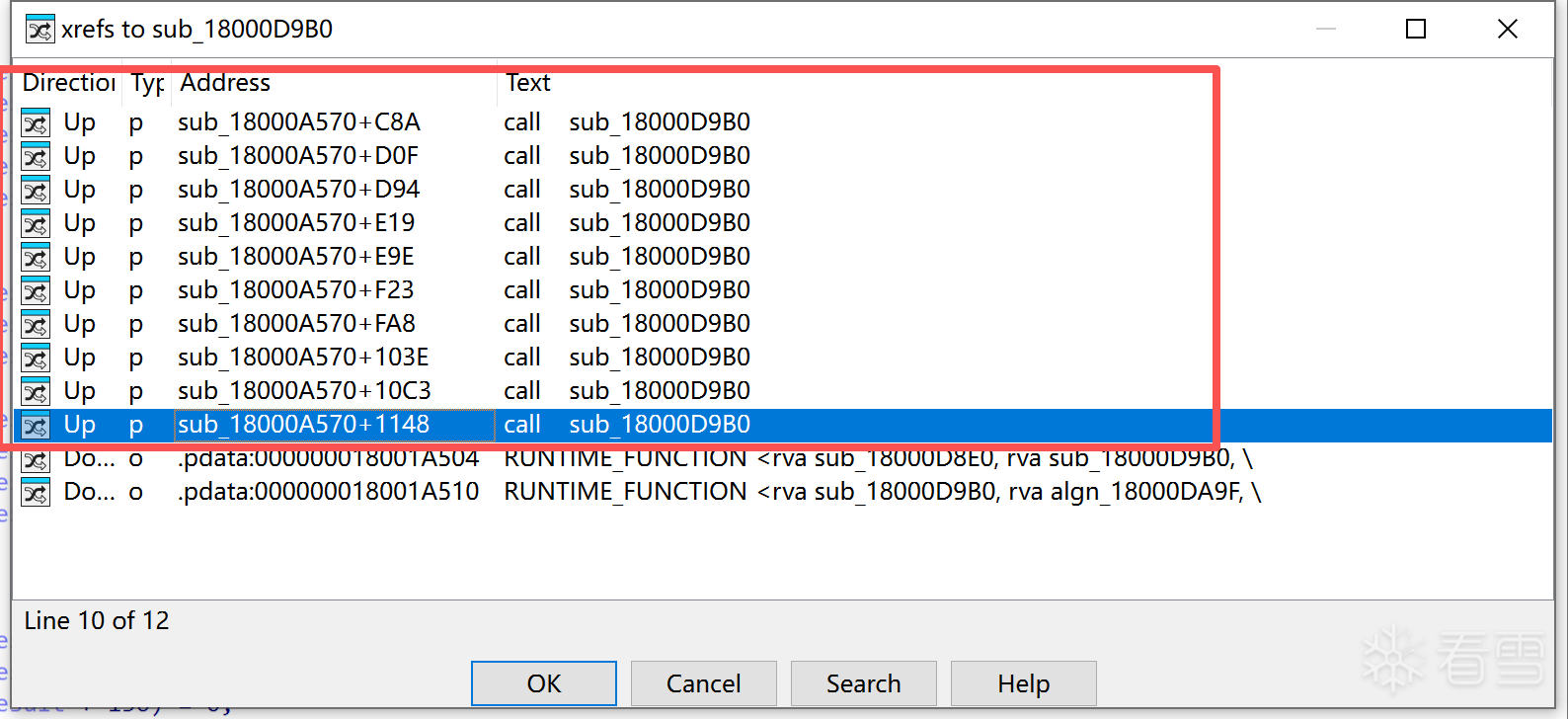
参数1就是 PyMethodDef


问题c. 解释器层和native层是如何互相调用以及交互的?
我们逆向的时候核心点就是,这些二进制函数是怎么进入解释器层的?怎么调用的外部函数or方法?
分情况讨论
1.PYD内调用
Pyd内a.xx ——》b.xx的时候因为在一个pyd会调用优化后的 `__Pyx_PyObject 优化的调用函数,并且根据优化就不会进入解释器层,这样加快程序运行。
2.Pyd调用另外一个pyd
当pyd内调用另一个Pyd函数的时候:a.xx ->pydb.c.xxx 这个时候也会经过 __Pyx_PyObject,但是首先需要获取外部pyd的函数才能调用
流程如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | 1. PyImport_ImportModule("pyd_B") → 获取 pyd_B 的模块对象 2. PyObject_GetAttr(pyd_B_module, "some_func") → 获取函数对象(是个 PyCFunction) 3. __Pyx_PyObject_FastCall(func_obj, args, nargs) → pyd_A 内部的包装函数 4. 检查 func_obj 的类型和标志 ├─ 如果是 METH_O: 直接调用 func_obj->ml_meth(self, arg) │ 这个指针指向 pyd_B 里的 C 函数 │ └─ 否则: PyVectorcall_Function() 或 PyObject_Call() 5. pyd_B 里的 __pyx_pw_some_func() 执行 |
我找一个例子:
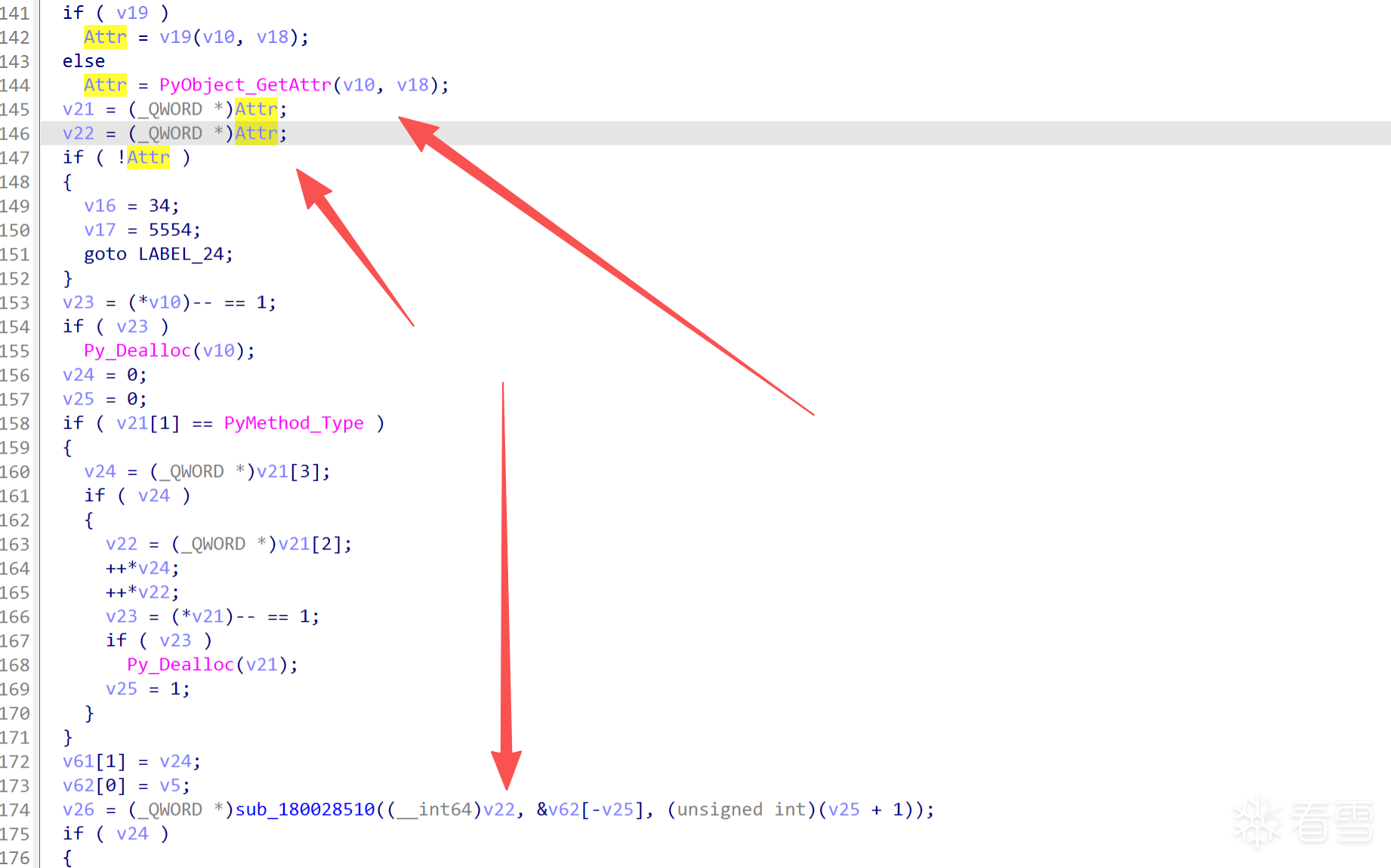
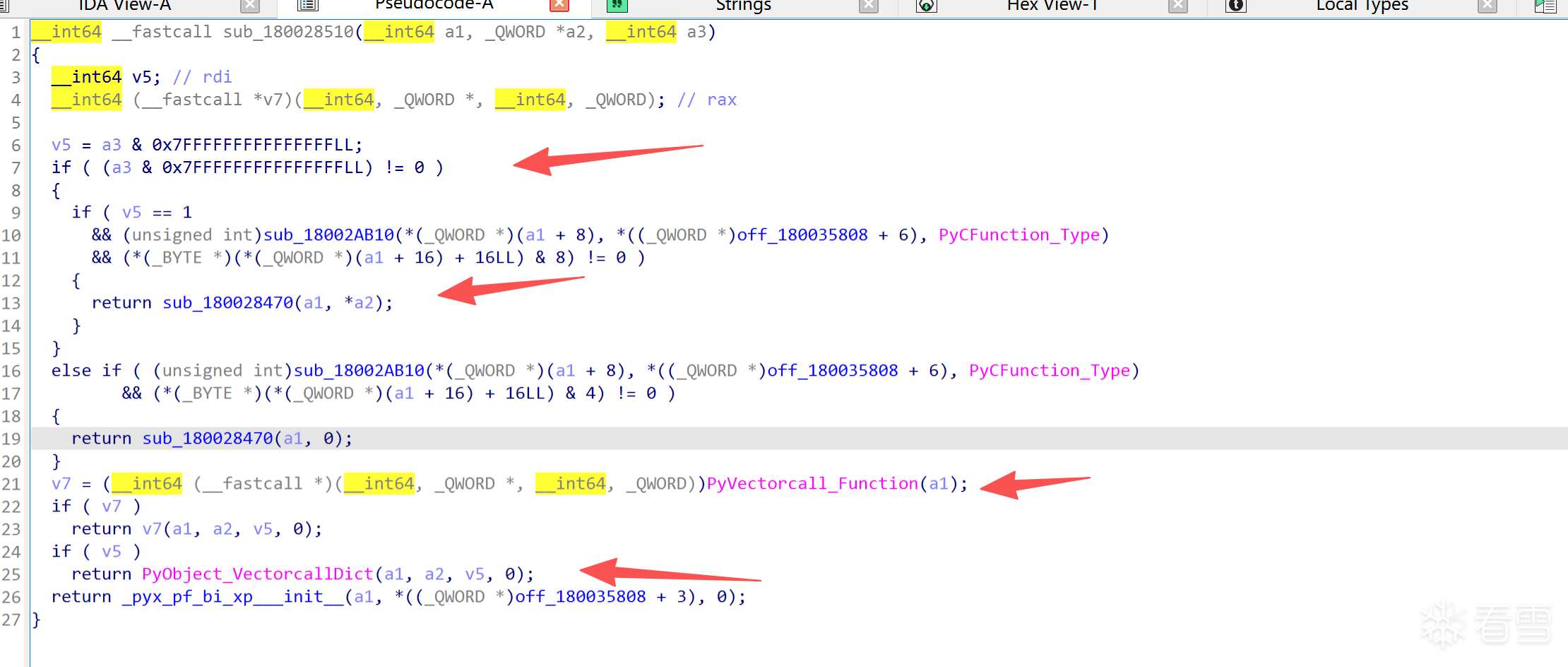
3.Pyd进解释器层调用解释器里面的函数
则直接会调用pythonxx..dll中的导出函数,主要是这几个:
1 2 3 4 5 | "PyObject_Call","PyObject_CallObject","PyObject_CallNoArgs","PyObject_CallOneArg","_PyObject_Call" |
