编程技术-【语音合成】中文-多情感领域-16k-多发音人
推荐 原创模型介绍
框架描述
拼接法和参数法是两种Text-To-Speech(TTS)技术路线。近年来参数TTS系统获得了广泛的应用,故此处仅涉及参数法。
参数TTS系统可分为两大模块:前端和后端。 前端包含文本正则、分词、多音字预测、文本转音素和韵律预测等模块,它的功能是把输入文本进行解析,获得音素、音调、停顿和位置等语言学特征。 后端包含时长模型、声学模型和声码器,它的功能是将语言学特征转换为语音。其中,时长模型的功能是给定语言学特征,获得每一个建模单元(例如:音素)的时长信息;声学模型则基于语言学特征和时长信息预测声学特征;声码器则将声学特征转换为对应的语音波形。
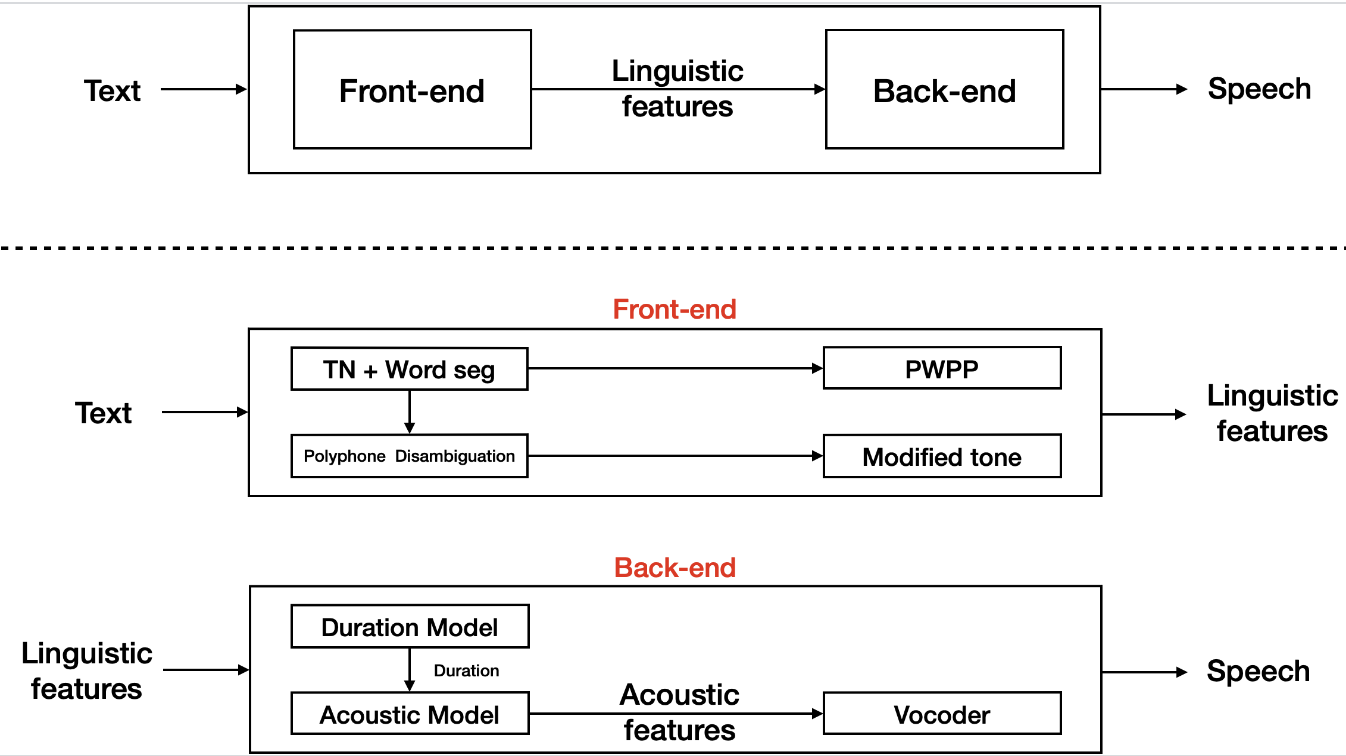
