这两年,AI Agent 正在快速从“对话工具”变成“执行工具”。
它不再只是回答问题,而是开始接入本地文件、调用脚本、读取配置、连接 MCP 服务、使用 Skills/Plugins,甚至直接与外部 API 和业务系统交互。能力越来越强,意味着边界越来越大;边界越来越大,也意味着攻击面越来越复杂。
很多团队已经在本地或服务器上部署了各类 Agent:openclaw、claude、nanobot、opencode……平时大家更关注的是“能不能跑起来”“模型好不好用”“接了多少工具”,但真正容易被忽略的是:这些 Agent 究竟暴露了多少攻击面?
这次,我们就以 OpenClaw 及其同类 Agent 生态为例,做一次“像剥小龙虾一样”的攻击面梳理:把壳一层层掰开,看清它到底有哪些入口、有哪些连接、哪些配置、哪些高风险点,以及这些风险为什么会在 AI Agent 场景下被放大。
而支撑这次梳理的,是一款纯 Bash 实现的 AI Agent 安全审计工具。它可以发现本地 Agent 程序、提取 MCP 配置、扫描 Skills/Plugins、识别 API Key 与 Base URL、生成 SBOM、匹配内置漏洞库,并输出 HTML、CSV 和知识图谱等多种审计结果。工具也支持扫描本机与远程主机,并可导出完整报告。
为什么 AI Agent 值得单独做一次攻击面梳理?
传统主机安全,大家熟悉的是端口、服务、进程、账号、计划任务、依赖组件。
但 AI Agent 不太一样。它的“危险”,很多时候不是来自一个单点漏洞,而是来自能力的叠加:

图1
这些能力单独看都不新鲜,但一旦被放进同一个执行体里,问题就变了:
AI Agent 本身,正在成为一个新的“安全聚合体”。它既像客户端,又像自动化平台;既像脚本调度器,又像半开放的集成网关。你很难再用“这只是一个聊天工具”来理解它。
所以,对 AI Agent 做安全审计,不能只看一个二进制文件,也不能只看一个配置目录,而要从下面几个维度整体看,这才是 AI Agent 真正的攻击面分析方式。

图2
为什么说 OpenClaw 这类 Agent,像一只“小龙虾”?
OpenClaw 这类 Agent 很像小龙虾。
看起来主体不大,但真拆开以后,钳子、壳、腿、触须、内脏一层一层,结构非常复杂。你以为在看一个 Agent,实际上面对的是一整个“能力系统”。
如果把这个类比拉到安全视角,大概是如下图,你不把它拆开,就永远不知道哪一口最危险。