核心主要就是这个PyObject_Call
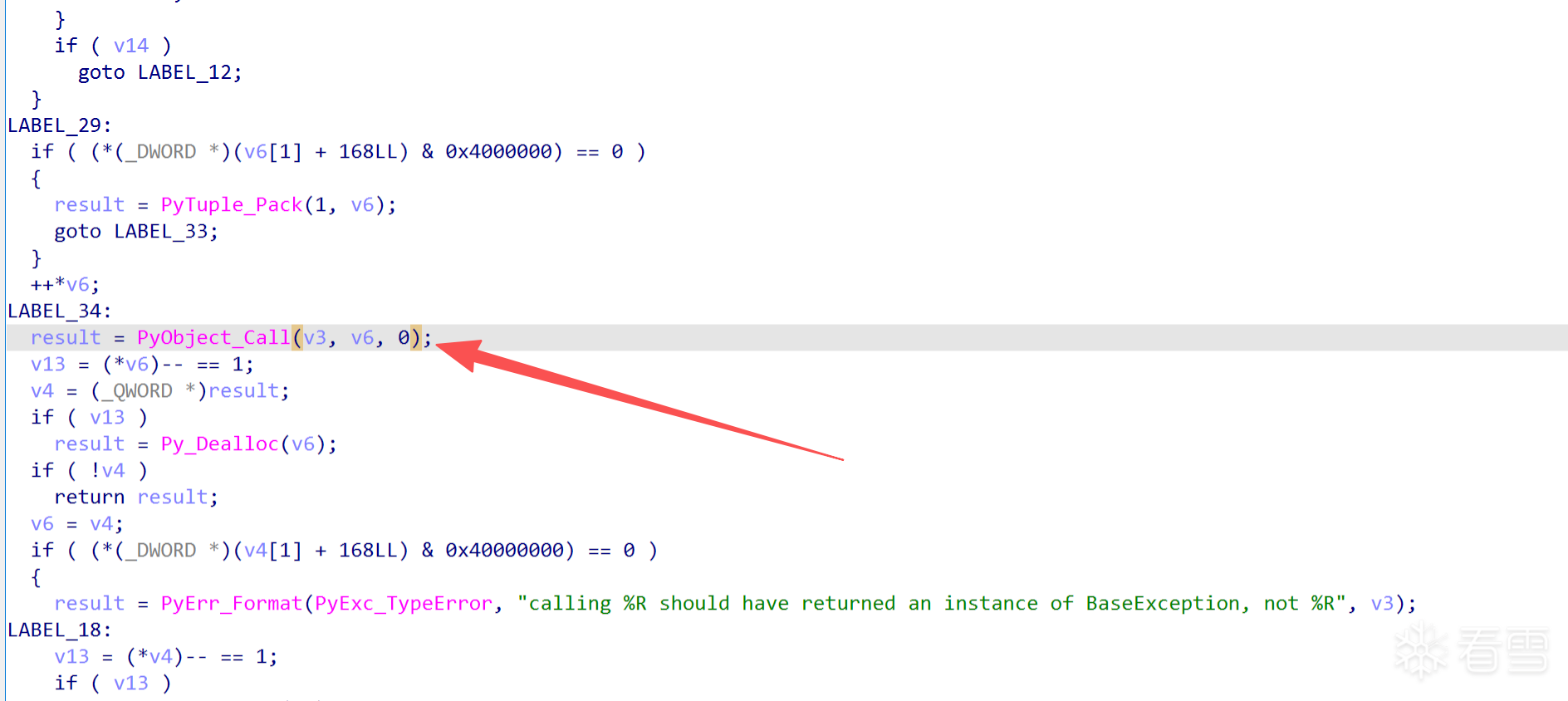
调用 Python 函数:
| Cython 函数 | 源码位置 | 作用 |
|---|---|---|
__Pyx_PyObject_Call |
ObjectHandling.c:2544 | 通用调用 (func, args, kwargs) |
__Pyx_PyObject_FastCall |
ObjectHandling.c:2268 | 快速调用 (vectorcall) |
__Pyx_PyObject_CallNoArg |
ObjectHandling.c:2626 | 无参数调用 |
__Pyx_PyObject_CallOneArg |
ObjectHandling.c:2613 | 单参数调用 |
__Pyx_PyObject_Call2Args |
ObjectHandling.c:2600 | 双参数调用 |
__Pyx_PyObject_FastCallMethod |
ObjectHandling.c:2321 | 调用方法 |
我初步的介绍一下这些函数是干什么:
- Pyx_PyObject_Call - 通用调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | static CYTHON_INLINE PyObject* __Pyx_PyObject_Call( PyObject *func, // 可调用对象 PyObject *arg, // args 元组 PyObject *kw // kwargs 字典(可为 NULL)) { ternaryfunc call = Py_TYPE(func)->tp_call; if (unlikely(!call)) return PyObject_Call(func, arg, kw); Py_EnterRecursiveCall(" while calling a Python object"); result = (*call)(func, arg, kw); // 通过 tp_call 槽调用 Py_LeaveRecursiveCall(); return result;} |