前端模块我们采用模型结合规则的方式灵活处理各种场景下的文本,后端模块则采用SAM-BERT + HIFIGAN提供高表现力的流式合成效果。
声学模型SAM-BERT
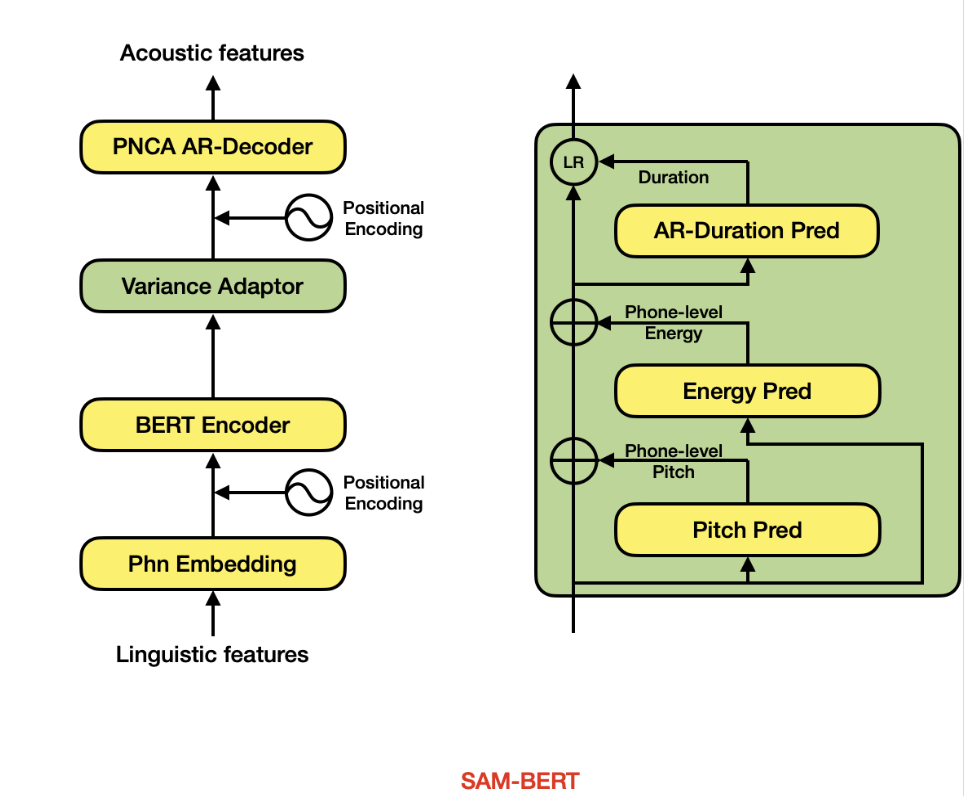
后端模块中声学模型采用自研的SAM-BERT,将时长模型和声学模型联合进行建模。
- Backbone采用Self-Attention-Mechanism(SAM),提升模型建模能力。
- Encoder部分采用BERT进行初始化,引入更多文本信息,提升合成韵律。
- Variance Adaptor对音素级别的韵律(基频、能量、时长)轮廓进行粗粒度的预测,再通过decoder进行帧级别细粒度的建模;并在时长预测时考虑到其与基频、能量的关联信息,结合自回归结构,进一步提升韵律自然度.
