Android安全-vmp入门(一):android dex vmp还原和安全性论述
推荐 原创【Android安全-vmp入门(一):android dex vmp还原和安全性论述】此文章归类为:Android安全。
前言
这是第一篇vmp系列,下一篇估计要很久很久以后。
https://bbs.kanxue.com/thread-270799.htm#msg_header_h1_6
看了一下,目前市面上关于dex vmp还原就我兄弟写的这一个,我不得不佩服他巨强的二级制分析能力。关于dex vmp 他的大部分都写了,但是,他搞的实在是太复杂了,他的分析基本都是基于静态的数据流向分析,这种对于二进制vmp都有杀伤力的,只能说杀鸡焉用牛刀,而且他的牛刀还没发借给我,这是最气的。
另外一个360大佬在看雪峰会上发的关于dex vmp的ppt演讲,他这个我没看得很懂,技术有限。前面都是大佬,一看就会,一学就废。
vmp宝宝入门知识讲解
vmp目前基本可以说是逆向分析中代码混淆的巅峰,顶点,最高里程碑,dex vmp在我看来是比较简单一点的vmp了,所以我们从这里入门。
vmp设计理念
vmp是一种虚拟机保护壳,如果你第一次听过,估计直接蒙了,他其实就是一个虚拟的执行机器,就比如java虚拟机,他们的原理是一样的。java虚拟机可以叫vmp是保护的意思,所以叫vmp。这种虚拟机一般有两部分: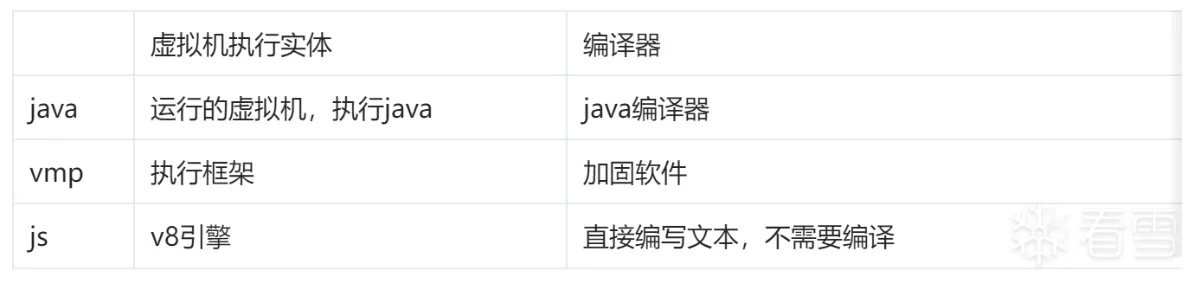
vmp执行实体运作原理
vmp虽然设计理念上跟别的虚拟机没什么差别,但是他很简陋,基本只有能转换虚拟机的bytecode然后进行运行的能力。写个伪代码示意一下
1 2 3 4 5 | while(1){ //一旦进入虚拟机就会开始读取字节码,除非遇到退出指令,否则一直执行下去 bytecode_ins = read(bytecode_buff); //不断的读取指令 exe(bytecode_ins) //运行指令} |
就是这样一直循环
vmp加固软件
在vmp执行实体中,可以看到有个bytecode_buff,虚拟机为什么能识别他,因为加固软件将源码,转变成虚拟机的bytecode,然后将虚拟机和bytecode一起打包到需要加固的软件中。
逆向目标
对于一个vmp,我们的目标只有一个,那就是还原,还原成c也好,汇编也好,java也好,反正就是去除vmp化。这就是最务实的目标,所以这篇博客的目的就是如何将dex vmp 还原成java代码。
程序分析
Java层函数入口
首先看入口函数,如果看过我上面提到过的dex vmp 你就该知道,这个pro.getxxx,其实就是调用的dex vmp函数的入口,而第一个参数,其实就是代表了当前这个函数,用这个数字来索引已经被虚拟化的代码来执行。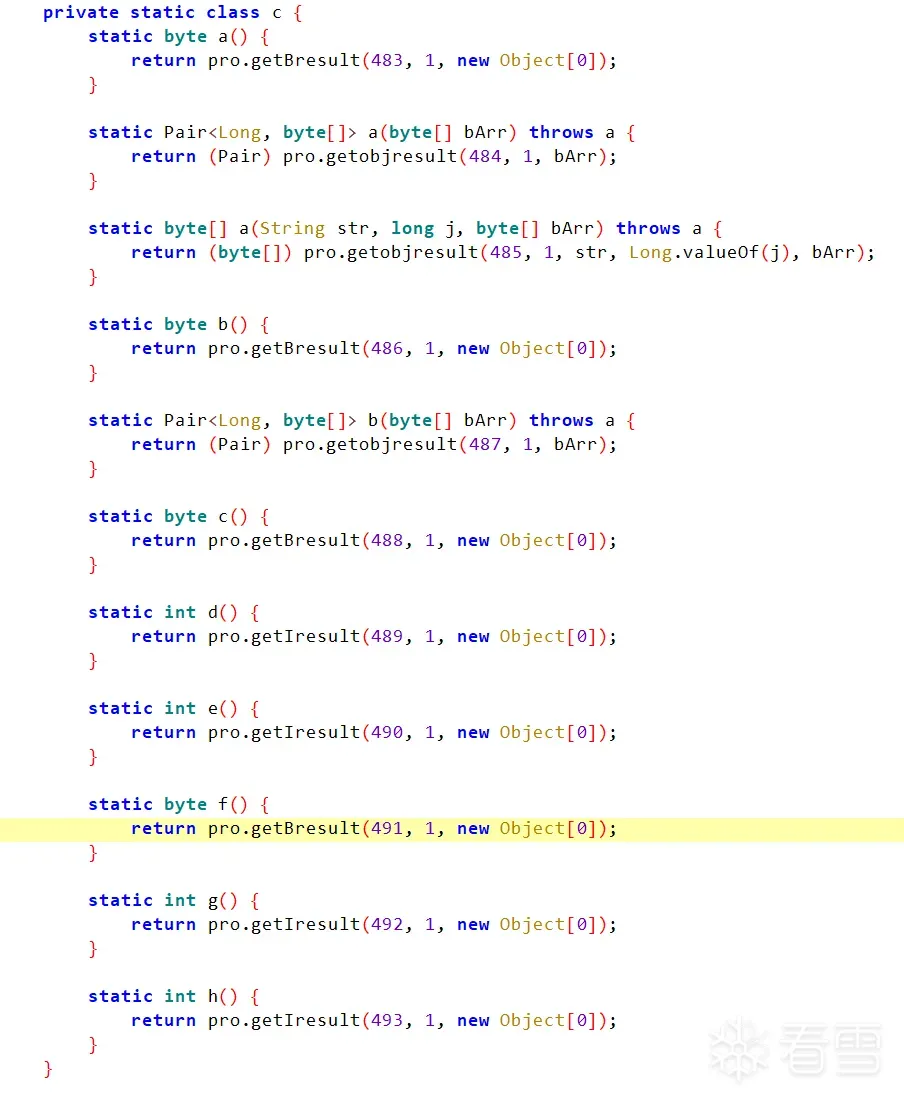
然后再看看这个函数的定义,这个如果你经验丰富,经常写java代码和别的代码的交互,你就会发现,这是一个java 和c的交互代码,写了这么多类型,就是可以从c 层返回任何一种类型的java对象,看不出来也没事。

寻找java方法的native 地址
这个本来不想写的,但是其实其实比较简单,有人多人去hook NativeRegister,很多加固去通过各种奇葩的手段绕过NativeRegister进行注册,但是其实没必要,java方法的native地址根本无法隐藏。分享一个frida脚本寻找native方法的地址。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | var offset = -1//这个函数是用来做偏移矫正的function get_android_api_jnioffset() { if(offset != -1){ return offset } var native_addr = Module.findExportByName("libandroid_runtime.so", "_Z32android_os_Process_getUidForNameP7_JNIEnvP8_jobjectP8_jstring") // console.log("native_addr:",native_addr) var className = "android.os.Process"; var classResult = Java.use(className).class; var methodArr = classResult.getDeclaredMethods(); for (var i = 0; i < methodArr.length; i++) { var methodName = methodArr[i].toString(); var flags = methodArr[i].getModifiers() if (flags & 256) { if(methodName.indexOf("getUidForName")!= -1){ var artmethod = methodArr[i].getArtMethod(); for (var i = 0; i < 30; i=i+1) { var jni_native_addr = Memory.readPointer(ptr(artmethod + i)) if(native_addr.equals(jni_native_addr)){ offset = i return i } } } } } return -1}遍历一个类的所有native 方法并打印地址function get_jni_native_method_addr(classResult) { var jnioffset = get_android_api_jnioffset() var methodArr = classResult.getDeclaredMethods(); for (var i = 0; i < methodArr.length; i++) { var methodName = methodArr[i].toString(); var flags = methodArr[i].getModifiers() if (flags & 256) { var artmethod = methodArr[i].getArtMethod(); var native_addr = Memory.readPointer(ptr(artmethod + jnioffset)) //找到本手机系统中artmethod的便宜地址,然后用20+偏移 var module var offset console.log("methodName->", methodName); try { module = Process.getModuleByAddress(native_addr) offset = native_addr - module.base console.log("Func.offset==", module.name, offset); } catch (err) { } console.log("Func.getArtMethod->native_addr:", native_addr); //打印出java方法jni函数调用的native函数地址 console.log("Func.flags->", flags); } }} |