图3
这次实际扫到了什么?
从一台安装AI Agent 审计报告来看,这台主机上一共发现了14个 AI Agent、60个 MCP 服务器、189个 Skills/Plugins、10组 API 配置,并生成了 383个组件的 SBOM。报告同时识别出了9个严重漏洞和13个高危漏洞。
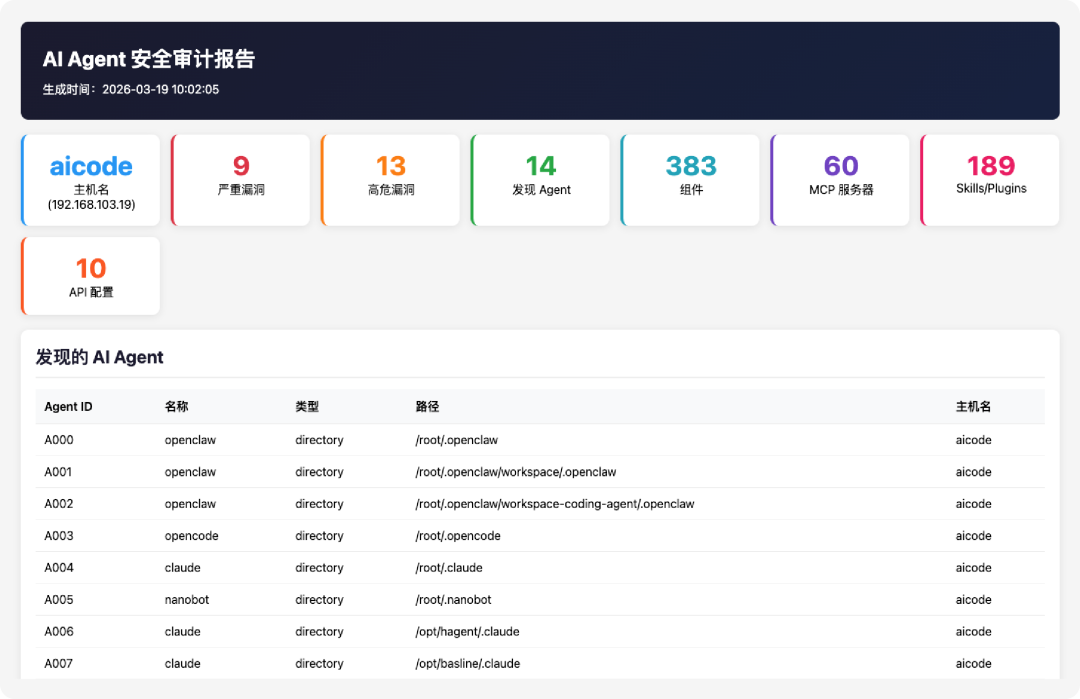
其中,Agent 类型并不单一。除了 OpenClaw,还发现了 opencode、claude、nanobot 等多个目录形态的 Agent 实例,说明现实环境里,AI Agent 往往不是“单产品部署”,而是多框架并存、多个工作目录并行、多个项目副本混杂的状态。
这件事很关键。
因为在很多安全人员的想象里,AI Agent 还是一个“点状资产”;但从这次扫描结果看,它更像是一个“面状资产”——你以为只装了一个 OpenClaw,实际上相关目录、工作区副本、测试实例、历史项目目录可能已经铺开了一整片。
这就意味着,攻击面不是一个配置文件,而是一整个生态面。
AI Agent 的攻击面,至少要看这五层
1.Agent 发现层:你到底装了多少个“会行动的AI”?
第一层永远不是漏洞,而是资产可见性。如果连主机上有哪些 Agent 都不知道,就谈不上治理。
这次扫描发现的 Agent 包括多个 OpenClaw 目录,以及 opencode、claude、nanobot 等不同类型实例,分布在 /root/opt/home/aicode 等不同路径下。
这说明一个典型问题:
Agent 的部署路径高度分散。有些在用户主目录,有些在项目目录,有些在工具目录,还有些是在 workspace 里自动生成的副本。对蓝队来说,这会直接带来三类风险:

图4
所以,AI Agent 安全治理的第一步,不是“先修漏洞”,而是先把这批东西找出来。
2.MCP 连接层:Agent 接出去的“手”和“脚”有多长?
如果说模型是大脑,那 MCP 就是手脚。
这次报告里一共发现 60 个 MCP 服务器配置,既有 remote 类型,也有 stdio 类型,来源覆盖 .mcp.json、settings.json、mcporter.json 等多个配置位置。
从名字上看,里面已经不只是通用型服务,还包含了不少偏安全能力的 MCP,例如资产探测、目录扫描、弱口令、WHOIS、Web 扫描等相关服务。
这意味着什么?意味着 Agent 不只是“会想”,它已经开始“会摸、会查、会连、会扫”。
一旦一个 Agent 能接入这些 MCP,它的能力边界就不再由模型本身决定,而是由外部连接能力总和决定。此时真正的风险点包括:

图5
很多人低估 MCP,是因为它看起来像“插件配置”;但从攻击面上看,它更像是Agent 的外接执行总线。
3.Skills/Plugins 层:扩展能力越多,边界越难控
报告中共发现 189个 Skills/Plugins,其中 OpenClaw 相关技能数量尤其多。
这类扩展的价值当然很高,因为它们让 Agent 不再只是文本生成器,而是变成一个能完成具体任务的系统。
但从安全角度看,Skills/Plugins 有三个如下典型问题。而一旦扩展能力失控,Agent 的风险就会从“模型回答不准”升级成“执行行为不可控”。