一般是这种变参:func(*args, **kwargs) 不定参数调用
- Pyx_PyObject_FastCall - 快速调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | #define __Pyx_PyObject_FastCall(func, args, nargs) \ __Pyx_PyObject_FastCallDict(func, args, (size_t)(nargs), NULL)static CYTHON_INLINE PyObject* __Pyx_PyObject_FastCallDict( PyObject *func, PyObject *const *args, // 参数数组(不是元组!) size_t nargs, // 参数个数 PyObject *kwargs) { // 优化:0 参数且是 C 函数 if (nargs == 0 && kwargs == NULL) { if (__Pyx_CyOrPyCFunction_Check(func) && (flags & METH_NOARGS)) return __Pyx_PyObject_CallMethO(func, NULL); } // 优化:1 参数且是 C 函数 if (nargs == 1 && kwargs == NULL) { if (__Pyx_CyOrPyCFunction_Check(func) && (flags & METH_O)) return __Pyx_PyObject_CallMethO(func, args[0]); } // 使用 vectorcall 协议(Python 3.9+) vectorcallfunc f = __Pyx_PyVectorcall_Function(func); if (f) return f(func, args, nargs, NULL); // 回退到普通调用 return __Pyx_PyObject_Call(func, args_tuple, kwargs);} |
一般是这种:func(a, b, c) 固定参数调用。所以这个是笔者见到最多的最多调用方式!