getobjresult 函数native分析
这个函数是我们主要的分析,怎么寻找native函数,so动态下发分析不讲了,直接找native函数地址开始分析流程
初步调试分析
拿到这个包以后,已经找到要逆向的函数,所以直接用上面的frida 脚本找到函数的偏移,然后ida直接附加进程,在这个位置下断点,确实没问题,函数在这里断下来了,trace了一下,程序直接崩溃了,有反调试,无所谓,停掉所有其他的线程trace,这个getobjresult函数有时候能跑完,有时候跑不完。但是trace确实完成了,第一次trace 90w,第二次2700w行。trace代码的长度,流程都不一样。经过代码一段时间的汇编分析(比较简单),我发现出问题代码这个地方开始不一致。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | .text:000000000001AD18 FC 6F BA A9 STP X28, X27, [SP,#-0x10+var_50]!.text:000000000001AD1C FA 67 01 A9 STP X26, X25, [SP,#0x50+var_40].text:000000000001AD20 F8 5F 02 A9 STP X24, X23, [SP,#0x50+var_30].text:000000000001AD24 F6 57 03 A9 STP X22, X21, [SP,#0x50+var_20].text:000000000001AD28 F4 4F 04 A9 STP X20, X19, [SP,#0x50+var_10].text:000000000001AD2C FD 7B 05 A9 STP X29, X30, [SP,#0x50+var_s0].text:000000000001AD30 FD 43 01 91 ADD X29, SP, #0x50.text:000000000001AD34 FF 83 07 D1 SUB SP, SP, #0x1E0.text:000000000001AD38 48 D0 3B D5 MRS X8, #3, c13, c0, #2.text:000000000001AD3C E8 07 00 F9 STR X8, [SP,#8].text:000000000001AD40 08 15 40 F9 LDR X8, [X8,#0x28].text:000000000001AD44 F9 03 01 AA MOV X25, X1.text:000000000001AD48 FA 03 00 AA MOV X26, X0.text:000000000001AD4C A8 03 1A F8 STUR X8, [X29,#var_60].text:000000000001AD50 37 A0 40 A9 LDP X23, X8, [X1,#8].text:000000000001AD54 29 0C 40 F9 LDR X9, [X1,#0x18].text:000000000001AD58 E8 5B 00 F9 STR X8, [SP,#0xB0].text:000000000001AD5C 28 14 40 F9 LDR X8, [X1,#0x28].text:000000000001AD60 E9 0F 00 F9 STR X9, [SP,#0x18].text:000000000001AD64 E8 5F 00 F9 STR X8, [SP,#0xB8].text:000000000001AD68 28 00 40 F9 LDR X8, [X1].text:000000000001AD6C E8 57 00 F9 STR X8, [SP,#0xA8].text:000000000001AD70 28 8F 44 78 LDRH W8, [X25,#0x48]!.text:000000000001AD74 68 00 00 34 CBZ W8, loc_1AD80.text:000000000001AD74.text:000000000001AD78 E8 03 00 32 MOV W8, #1.text:000000000001AD7C 28 E0 01 39 STRB W8, [X1,#0x78].text:000000000001AD7C.text:000000000001AD80.text:000000000001AD80 loc_1AD80 ; CODE XREF: bl_x8+5C↑j.text:000000000001AD80 F4 02 40 79 LDRH W20, [X23].text:000000000001AD84 28 60 02 91 ADD X8, X1, #0x98.text:000000000001AD88 F6 02 00 B0 ADRP X22, #data_rel@PAGE.text:000000000001AD8C E8 53 00 F9 STR X8, [SP,#0xA0].text:000000000001AD90 88 1E 40 92 AND X8, X20, #0xFF.text:000000000001AD94 D6 C2 19 91 ADD X22, X22, #data_rel@PAGEOFF.text:000000000001AD98 38 40 02 91 ADD X24, X1, #0x90.text:000000000001AD9C C8 7A 68 F8 LDR X8, [X22,X8,LSL#3] ; @64[X22 + (X8 << 0x3)], X8.text:000000000001ADA0 29 00 03 91 ADD X9, X1, #0xC0.text:000000000001ADA4 F8 A7 08 A9 STP X24, X9, [SP,#0x88].text:000000000001ADA8 29 A0 02 91 ADD X9, X1, #0xA8.text:000000000001ADAC E9 4F 00 F9 STR X9, [SP,#0x98].text:000000000001ADB0 29 80 02 91 ADD X9, X1, #0xA0.text:000000000001ADB4 3B C0 02 91 ADD X27, X1, #0xB0.text:000000000001ADB8 E9 67 07 A9 STP X9, X25, [SP,#0x70].text:000000000001ADBC 29 40 03 91 ADD X9, X1, #0xD0.text:000000000001ADC0 E9 37 00 F9 STR X9, [SP,#0x68].text:000000000001ADC4 E1 27 00 F9 STR X1, [SP,#0x48].text:000000000001ADC8 FA 43 00 F9 STR X26, [SP,#0x80].text:000000000001ADCC FB 1F 00 F9 STR X27, [SP,#0x38].text:000000000001ADD0 00 01 1F D6 BR X8 |