- Decoder部分采用PNCA AR-Decoder[@li2020robutrans],自然支持流式合成。
声码器模型
后端模块中声码器采用HIFI-GAN, 基于GAN的方式利用判别器(Discriminator)来指导声码器(即生成器Generator)的训练,相较于经典的自回归式逐样本点CE训练, 训练方式更加自然,在生成效率和效果上具有明显的优势。
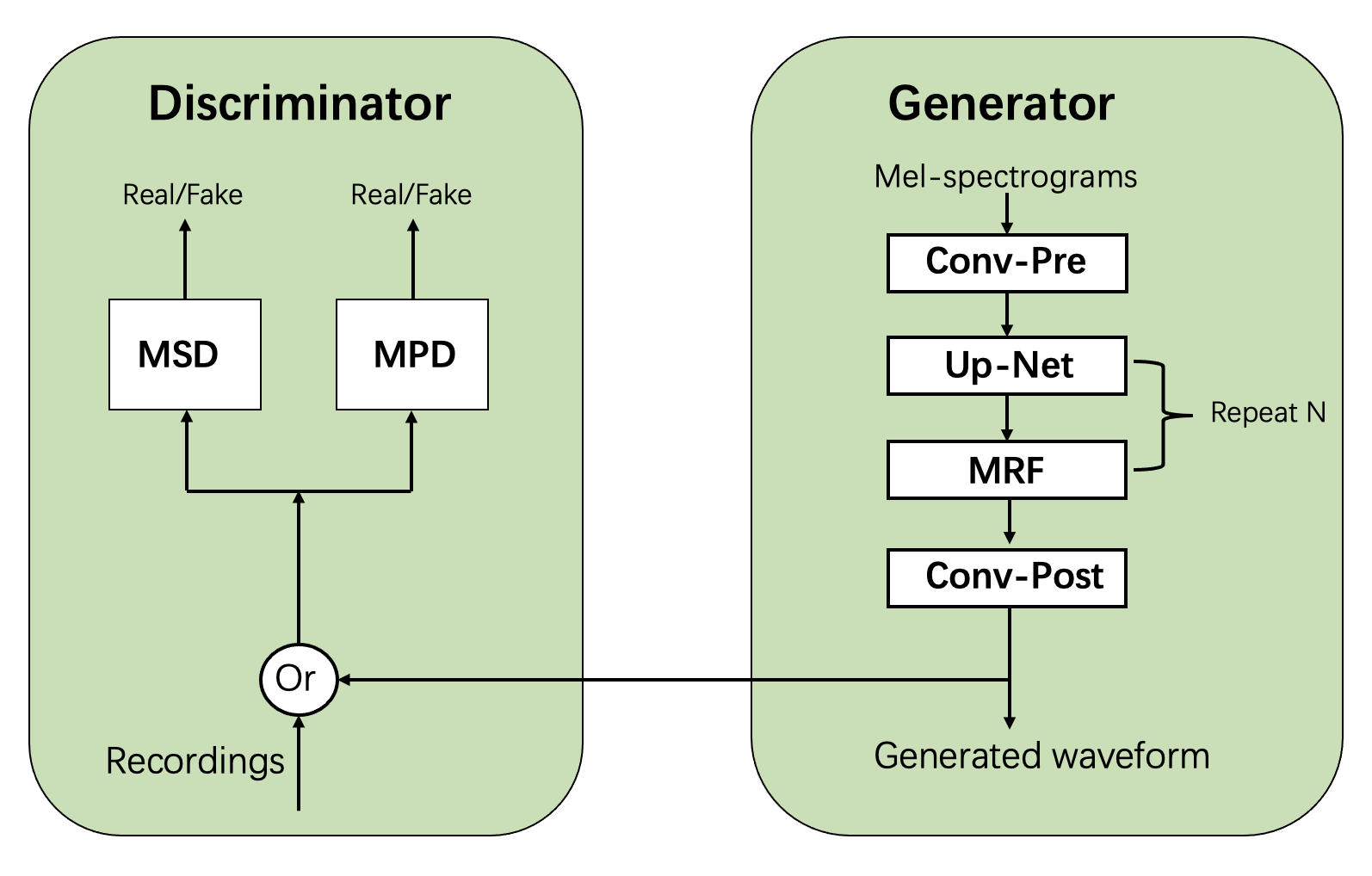
在HIFI-GAN开源工作[1]的基础上,我们针对16k, 48k采样率下的模型结构进行了调优设计,并提供了基于因果卷积的低时延流式生成和chunk流式生成机制,可与声学模型配合支持CPU、GPU等硬件条件下的实时流式合成。
部署
- 下载模型:
git lfs clone https://www.modelscope.cn/iic/speech_sambert-hifigan_tts_zh-cn_16k.git modelscope库安装:- 安装
modelscope基础功能:pip install modelscope -i https://mirrors.cloud.aliyuncs.com/pypi/simple - 安装
modelscope cv功能:pip install "modelscope[cv]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html - 安装
modelscope audio功能:pip install "modelscope[audio]" -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
- 安装
使用方式和范围
- 使用方式: 直接输入文本进行推理
- 使用范围: 适用于中文或中英文混合的语音合成场景,输入文本使用
utf-8编码,整体长度建议不超过30字 - 目标场景: 各种语音合成任务,比如配音,虚拟主播,数字人等
代码范例
from modelscope.outputs import OutputKeys
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
def text_to_speech(text, speech_file_path, voice_type):
model_id = 'damo/speech_sambert-hifigan_tts_zh-cn_16k'
sambert_hifigan_tts = pipeline(task=Tasks.text_to_speech, model=model_id)
output = sambert_hifigan_tts(input=text, voice=voice_type)
wav = output[OutputKeys.OUTPUT_WAV]
with open(speech_file_path, 'wb') as f:
f.write(wav)