- __Pyx_PyObject_CallNoArg - 无参数调用
1 2 3 4 | static CYTHON_INLINE PyObject* __Pyx_PyObject_CallNoArg(PyObject *func) { PyObject *arg[2] = {NULL, NULL}; return __Pyx_PyObject_FastCall(func, arg + 1, 0 | __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET);} |
obj.method()无参方法
- __Pyx_PyObject_CallOneArg - 单参数调用
源码位置: ObjectHandling.c:2540
1 2 3 4 | static CYTHON_INLINE PyObject* __Pyx_PyObject_CallOneArg(PyObject *func, PyObject *arg) { PyObject *args[2] = {NULL, arg}; return __Pyx_PyObject_FastCall(func, args + 1, 1 | __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET);} |
- __Pyx_PyObject_Call2Args - 双参数调用
1 2 3 4 5 6 7 8 | static CYTHON_INLINE PyObject* __Pyx_PyObject_Call2Args( PyObject* function, PyObject* arg1, PyObject* arg2) { PyObject *args[3] = {NULL, arg1, arg2}; return __Pyx_PyObject_FastCall(function, args + 1, 2 | __Pyx_PY_VECTORCALL_ARGUMENTS_OFFSET);} |
- __Pyx_PyObject_FastCallMethod - 调用方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | static PyObject *__Pyx_PyObject_FastCallMethod( PyObject *name, // 方法名(字符串对象) PyObject *const *args, // args[0] = self 对象 size_t nargsf // 参数个数(包含 self)) { PyObject *result; // 1. 从 self 获取方法 PyObject *attr = PyObject_GetAttr(args[0], name); if (unlikely(!attr)) return NULL; // 2. 调用方法(跳过 args[0],因为绑定方法已包含 self) result = __Pyx_PyObject_FastCall(attr, args + 1, nargsf - 1); Py_DECREF(attr); return result;} |
obj.fun()调用场景,这种也是非常多的
这些函数都是没有符号名的,要么自己去做sig让ida识别,或者是自己肉眼识别。(不过这也是一个非常好利用的点,后面会讲)
问题d. python函数最后会变成什么样子?
这个问题我们直接通过底层就能看清楚,我先说一下,实际上python那种弱类型的特点,但是碰上了cpp这种强类型语言,所以他必须有一个包装函数来处理这些参数问题。我拿样本中驱动代码的一个方法举例:(下面是从ida里面拷贝出来的f5代码)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | _QWORD *__fastcall sub_180005100(__int64 a1, __int64 *a2, __int64 a3, __int64 a4){ __int64 *v5; // rbp int v7; // esi __int64 v8; // rax __int64 v9; // rbx __int64 v10; // rbx __int64 v11; // rdx _QWORD v13[5]; // [rsp+40h] [rbp-28h] BYREF __int64 v14; // [rsp+78h] [rbp+10h] BYREF v5 = &a2[a3]; v14 = 0; v7 = a4; v13[0] = (char *)off_180020888 + 1152; v13[1] = 0; if ( !a4 ) { if ( a3 == 1 ) { v8 = *a2; return sub_180005270(a1, v8); } goto LABEL_14; } if ( a3 ) { if ( a3 == 1 ) { v8 = *a2; v9 = *(_QWORD *)(a4 + 16); v14 = *a2; goto LABEL_7; }LABEL_14: PyErr_Format( PyExc_TypeError, "%.200s() takes %.8s %zd positional argument%.1s (%zd given)", "recv", "exactly", 1u, byte_18001B650, a3); v11 = 5147; goto LABEL_15; } v10 = *(_QWORD *)(a4 + 16); v8 = sub_180014CE0(a4, v5, *((_QWORD *)off_180020888 + 144)); v14 = v8; if ( !v8 ) { if ( PyErr_Occurred() ) { v11 = 5131; goto LABEL_15; } goto LABEL_14; } v9 = v10 - 1;LABEL_7: if ( v9 > 0 ) { if ( (int)sub_180014F00(v7, (_DWORD)v5, (unsigned int)v13, a4, (__int64)&v14, a3, (__int64)"recv") < 0 ) { v11 = 5136;LABEL_15: sub_180017F40("divertx.Divert.recv", v11, 112, "divertx.py"); return 0; } v8 = v14; } return sub_180005270(a1, v8);} |
这个实际上就是一个标准的包装函数,也就是python的入口,他有几个重要标志:
- 一定有异常处理 PyExc_TypeError
- 一定会有参数检查
- 最后一行ret 肯定是调用真实的python函数
通过这个特征我们可以拿到这个函数是是几个参数的,这个非常关键。接下里我展示一下如何静态分析判断函数参数以及函数名和编码信息
通过Python的异常回溯信息可以判断这个函数对应的是哪个成员方法:
1 | sub_180017F40("divertx.Divert.recv", v11, 112, "divertx.py"); |
通过源码分析可得知参数如下:
源码位置:Exceptions.c:840-841 和 972-1012