为什么要贴这段汇编那,其实不贴也可以。因为假如你有一天去你想vmp,并且发现这种br x8,这种,不断取x23内容,加上x22地址,是dex vmp,我调研过有几个类似样本都这样。
然后就进入完全看不懂的乱序执行
有很多图,全部都是乱的。开始我以为是混淆,经过分析以后发现,并没有混淆。但是这个执行顺序完全是乱飞,我们一般对于1个函数,或者说c编译的函数,识别的他的方法是开栈和闭栈并且栈平衡,这是一个完整的函数,但是这个函数全是乱的,没有开栈也没有闭栈。
加固方式识别
对于一个未知的加固方案,如果你想从汇编完全暴力破解他,把他撸出来,而且还是2700w行汇编,难度太高了。所以第一个是识别他,然后去网上找大神的破解方法来对症下药。如何识别那,不断的运行,进行猜测,这个过程会很久,经过分析我发现他里面有大量的jni函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | switch ( v63 ) { case 'B': v72 = (v55->functions->NewByteArray)(v55, v57, a3, a4, a5, a6, a7, a8); goto LABEL_24; case 'C': v72 = (v55->functions->NewCharArray)(v55, v57, a3, a4, a5, a6, a7, a8); goto LABEL_24; case 'D': v72 = (v55->functions->NewDoubleArray)(v55, v57, a3, a4, a5, a6, a7, a8); goto LABEL_24; case 'F': v72 = (v55->functions->NewFloatArray)(v55, v57, a3, a4, a5, a6, a7, a8); goto LABEL_24; case 'I': v72 = (v55->functions->NewIntArray)(v55, v57, a3, a4, a5, a6, a7, a8); goto LABEL_24; case 'J': v72 = (v55->functions->NewLongArray)(v55, v57, a3, a4, a5, a6, a7, a8); goto LABEL_24; case 'S': v72 = (v55->functions->NewShortArray)(v55, v57, a3, a4, a5, a6, a7, a8); goto LABEL_24; case 'Z': v72 = (v55->functions->NewBooleanArray)(v55, v57, a3, a4, a5, a6, a7, a8);LABEL_24: |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 | cls_name = v58->functions->FindClass(v58, v100); functions = v58->functions; v103 = v58; cls_name_2 = cls_name; v105 = v58; obj = *(a39 + 8 * a22); functions->ExceptionClear(&v105->functions); free(v100); method_id = v103->functions->GetMethodID(&v103->functions, cls_name_2, method_name, fun_sign); free(fun_sign); if ( method_id ) { a40 = 0.0; v57 = a32; if ( v95 ) { switch ( *return_type ) { case 'B': v110 = env->functions->CallNonvirtualByteMethodA(env, obj, cls_name_2, method_id, args); goto LABEL_74; case 'C': v115 = env->functions->CallNonvirtualCharMethodA(env, obj, cls_name_2, method_id, args); goto LABEL_87; case 'D': env->functions->CallNonvirtualDoubleMethodA(env, obj, cls_name_2, method_id, args); goto LABEL_89; case 'F': env->functions->CallNonvirtualFloatMethodA(env, obj, cls_name_2, method_id, args); goto LABEL_78; case 'I': v112 = env->functions->CallNonvirtualIntMethodA(env, obj, cls_name_2, method_id, args); goto LABEL_81; case 'J': v113 = COERCE_DOUBLE(env->functions->CallNonvirtualLongMethodA(env, obj, cls_name_2, method_id, args)); goto LABEL_84; case 'L': case '[': v108 = env; v109 = COERCE_DOUBLE(env->functions->CallNonvirtualObjectMethodA(env, obj, cls_name_2, method_id, args)); goto LABEL_68; case 'S': v117 = env->functions->CallNonvirtualShortMethodA(env, obj, cls_name_2, method_id, args); goto LABEL_92; case 'V': env->functions->CallNonvirtualVoidMethodA(env, obj, cls_name_2, method_id, args); goto LABEL_93; case 'Z': v114 = env->functions->CallNonvirtualBooleanMethodA(env, obj, cls_name_2, method_id, args); goto LABEL_96; default: goto LABEL_97; } } switch ( *return_type ) { case 'B': v110 = CallNonvirtualByteMethodV(env, obj, cls_name_2, method_id);LABEL_74: v44 = v110; goto LABEL_75; case 'C': v115 = CallNonvirtualCharMethodV(env, obj, cls_name_2, method_id);LABEL_87: v44 = v115; |