if __name__ == "__main__":
text_to_speech('待合成文本', 'output.wav', 'zhitian_emo')
更多【编程技术-【语音合成】中文-多情感领域-16k-多发音人】相关视频教程:www.yxfzedu.com
相关文章推荐
- 编程技术-【ROS】RViz2源码分析(一):介绍 - 其他
- 计算机视觉-Pytorch实战教程(五)-计算机视觉基础 - 其他
- 编程技术-【Java 进阶篇】JQuery 案例:qq表情选择,表达情感的小黄脸 - 其他
- java-Jenkins入门——安装docker版的Jenkins & 配置mvn,jdk等 & 使用案例初步 & 遇到的问题及解决 - 其他
- 学习-科研学习|科研软件——有序多分类Logistic回归的SPSS教程! - 其他
- 编程技术-如何在 Linux 上部署 RabbitMQ - 其他
- 编程技术-WPF路由事件 - 其他
- 算法-通信信道:无线信道中衰落的类型和分类 - 其他
- 编程技术-复杂度分析 - 其他
- 编程技术-ReentrantLock通过Condition实现锁对象的监视器功能 - 其他
- 编程技术-如何在3DMax中使用超过16个材质ID通道? - 其他
- 安全-OpenAtom OpenHarmony三方库创建发布及安全隐私检测 - 其他
- elasticsearch-Elasticsearch docker-compose 使用 Logstash 从 JSON 文件中预加载数据 - 其他
- 编程技术-C++模板 - 其他
- python-7 切片及应用 - 其他
- 人工智能-写在 Chappyz 即将上所之前:基于 AI 技术对 Web3 营销的重新定义 - 其他
- 爬虫-R语言爬虫程序自动爬取图片并下载 - 其他
- c#-C# Onnx LSTR 基于Transformer的端到端实时车道线检测 - 其他
- 智能合约-编译智能合约以及前端交互工具库(Web3项目一实战之三) - 其他
- 计算机网络-计算机网络必须知道的点 - 其他
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- 科技-【亚马逊云科技产品测评】活动征文|亚马逊云科技AWS之EC2详细测评
- mysql-java八股文(mysql篇)
- 计算机视觉-计算机视觉与深度学习 | 基于视觉惯性紧耦合的SLAM后端优化算法
- c++-【C++】从入门到精通第三弹——友元函数与静态类成员
- spring boot-java 企业工程管理系统软件源码+Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis
- 科技-企业财务数字化转型的机遇有哪些?_光点科技
- 科技-云计算的大模型之争,亚马逊云科技落后了?
- c语言-C语言 变量
- 物联网-USB PD v1.0快速充电通信原理
- 网络-网络安全与TikTok:年轻一代的数字素养