1 2 3 4 5 6 7 | // 函数签名static void __Pyx_AddTraceback( const char *funcname, // a1: 函数完整限定名 (如 "divertx.Divert.recv") int c_line, // a2: C 源码行号 (生成的 .c 文件中的行号) int py_line, // a3: Python 源码行号 (原始 .py 文件中的行号) const char *filename // a4: Python 源文件名 (如 "divertx.py")); |
参数数量可以直接通过伪代码看出来这里在对参数数量进行检查:
1 | if ( a3 == 1 ) |
最后在讲一下这个包装函数在Cython中怎么实现的:
首先这个包装函数有好几种变体,会根据不同参数来生成不同的包装类这样来优化调用,我整理了一个表格如下:
| 标志 | 值 | Python 调用 | C 函数签名 |
|---|---|---|---|
METH_NOARGS |
0x0004 | obj.method() |
PyObject* func(PyObject *self) |
METH_O |
0x0008 | obj.method(x) |
PyObject* func(PyObject *self, PyObject *arg) |
METH_VARARGS |
0x0001 | obj.method(*args) |
PyObject* func(PyObject *self, PyObject *args) |
METH_VARARGS | METH_KEYWORDS |
0x0003 | obj.method(*args, **kw) |
PyObject* func(PyObject *self, PyObject *args, PyObject *kw) |
METH_FASTCALL |
0x0080 | obj.method(a, b) |
PyObject* func(PyObject *self, PyObject *const *args, Py_ssize_t nargs) |
METH_FASTCALL | METH_KEYWORDS |
0x0083 | obj.method(a, b, x=1) |
PyObject* func(PyObject *self, PyObject *const *args, Py_ssize_t nargs, PyObject *kwnames) |
三、 分析手法以及利用的点
当我们了解了这么多以后,实际上可以发现,Pyd调用有一个致命缺陷。就是他的外部调用都依赖于包装函数
这里还是抛出三个问题:
一个Pyd程序如何定位?
遇到名称混淆处理?
怎么处理编译后庞大的Pyd函数?
正常Pyd函数逆向还原应该是什么姿势
首先在逆向之前我们肯定需要有一个定位点的,这里主要的定位手法就是如下两种:
第一种:
如果能运行环境。获取可以补全环境,最好还实在解释器层进行处理。通过打印Pyd信息获取里面的元数据,可以猜出我们需要的分析函数
第二种:静态分析
这里手法比较多:通过写ida脚本提取识别所有的函数,方法函数。主要可以通过包装函数中的 __Pyx_AddTraceback 函数即可拿到所有函数
写一个ida脚本就行了,给一个脚本吧:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 | import idaapiimport idautilsimport idcTRACEBACK_ADDR = 0x180017F40SKIP_FUNCS = [ "__security_check_cookie", "__GSHandlerCheck", "_guard_dispatch_icall",]def get_string_at(ea): s = idc.get_strlit_contents(ea) if s: try: return s.decode() except: pass ret = "" while True: c = idc.get_wide_byte(ea) if c == 0 or c is None: break if c < 0x20 or c > 0x7E: break ret += chr(c) ea += 1 if len(ret) > 500: break return ret if ret else Nonedef make_valid_name(name): ret = "" for c in name: if c.isalnum() or c == "_": ret += c else: ret += "_" if ret and ret[0].isdigit(): ret = "_" + ret return retdef find_impl_func(wrapper_ea): func = idaapi.get_func(wrapper_ea) if not func: return None ea = func.start_ea end = func.end_ea candidates = [] while ea < end: if idc.print_insn_mnem(ea) == "call": target = idc.get_operand_value(ea, 0) if target and target != TRACEBACK_ADDR: target_name = idc.get_func_name(target) skip = False if target_name: for sf in SKIP_FUNCS: if sf in target_name: skip = True break if not skip: candidates.append(target) ea = idc.next_head(ea) if not candidates: return None for c in candidates: name = idc.get_func_name(c) if name and name.startswith("sub_"): return c return candidates[0] if candidates else Nonedef analyze_call(call_ea): ea = call_ea for _ in range(30): ea = idc.prev_head(ea) if ea == idc.BADADDR: break mnem = idc.print_insn_mnem(ea) if mnem in ["call", "jmp", "ret", "retn"]: break if mnem in ["lea", "mov"]: op0 = idc.print_operand(ea, 0).lower() if op0 in ["rcx", "ecx"]: val = idc.get_operand_value(ea, 1) if val: s = get_string_at(val) if s: return s return Nonedef main(): print("=" * 60) print("Cython Function Extractor & Renamer") print("=" * 60) xrefs = list(idautils.XrefsTo(TRACEBACK_ADDR)) print("[+] Found " + str(len(xrefs)) + " xrefs to __Pyx_AddTraceback") print("") functions = [] seen_wrappers = set() for xref in xrefs: if xref.type not in [idaapi.fl_CN, idaapi.fl_CF]: continue funcname = analyze_call(xref.frm) if not funcname: continue func = idaapi.get_func(xref.frm) if not func: continue if func.start_ea in seen_wrappers: continue seen_wrappers.add(func.start_ea) impl = find_impl_func(func.start_ea) functions.append((funcname, func.start_ea, impl)) print("-" * 60) print("%-50s %s" % ("Function", "Address")) print("-" * 60) renamed_count = 0 for funcname, wrapper, impl in functions: short_name = funcname if len(short_name) > 48: short_name = short_name[:45] + "..." print("%-50s %s" % (short_name, hex(wrapper))) wrapper_name = "__pyx_pw_" + make_valid_name(funcname) old_name = idc.get_func_name(wrapper) if old_name and old_name.startswith("sub_"): idc.set_name(wrapper, wrapper_name, idc.SN_NOWARN) print(" -> " + wrapper_name) renamed_count += 1 if impl: impl_name = "__pyx_pf_" + make_valid_name(funcname) old_name = idc.get_func_name(impl) if old_name and old_name.startswith("sub_"): idc.set_name(impl, impl_name, idc.SN_NOWARN) print(" -> " + impl_name + " (impl)") renamed_count += 1 print("-" * 60) print("[+] Total: " + str(len(functions)) + " functions") print("[+] Renamed: " + str(renamed_count) + " functions")main() |
效果如图:
我们把函数名给还原回来了:
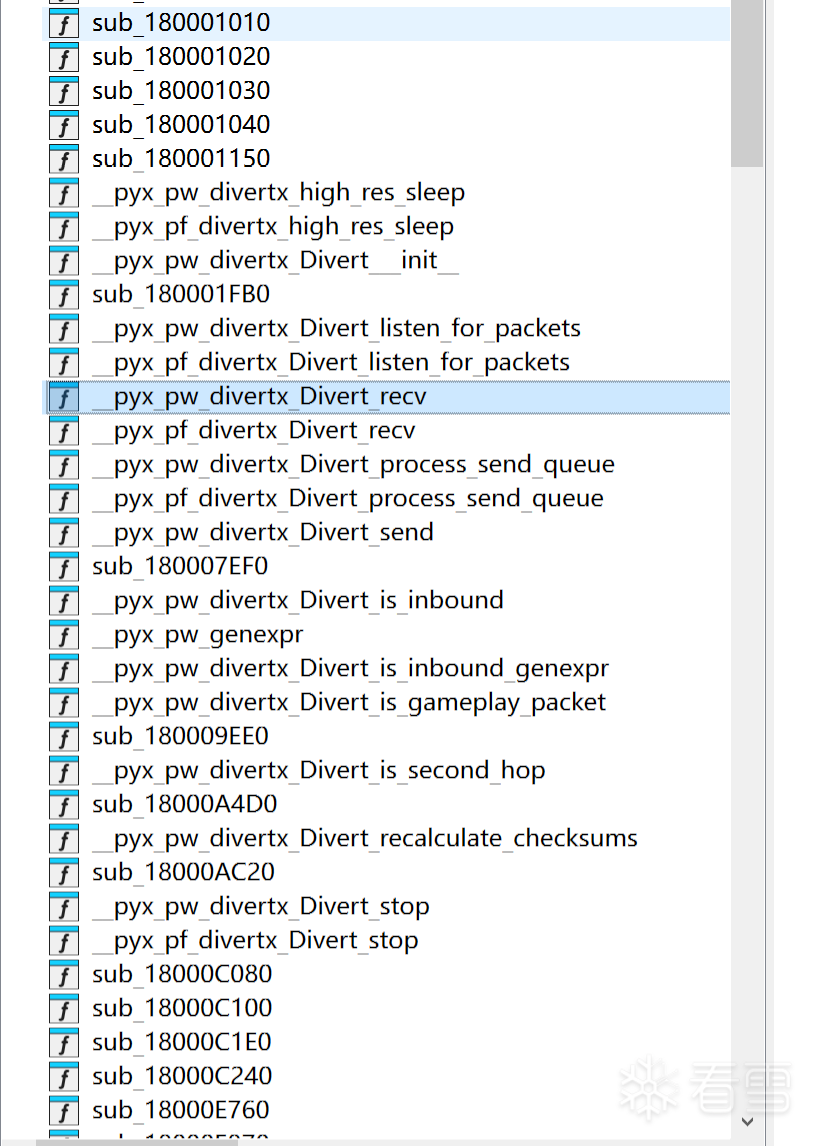
遇到名称混淆处理姿势
这是笔者遇到的挑战之一,很多时候,一些作者会在编译的时候进行名称混淆防止你分析。
如图:
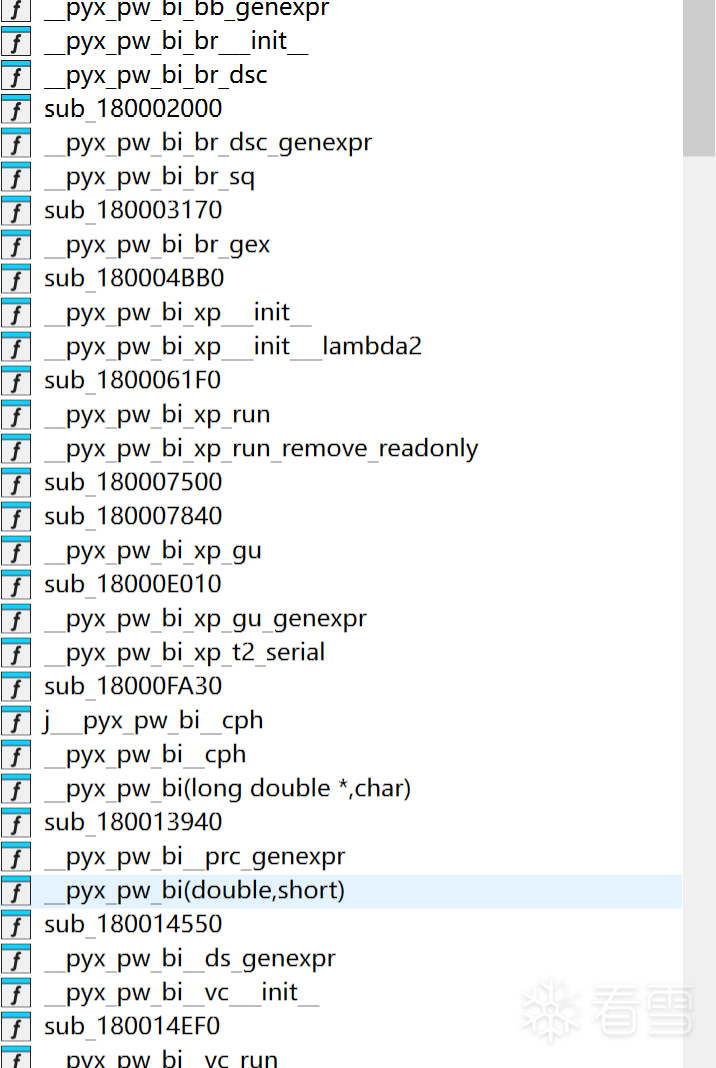
这种直接硬干不是好事,这里我建议使用 frida-python-bridge对关键函数进行hook。hook的主要针对这几个函数:
1 2 3 4 5 | "PyObject_Call","PyObject_CallObject","PyObject_CallNoArgs","PyObject_CallOneArg","_PyObject_Call" |
给个脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 | var PYD_NAME = "your_module.cp311-win_amd64.pyd"; // 改成你的pyd名字var PYTHON_DLL = "python311.dll"; // 改成对应的python版本var pyd = null;var python = null;function waitForModules() { return new Promise(function(resolve) { var check = setInterval(function() { pyd = Process.findModuleByName(PYD_NAME); python = Process.findModuleByName(PYTHON_DLL); if (pyd && python) { clearInterval(check); resolve(); } }, 100); });}function setupHooks() { console.log("[+] pyd base: " + pyd.base); console.log("[+] python base: " + python.base); var PyObject_Repr = new NativeFunction( python.getExportByName("PyObject_Repr"), 'pointer', ['pointer'] ); var PyUnicode_AsUTF8 = new NativeFunction( python.getExportByName("PyUnicode_AsUTF8"), 'pointer', ['pointer'] ); var PyObject_GetAttrString = new NativeFunction( python.getExportByName("PyObject_GetAttrString"), 'pointer', ['pointer', 'pointer'] ); var PyErr_Clear = new NativeFunction( python.getExportByName("PyErr_Clear"), 'void', [] ); var Py_True = python.getExportByName("_Py_TrueStruct"); var Py_False = python.getExportByName("_Py_FalseStruct"); var Py_None = python.getExportByName("_Py_NoneStruct"); function reprObj(obj) { if (obj.isNull()) return "NULL"; if (obj.equals(Py_True)) return "True"; if (obj.equals(Py_False)) return "False"; if (obj.equals(Py_None)) return "None"; try { var repr = PyObject_Repr(obj); if (!repr.isNull()) { var str = PyUnicode_AsUTF8(repr); if (!str.isNull()) { var s = str.readUtf8String(); if (s.length > 200) s = s.substring(0, 200) + "..."; return s; } } } catch(e) {} return "<?