很多很多,在运行中分析这些数据发现他调用很多java的代码,各种各样,有很多我甚至都没有用过。
- 第一个特征使用了大量的jni函数而且,没有什么别的函数
- 第二就是上面贴的这个函数,正常的函数调用,谁没事搞这么多参数,各种各种的jni方法调用啊,摆明了不就是一个通用的c成调用任何java方法的功能吗
- 第三特征,在前面分析入口的时候,遇到一个常量函数列表,在调用中我经过函数交叉引用我发现很多函数都在这个常量函数列表

我觉得不对劲,然后我数了数,刚好256个。这个数字很微妙,而且不正常。 - 第四特征,我对上面的这些函数的功能进行了分析,我发现更像是在执行单条Dalvik 指令(本人对于dalivk分非常熟悉,手写过一段时间smali)。
到这里基本破案了,256条指令对应了256个Dalvik 指令的opcode,虽然很多没用。
vmp框架分析
前面我们说了我们的目标,就是将某一段代码还原。而vmp,还原的方法只能去分析整个vmp的框架,进行功能含义分析,然后通过某一段vm的指令,将他手工转化成java代码。说白了就是一个vmp的反向过程。
- vmp基本单元指令
上文提到的那个256个函数地址的数组,我第一时间就判断为vmp的基本单元指令,毕竟太巧了,而且试试也无妨(对逆向来说猜测并测试也是一种极为重要的方法) - vm运行方式
1 2 3 4 5 | while(1){ //一旦进入虚拟机就会开始读取字节码,除非遇到退出指令,否则一直执行下去 bytecode_ins = read(bytecode_buff); //不断的读取指令 exe(bytecode_ins) //运行指令} |
我签名写的这个,就是vmp简单的执行示意,它必然需要不断的循环运行,来执行基本单元指令,除非基本单元指令退出,否则会无线循环。
但是实际分析过程中,我发现没有while循环,也没有这种wile里读指令,然后根据不同的指令跳转到不同的vmp基本单元指令。(猜测失败的代价就是对自己的技术产生怀疑)
然后我去研究了一下trace,看一下他这个指令之间是如何关联起来的,上一条指令如何跳转到下一条指令。(研究过多条指令,很长的函数还没有间隔,完全不知道出口在哪里,但是很幸运的是有比较短的)
1 2 3 4 5 6 | .text:00000076F68DBDD4 nop ; DATA XREF: .data.rel.ro:00000076F6938940↓o.text:00000076F68DBDD4 F7 0A 00 91 ADD X23, X23, #2 ; monitor:loc_76F690C534↓j.text:00000076F68DBDD8 F4 02 40 79 LDRH W20, [X23].text:00000076F68DBDDC 88 1E 40 92 AND X8, X20, #0xFF.text:00000076F68DBDE0 C8 7A 68 F8 LDR X8, [X22,X8,LSL#3].text:00000076F68DBDE4 00 01 1F D6 BR X8 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | .text:00000076F68E0C0C C9 02 00 B0 ADRP X9, #translator_8_12_2@PAGE.text:00000076F68E0C10 CB 02 00 B0 ADRP X11, #translator_12_16_2@PAGE.text:00000076F68E0C14 29 01 47 F9 LDR X9, [X9,#translator_8_12_2@PAGEOFF].text:00000076F68E0C18 6B 45 47 F9 LDR X11, [X11,#translator_12_16_2@PAGEOFF].text:00000076F68E0C1C 88 2E 48 D3 UBFX X8, X20, #8, #4.text:00000076F68E0C20 8A 3E 4C D3 UBFX X10, X20, #0xC, #4.text:00000076F68E0C24 28 69 68 38 LDRB W8, [X9,X8].text:00000076F68E0C28 69 69 6A 38 LDRB W9, [X11,X10].text:00000076F68E0C2C 28 6D 1C 33 BFI W8, W9, #4, #0x1C.text:00000076F68E0C30 13 1D 00 13 SXTB W19, W8.text:00000076F68E0C34 F3 00 F8 36 TBZ W19, #0x1F, loc_76F68E0C50.text:00000076F68E0C34.text:00000076F68E0C38 28 03 40 39 LDRB W8, [X25].text:00000076F68E0C3C A8 00 20 36 TBZ W8, #4, loc_76F68E0C50.text:00000076F68E0C3C.text:00000076F68E0C40 E8 5B 40 F9 LDR X8, [SP,#arg_B0].text:00000076F68E0C44 E0 27 40 F9 LDR X0, [SP,#arg_48].text:00000076F68E0C48 17 01 1F F8 STUR X23, [X8,#-0x10].text:00000076F68E0C4C F4 C8 00 94 BL sub_76F691301C.text:00000076F68E0C4C.text:00000076F68E0C50.text:00000076F68E0C50 loc_76F68E0C50 ; CODE XREF: goto+28↑j.text:00000076F68E0C50 ; goto+30↑j.text:00000076F68E0C50 F7 C6 33 8B ADD X23, X23, W19,SXTW#1.text:00000076F68E0C54 F4 02 40 79 LDRH W20, [X23].text:00000076F68E0C58 88 1E 40 92 AND X8, X20, #0xFF.text:00000076F68E0C5C C8 7A 68 F8 LDR X8, [X22,X8,LSL#3].text:00000076F68E0C60 00 01 1F D6 BR X8 |
不多贴了,他们的尾部都是一样的,x20 当前指令,x22 data_rel,x23 指令数据表。他是通过上一条指令的内容计算下一条指令的地址,然后读取数据数据,和指令处理的地址,用x8跳过去,他不是一个while模式。写个运行的伪代码的例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | data_rel= 指令数据数组(fun1,fun2,fun3)fun1(){ XXXXXX正文内容 下一套指令地址=read(data_rel(当前的数据)+fun1函数这个指令的长度) bl 下一套指令地址}fun2(){ XXXXXX正文内容 下一套指令地址=read(data_rel(当前的数据)+fun1函数这个指令的长度) bl 下一套指令地址}fun3(){ XXXXXX正文内容 下一套指令地址=read(data_rel(当前的数据)+fun1函数这个指令的长度) bl 下一套指令地址}call fun1 |