图6
说得更直白一点:
不会动的 AI,顶多是嘴把式;会调插件的 AI,才开始真正碰到安全边界。
4.配置与密钥层:真正的高价值目标,通常都藏在这里
这次工具新增了一个非常实用的能力:扫描各 Agent 的 API Key、Base URL 和 Model 配置。
报告中发现了 10组 API 配置,涉及不同 Agent 的密钥、基础地址和模型参数。配置已做脱敏展示,但从审计视角已经足够说明问题:这些关键参数确实广泛散落在本地配置文件中。
这一层是 AI Agent 最容易被低估、却往往价值最高的部分。
因为很多团队会把安全注意力放在“代码有没有漏洞”,却忽略了另一个现实:
对攻击者来说,拿到 Key、Base URL、模型配置,有时比拿到一个漏洞更直接。它可能带来的影响包括:

图7
而且 AI Agent 的配置文件往往比传统应用更松散。有些在 settings.json,有些在 config.json,有些来自环境变量,有些通过插件再转一层。对于运维和安全团队来说,这会导致两个现实难题:不好审,也不好控。
5.组件与漏洞层:AI Agent 的底座,其实还是软件供应链
很多人一谈 AI 安全,就只想到 prompt injection、越权调用、模型幻觉。
这些当然重要,但别忘了:AI Agent 归根到底还是一个软件系统。
这次扫描生成了 383个组件的 SBOM,并匹配出了多项高危和严重漏洞。
从报告里能看到,一些高风险点集中在基础组件和常用依赖上,比如 Git、PyYAML、Pillow、Jinja2、pip、urllib3 等;其中部分漏洞带有明显的 RCE 风险标记。
这说明一个很现实的问题:AI Agent 的风险,并不只来自“AI”。
它同样会继承传统软件世界里的老问题:

图8
尤其是当 Agent 已经具备文件处理、脚本调用、仓库拉取、模板渲染、网络访问等能力时,底层组件中的 RCE、路径遍历、沙盒逃逸、XXE 这类问题,危险程度会明显上升。
所以,AI Agent 安全绝不能只做“模型侧评估”,还必须做依赖侧审计和供应链侧治理。
为什么“纯 Bash 实现”的审计工具,有现实意义?
很多人一听“安全审计工具”,会下意识认为一定要很重、很复杂、很平台化。
但这次这款工具给我的一个直观感受是:它很接地气。它采用纯 Bash 实现,目标并不是做一个花哨的AI 平台,而是实打实地解决“我到底怎么快速把本地和远程主机上的 AI Agent 资产摸清楚”这个问题。
从使用手册看,它支持两种典型场景:
扫描本机:直接启动本地扫描任务;
远程主机扫描:通过 SSH 下发扫描任务,必要时还能结合 sudo 获取更完整的配置视图。
同时,扫描完成后可以导出报告,生成 HTML 审计结果,并支持后续删除、归档,以及上传到平台进行集中管理。这种设计思路很适合当前 AI Agent 的真实落地环境:

图9
这时候,最有价值的不一定是一个“最先进”的安全引擎,而是一个能快速发现、快速导出、快速形成治理闭环的工具。
从这次 OpenClaw 攻击面梳理,可以得到哪些结论?
我觉得至少有四个结论。
结论一:AI Agent 已经不是单点工具,
而是复合型资产
它不再只是一个 CLI 程序,也不只是一个模型配置目录。
它同时包含本地配置、外部连接、扩展能力、依赖组件、执行脚本和敏感凭据。
所以,资产管理方式必须升级。
结论二:MCP + Skills + API 配置,
正在成为 Agent 安全的核心三件套
真正决定 Agent 风险上限的,往往不是模型名字,而是:
接了什么 MCP;
装了什么 Skills;
配了什么 Key 和 URL。
这三者一旦失控,Agent 就会从“好用工具”变成“高风险自动化入口”。
结论三:AI 安全和传统漏洞治理,
必须合在一起看
如果只看模型风险,不看 SBOM 和 CVE,会漏掉真正可利用的基础问题;如果只看 CVE,不看 Agent 的连接和执行能力,又会低估漏洞被放大的场景。
AI Agent 安全,天然就是AI 风险 + 软件供应链风险 + 自动化执行风险的叠加。
结论四:先做攻击面梳理,再谈加固,
才是正确顺序
许多团队倾向于优先构建“AI 安全治理平台”,但在基础的资产底数——如 Agent、MCP 及 Key 的分布——尚未完全厘清之前,治理工作恐怕难以承载实际的安全价值。
真正有效的路径应该是:
先盘点,再识别,再分级,再修复,最后持续监控。攻击面梳理不是最后一步,而是第一步。
写在最后:AI Agent 安全,别等“出事”才看见
今天的 AI Agent,正在越来越像“一个能自己干活的数字员工”。它会读、会写、会调工具、会联网、会记忆、会执行。而一个系统一旦拥有这些能力,它就不再只是“AI 应用”,而是新的安全边界。
这也是为什么,用“小龙虾攻击面梳理”来形容 OpenClaw 这类系统。
因为你不把它拆开看,就会以为它只是一只虾;但真拆开之后你才发现,里面藏着复杂的结构、密集的连接和众多的入口。
对企业来说,AI Agent 安全最怕的不是漏洞多,而是不知道哪里有、连到了哪、能干什么、出了问题会影响什么。而一次扎实的攻击面梳理,恰恰就是把这些问题从“模糊感觉”变成“清晰结果”的过程。
AI Agent 正在加速落地。安全,也需从“抽象讨论”走到“具体审计”了。
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
文中提到的审计脚本下载路径:becK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6H3L8$3y4Z5N6h3u0Q4x3X3c8Z5N6h3q4#2L8W2)9J5c8X3q4A6j5$3S2W2j5$3D9`.
MacOS可执行脚本 ai_agent_security_audit.sh
Linux可执行脚本 ai_agent_security_audit_linux.sh
带界面的应用程序下载
ceeK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6H3L8$3y4Z5N6h3u0Q4x3X3c8Z5N6h3q4#2L8W2)9J5c8X3q4A6j5$3S2W2j5$3E0#2K9g2)9J5c8Y4u0W2L8r3g2S2M7$3g2K6i4K6u0r3k6r3!0%4L8X3I4G2j5h3c8Q4x3V1k6$3x3g2)9J5k6e0m8Q4x3X3f1H3i4K6u0r3b7f1W2Q4x3X3g2Q4x3X3b7I4i4K6u0W2x3q4)9J5k6e0m8Q4x3X3c8S2L8h3b7$3y4q4)9J5k6s2N6A6L8W2)9J5k6i4u0S2M7R3`.`.
23fK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6H3L8$3y4Z5N6h3u0Q4x3X3c8Z5N6h3q4#2L8W2)9J5c8X3q4A6j5$3S2W2j5$3E0#2K9g2)9J5c8Y4u0W2L8r3g2S2M7$3g2K6i4K6u0r3k6r3!0%4L8X3I4G2j5h3c8Q4x3V1k6$3x3g2)9J5k6e0m8Q4x3X3f1H3i4K6u0r3b7f1W2Q4x3X3g2Q4x3X3b7I4i4K6u0W2x3q4)9J5k6e0m8Q4x3X3c8S2M7X3@1$3y4q4)9J5k6r3#2S2j5#2)9J5k6i4A6A6M7l9`.`.
使用说明参考4adK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6H3L8$3y4Z5N6h3u0Q4x3X3c8Z5N6h3q4#2L8W2)9J5c8X3q4A6j5$3S2W2j5$3E0#2K9b7`.`.
最后:实验性项目,使用有BUG还请谅解。