>"; } function getAttr(obj, name) { if (obj.isNull()) return null; try { var namePtr = Memory.allocUtf8String(name); var attr = PyObject_GetAttrString(obj, namePtr); if (!attr.isNull()) { var str = PyUnicode_AsUTF8(attr); if (!str.isNull()) { return str.readUtf8String(); } } PyErr_Clear(); } catch(e) {} return null; } function getCallableName(callable) { if (callable.isNull()) return "?"; var module = getAttr(callable, "__module__"); var qualname = getAttr(callable, "__qualname__"); var name = getAttr(callable, "__name__"); var result = ""; if (module) result = module + "."; if (qualname) { result += qualname; } else if (name) { result += name; } else { result += "?"; } return result; } function isFromPyd(addr) { return addr.compare(pyd.base) >= 0 && addr.compare(pyd.base.add(pyd.size)) < 0; } var seq = 0; var callFuncs = [ "PyObject_Call", "PyObject_CallObject", "PyObject_CallNoArgs", "PyObject_CallOneArg", "_PyObject_Call" ]; callFuncs.forEach(function(funcName) { try { var addr = python.getExportByName(funcName); if (addr) { Interceptor.attach(addr, { onEnter: function(args) { if (!isFromPyd(this.returnAddress)) return; this.active = true; this.callable = args[0]; this.funcName = getCallableName(args[0]); this.offset = this.returnAddress.sub(pyd.base).toInt32(); if (funcName === "PyObject_CallOneArg") { this.arg1 = reprObj(args[1]); } }, onLeave: function(retval) { if (!this.active) return; seq++; var result = reprObj(retval); var line = "[" + seq + "] " + this.funcName; if (this.arg1) { line += "(" + this.arg1 + ")"; } else { line += "()"; } line += " -> " + result; line += " [+" + this.offset.toString(16) + "]"; console.log(line); } }); console.log("[+] Hooked " + funcName); } } catch(e) { console.log("[-] Failed to hook " + funcName + ": " + e); } }); // Hook PyObject_Vectorcall (Python 3.9+) try { var vectorcall = python.getExportByName("PyObject_Vectorcall"); if (vectorcall) { Interceptor.attach(vectorcall, { onEnter: function(args) { if (!isFromPyd(this.returnAddress)) return; this.active = true; this.funcName = getCallableName(args[0]); this.offset = this.returnAddress.sub(pyd.base).toInt32(); }, onLeave: function(retval) { if (!this.active) return; seq++; var result = reprObj(retval); console.log("[" + seq + "] " + this.funcName + "() -> " + result + " [+" + this.offset.toString(16) + "]"); } }); console.log("[+] Hooked PyObject_Vectorcall"); } } catch(e) {} // Hook _PyObject_FastCall try { var fastcall = python.getExportByName("_PyObject_FastCall"); if (fastcall) { Interceptor.attach(fastcall, { onEnter: function(args) { if (!isFromPyd(this.returnAddress)) return; this.active = true; this.funcName = getCallableName(args[0]); this.offset = this.returnAddress.sub(pyd.base).toInt32(); }, onLeave: function(retval) { if (!this.active) return; seq++; var result = reprObj(retval); console.log("[" + seq + "] " + this.funcName + "() -> " + result + " [+" + this.offset.toString(16) + "]"); } }); console.log("[+] Hooked _PyObject_FastCall"); } } catch(e) {} console.log("\n[+] Trace started. Waiting for calls from " + PYD_NAME + "...\n");}waitForModules().then(setupHooks); |
我们可以hook之后就可以打印一下参数和返回值就大概知道这个函数在干什么,frida是天然支持这些python类型的。这样一跑函数干什么无处遁形,还可以针对几个你觉得高度怀疑的函数进行小范围trace,范围太大容易崩掉。这里就不贴代码了,原理搞明白了就好弄。如果要处理函数内的调用则需要自己sig一下识别一下这些内部的快速调用。
怎么处理编译后庞大的Pyd函数?