这样一旦开始执行,除非遇到退出指令,否则函数会一直执行下去。android dvm虚拟机以前读源码的时候见过这种模式,这种计算指令长度的方式,davlik也确实可以这样搞。他每个指令长度都是可以提前写死的,没有变长的可能。
指令函数分析
我们知道了他的基本单元指令,以及基本单元指令的函数,这个时候我们对基本单元指令进行一个一个的分析,然后将某一个vmp化的java函数vmp指令进行反向转化。
- 裸函数
所有的函数都是裸函数,纯用汇编写的可能性不打,毕竟还有jni函数,这些裸函数直接打乱了ida的反汇编 - 函数代码乱序
很多指令函数其实都是正常顺序的,但是大部分中间都有个错误处理,这些错误处理都会调向同一个函数的位置。直白点就是,这个指令处理的函数开始的内存地址和结束的内存地址是连续的,但是中间有一条错误处理指令,跳到了远方地址,让ida进行函数识别的时候出错了,直接把这个错误处理nop就可以正常分析了。 - dex字符编码支持
这个其实我是没想到了,分析了好久,搞不懂里面有一段很繁琐的代码,到底是干嘛,对于追求优雅和有强迫症的我,这是不能接受的。然后我搞出跑了一下,发现跟一个以前的字符编码格式很像。不知道没关系,也不影响。如果想了解可以看看
1 2 3 4 | v62 = (*(*a30 + 0x58LL) + *(*(*a30 + 16LL) + 4 * v59)); do v64 = *v62++; while ( (v64 & 0x80000000) != 0 ); |
- vmp指令函数匹配davlik指令
这个有很多人说叫指令对照表,不过无所谓,我兄弟的博客中已经说了很多还原的方法,具体啥意思,没完全懂,他好像是数据流向分析+vmp指令分析,但是我在实际还原的过程中使用的是人肉+推倒,不算快,但是速度客观,不算太难。算了,这部分不具体写了,感觉没啥难的,主要还是对于davlik指令要熟悉,后面跟别的一起写为什么这个不难。 - 指令参数匹配
vmp对于寄存器原来的含义,进行了加密,在运行的时候进行解密。寄存器标示着这个寄存器位移栈的位置,这种vmp是有自己定义栈的,但是他的指令的参数所在的位置在运行过程中是和真正davlik相同的,加了一道转化手续而已。下面的代码中有translator_8_12,这个类似的就是做转化的。
vmp指令还原
以前听说360还原用的是对照表。但是逆向到我这个地步,写对照表已经属于浪费时间了,而且对照表还要对着opcode一个一个的改,懒得搞了。我直接写了一个小型的opcode 转smali语言的ida脚本,将vmp指令转变为smali指令,然后写道对应的dex中反编译的smali工程中,进行回编译。直接贴脚本,这是一个的半自动化+手工来进行指令还原的脚本,扔给你们做参考吧。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 | import idaapiglobal_table = 0x78D05D8E80fun_id = 158fun_addr_ref = 0x0instr_fun_table = 0x0# 0x1b4translator_8_12=[3,2,1,0,7,6,5,4,0xb,0xA ,9, 8, 0xF, 0xE, 0xD, 0xC]translator_12_16=[0xB, 0xA, 9, 8, 0xF, 0xE, 0xD, 0xC, 3, 2, 1, 0, 7, 6, 5, 4]def aget(instr_addr,x10): print("aget","arg:") return 4def const_4(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) arg0 = translator_8_12[(instr_0_2 >> 8) & 0xF] arg1 = translator_12_16[instr_0_2 >> 12] print("const/4 v%d, %d"%(arg0,arg1)) return 2def const_16(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) arg0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) print("const/16 v%d, %d"%(arg0,instr_2_4)) return 4def const(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) arg0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) print("const v%d, %d"%(arg0,instr_2_4)) return 6def const_string(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) v60 = instr_0_2 >> 12 v61 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF v63 = 16 * (translator_12_16[v60] & 0xF) v75 = v63 | v61 # a38_index_11 = read_mem_to_Int(x10 + 0x58, 8) a38_index_2 = read_mem_to_Int(x10 + 0x10, 8) v3 = read_mem_to_Int(instr_2_4 * 4 + a38_index_2, 4) string = v3+ a38_index_11 # print("string addr",hex(string),hex(instr_addr)) # cla_len = read_mem_to_Int(string, 1) # return_type = idaapi.dbg_read_memory(string+1, cla_len).decode('utf-8') # # print("const-string ",v75,return_type) print("const-string v%d, %s"%(v75,hex(string))) return 4def xor(instr_addr,x10): print("xor","arg:") return 4def move_16(instr_addr,x10): print("move-16","arg:") return 2def iput_object(instr_addr,x10): print("iput_object","arg:") return 4def aput_object(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v37 = (instr_0_2 >> 8) & 0xF v38 = instr_0_2 >> 12 v40 = translator_8_12[v37]; v41 = translator_12_16[v38]; arg_v1 = v40 & 0xF | (16 * (v41 & 0xF)) arg_v2 = read_mem_to_Int(instr_addr+2, 1) arg_v3 = read_mem_to_Int(instr_addr+3, 1) print("aput-object v%d, v%d, v%d"%(arg_v1,arg_v2,arg_v3)) return 4def goto(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v3 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) if v3 >= 128: int_num = (v3 - 256)*2 else: int_num = v3 *2 print("goto","arg:",hex(instr_addr+int_num),int_num) return 2def rsub(instr_addr,x10): print("rsub","arg:") return 4def cmp(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v1 = read_mem_to_Int(instr_addr+2, 1) v2 = read_mem_to_Int(instr_addr+3, 1) v3 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) print("cmp","arg:",v3,v1,v2) return 4def invoke_super(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_add_4 = read_mem_to_Int(instr_addr+4, 2) v63 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)); #处理一个字节(8 bit)的 数据,作为寄存器转换 register_size = v63 >> 4 arg1 = instr_add_4 & 0xF arg2 = instr_add_4 >> 4 & 0xF arg3 = (instr_add_4 >> 8) & 0xf arg4 = instr_add_4 >> 12 arg5 = v63 & 0xF ref_index = read_mem_to_Int(instr_addr + 2, 2) classname_str = get_class_name(x10,ref_index) method_name_str = get_method_name(x10,ref_index) type_name_str = get_proto_type_name(x10, ref_index) # arg_name_str = get_method_arg(x10,ref_index) # print("invoke_direct class:",classname_str,"method:",method_name_str,"method_ref_index",hex(ref_index),"type:",type_name_str,"register:",register_size,"arg1:",arg1,"arg2:",arg2,"arg3:",arg3,"arg4:",arg4,"arg5:",arg5) print("invoke-super ",classname_str+"->"+method_name_str+type_name_str,"method_ref_index",hex(ref_index),"register:",register_size,"arg1:",arg1,"arg2:",arg2,"arg3:",arg3,"arg4:",arg4,"arg5:",arg5) return 6def invoke_direct(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_add_4 = read_mem_to_Int(instr_addr+4, 2) v63 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)); #处理一个字节(8 bit)的 数据,作为寄存器转换 register_size = v63 >> 4 arg1 = instr_add_4 & 0xF arg2 = instr_add_4 >> 4 & 0xF arg3 = (instr_add_4 >> 8) & 0xf arg4 = instr_add_4 >> 12 arg5 = v63 & 0xF ref_index = read_mem_to_Int(instr_addr + 2, 2) classname_str = get_class_name(x10,ref_index) method_name_str = get_method_name(x10,ref_index) type_name_str = get_proto_type_name(x10, ref_index) # arg_name_str = get_method_arg(x10,ref_index) # print("invoke-direct class:",classname_str,"method:",method_name_str,"method_ref_index",hex(ref_index),"type:",type_name_str,"register:",register_size,"arg1:",arg1,"arg2:",arg2,"arg3:",arg3,"arg4:",arg4,"arg5:",arg5) print("invoke-direct ",classname_str+"->"+method_name_str+type_name_str,"method_ref_index",hex(ref_index),"register:",register_size,"arg1:",arg1,"arg2:",arg2,"arg3:",arg3,"arg4:",arg4,"arg5:",arg5) return 6def invoke_static(instr_addr, x10): # 第一个字节是指令,主导函数偏移,第二个字节是寄存器,三四字节是方法偏移 instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_add_4 = read_mem_to_Int(instr_addr+4, 2) v63 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)); #处理一个字节(8 bit)的 数据,作为寄存器转换 register_size = v63 >> 4 arg1 = instr_add_4 & 0xF arg2 = instr_add_4 >> 4 & 0xF arg3 = (instr_add_4 >> 8) & 0xf arg4 = instr_add_4 >> 12 arg5 = v63 & 0xF ref_index = read_mem_to_Int(instr_addr + 2, 2) classname_str = get_class_name(x10,ref_index) method_name_str = get_method_name(x10,ref_index) type_name_str = get_proto_type_name(x10, ref_index) # arg_name_str = get_method_arg(x10,ref_index) # print("invoke-static class:",classname_str,"method:",method_name_str,"method_ref_index",hex(ref_index),"type:",type_name_str,"register:",register_size,"arg1:",arg1,"arg2:",arg2,"arg3:",arg3,"arg4:",arg4,"arg5:",arg5) print("invoke-static ",classname_str+"->"+method_name_str+type_name_str,"method_ref_index",hex(ref_index),"register:",register_size,"arg1:",arg1,"arg2:",arg2,"arg3:",arg3,"arg4:",arg4,"arg5:",arg5) # print("CallStaticVoidMethod arg_name_str:",arg_name_str) return 6def invoke_interface(instr_addr,x10): # 第一个字节是指令,主导函数偏移,第二个字节是寄存器,三四字节是方法偏移 instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_add_4 = read_mem_to_Int(instr_addr+4, 2) v63 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)); #处理一个字节(8 bit)的 数据,作为寄存器转换 register_size = v63 >> 4 arg1 = instr_add_4 & 0xF arg2 = instr_add_4 >> 4 & 0xF arg3 = (instr_add_4 >> 8) & 0xf arg4 = instr_add_4 >> 12 arg5 = v63 & 0xF ref_index = read_mem_to_Int(instr_addr + 2, 2) classname_str = get_class_name(x10,ref_index) method_name_str = get_method_name(x10,ref_index) type_name_str = get_proto_type_name(x10, ref_index) # arg_name_str = get_method_arg(x10,ref_index) print("invoke-interface ",classname_str+"->"+method_name_str+type_name_str,"method_ref_index",hex(ref_index),"register:",register_size,"arg1:",arg1,"arg2:",arg2,"arg3:",arg3,"arg4:",arg4,"arg5:",arg5) # print("CallStaticVoidMethod arg_name_str:",arg_name_str) return 6def invoke_virutal(instr_addr,x10): # 第一个字节是指令,主导函数偏移,第二个字节是寄存器,三四字节是方法偏移 instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_add_4 = read_mem_to_Int(instr_addr+4, 2) v63 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)); #处理一个字节(8 bit)的 数据,作为寄存器转换 register_size = v63 >> 4 arg1 = instr_add_4 & 0xF arg2 = instr_add_4 >> 4 & 0xF arg3 = (instr_add_4 >> 8) & 0xf arg4 = instr_add_4 >> 12 arg5 = v63 & 0xF ref_index = read_mem_to_Int(instr_addr + 2, 2) classname_str = get_class_name(x10,ref_index) method_name_str = get_method_name(x10,ref_index) type_name_str = get_proto_type_name(x10, ref_index) # arg_name_str = get_method_arg(x10,ref_index) print("invoke-virtual ",classname_str+"->"+method_name_str+type_name_str,"method_ref_index",hex(ref_index),"register:",register_size,"arg1:",arg1,"arg2:",arg2,"arg3:",arg3,"arg4:",arg4,"arg5:",arg5) # print("CallStaticVoidMethod arg_name_str:",arg_name_str) return 6def rem_doule(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) instr_2_4 = read_mem_to_Int(instr_addr + 2, 2) print("rem-doule",hex(v_arg_0),hex(instr_2_4)) return 4def move_result_object(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) instr_2_4 = read_mem_to_Int(instr_addr + 2, 2) print("move-result-object v%d"%v_arg_0) return 2def MonitorEnter(instr_addr,x10): print("MonitorEnter","arg:") return 2def