其实这个把它当做一种特殊的混淆去对待
函数庞大的原因是因为为了兼容解释器特性还需要像c一样快,里面就有大量的异常和内存管理代码,gl锁等等等,真正有效代码极小。
分析他无非就是去掉这些多余的垃圾代码,我们只需要真正的python函数的调用。
所以就有两种方法:
传统手法
由于python转换成c是有一套转规则的以及对应的匹配模块这个在cython中是有的,可以针对进行模式匹配。(这里不展示这种了留点底子吧hhh),贴一个对于模版转换的源码位置吧有兴趣自己慢慢写可以。模板文件 大小 作用 ObjectHandling.c 124KB 对象调用、属性访问( __Pyx_PyObject_Call等)ModuleSetupCode.c 123KB 模块初始化代码 Exceptions.c 36KB 异常处理( __Pyx_AddTraceback)FunctionArguments.c 33KB 参数解析( __Pyx_ArgTypeTest等)CythonFunction.c 67KB Cython 函数对象 TypeConversion.c 58KB 类型转换 Coroutine.c 87KB 协程/async 支持 ExtensionTypes.c 35KB 扩展类型(cdef class) 捷进
实际上就是要识别垃圾代码并且删除,而且没有我们传统混淆那些,虚假控制流这些东西,只有一些“垃圾代码“。
可以写一个md脚本调用ai接口切块识别到一些垃圾函数给他删掉优化掉(目前笔者使用这个已经还原出一些超大函数)。
流程就是函数拷贝下来(可以使用mcp工具)->让ai进行切片识别这些多余的代码删除掉,写入文件funxxx.c
大概提示词如下:(这个提示词很重要,如果直接对话肯定没有任何结果,建议还是往mcp或者代码驱动ai这方面靠)
1 2 3 4 5 6 7 8 | ### 任务介绍你是一个去cython垃圾代码机器人,你需要做的事情,识别cython独有的函数并且删除掉,保留原生python的调用函数### 工作流程读取xxx文件中的函数,创建一个工作目录,识别到一个分支块则启动优化器,优化后的结果放入xxx.c文件中,并且需要记录当前工程路径和总结防止丢失上下文### 注意不要修改原有分支,只需要删除多余代码即可。### 当前要做的事情根据我的任务报告,拆分任务创建任务流程并且记录,每次完成一个写入日志文档中 |
总结
总体来说pyd逆向主要就是量大,所以传统方法逆向的话速度太慢,最好还是利用他的机制进行定位。下次我在填完变量成员的坑。
更多【软件逆向-Pyd原理以及逆向实战 (一)函数】相关视频教程:www.yxfzedu.com
相关文章推荐
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——UAF - PwnHarmonyOSWeb安全软件逆向
- Pwn-glibc高版本堆题攻击之safe unlink - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-CVE-2020-1054提权漏洞学习笔记 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-初探内核漏洞:HEVD学习笔记——BufferOverflowNonPagedPool - PwnHarmonyOSWeb安全软件逆向
- CTF对抗-2022DASCTF Apr X FATE 防疫挑战赛-Reverse-奇怪的交易 - PwnHarmonyOSWeb安全软件逆向
- 编程技术-一个规避安装包在当前目录下被DLL劫持的想法 - PwnHarmonyOSWeb安全软件逆向
- CTF对抗-sql注入学习笔记 - PwnHarmonyOSWeb安全软件逆向
- Pwn-DamCTF and Midnight Sun CTF Qualifiers pwn部分wp - PwnHarmonyOSWeb安全软件逆向
- 软件逆向-OLLVM-deflat 脚本学习 - PwnHarmonyOSWeb安全软件逆向
- 软件逆向-3CX供应链攻击样本分析 - PwnHarmonyOSWeb安全软件逆向
- Android安全-某艺TV版 apk 破解去广告及源码分析 - PwnHarmonyOSWeb安全软件逆向
- Pwn-Hack-A-Sat 4 Qualifiers pwn部分wp - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞- AFL 源代码速通笔记 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-Netatalk CVE-2018-1160 复现及漏洞利用思路 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-DynamoRIO源码分析(一)--劫持进程 - PwnHarmonyOSWeb安全软件逆向
- 二进制漏洞-通用shellcode开发原理与实践 - PwnHarmonyOSWeb安全软件逆向
- Android安全-frida-server运行报错问题的解决 - PwnHarmonyOSWeb安全软件逆向
- Android安全-记一次中联X科的试岗实战项目 - PwnHarmonyOSWeb安全软件逆向
- Android安全-对SM-P200平板的root记录 - PwnHarmonyOSWeb安全软件逆向
- Android安全-某艺TV版 apk 破解去广告及源码分析 - PwnHarmonyOSWeb安全软件逆向
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- CTF对抗-2022DASCTF Apr X FATE 防疫挑战赛-Reverse-奇怪的交易
- 编程技术-一个规避安装包在当前目录下被DLL劫持的想法
- CTF对抗-sql注入学习笔记
- Pwn-DamCTF and Midnight Sun CTF Qualifiers pwn部分wp
- 软件逆向-OLLVM-deflat 脚本学习
- 软件逆向-3CX供应链攻击样本分析
- Android安全-某艺TV版 apk 破解去广告及源码分析
- Pwn-Hack-A-Sat 4 Qualifiers pwn部分wp
- 二进制漏洞- AFL 源代码速通笔记
- 二进制漏洞-Netatalk CVE-2018-1160 复现及漏洞利用思路