return_object(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) print("return-object v%d"%v_arg_0) return 2def move_object(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF]; v_arg_1 = translator_12_16[instr_0_2 >> 12] print("move-object v%d, v%d"%(v_arg_0,v_arg_1)) return 2def new_instance(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) ref_index = read_mem_to_Int(instr_addr + 2, 2) dex_base_addr = read_mem_to_Int(x10 + 0x58, 8) dex_type_off = read_mem_to_Int(x10 + 0x18, 8) dex_string_list_off = read_mem_to_Int(x10 + 0x10, 8) classname_str = byIndexGet_dex_type_name(dex_base_addr,dex_type_off,dex_string_list_off,ref_index) print("new-instance v%d, %s"%(v_arg_0,classname_str)) return 4def move_result(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) print("move-result v%d"%v_arg_0) return 2def new_array(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_size = translator_12_16[instr_0_2 >> 12] v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF]; ref_index = read_mem_to_Int(instr_addr + 2, 2) dex_base_addr = read_mem_to_Int(x10 + 0x58, 8) dex_type_off = read_mem_to_Int(x10 + 0x18, 8) dex_string_list_off = read_mem_to_Int(x10 + 0x10, 8) classname_str = byIndexGet_dex_type_name(dex_base_addr,dex_type_off,dex_string_list_off,ref_index) print("new-array v%d, v%d, %s"%(v_arg_0,v_arg_size,classname_str)) return 4def if_ne(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) arg1 = translator_8_12[(instr_0_2 >> 8) & 0xF]; arg2 = translator_12_16[instr_0_2 >> 12]; print("if-ne v%d, v%x, %x"%(arg1,arg2,instr_addr+instr_2_4*2)) return 4def if_eqz(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) v63 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)); #处理一个字节(8 bit)的 数据,作为寄存器转换 print("if-eqz v%d, %x"%(v63,instr_addr+instr_2_4*2)) return 4def if_gt(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) arg1 = translator_8_12[(instr_0_2 >> 8) & 0xF]; arg2 = translator_12_16[instr_0_2 >> 12]; print("if-gt v%d, v%x, %x"%(arg1,arg2,instr_addr+instr_2_4*2)) return 4def if_lt(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) arg1 = translator_8_12[(instr_0_2 >> 8) & 0xF]; arg2 = translator_12_16[instr_0_2 >> 12]; print("if-lt v%d, v%x, %x"%(arg1,arg2,instr_addr+instr_2_4*2)) return 4def if_lez(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) v63 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)); #处理一个字节(8 bit)的 数据,作为寄存器转换 print("if-lez v%d, %x"%(v63,instr_addr+instr_2_4*2)) return 4def if_nez(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) instr_2_4 = read_mem_to_Int(instr_addr+2, 2) v63 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)); #处理一个字节(8 bit)的 数据,作为寄存器转换 print("if-nez v%d, %x"%(v63,instr_addr+instr_2_4*2)) return 4def iput(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) filed_index = read_mem_to_Int(instr_addr+2, 2) v_arg_0 = translator_12_16[instr_0_2 >> 12] v_arg_1 = translator_8_12[(instr_0_2 >> 8) & 0xF] dex_filed_off = read_mem_to_Int(x10 + 0x20, 8) class_index = read_mem_to_Int(8 * filed_index + dex_filed_off, 2) filed_type_index = read_mem_to_Int(8 * filed_index + dex_filed_off+2, 2) name_string_index = read_mem_to_Int(8 * filed_index + dex_filed_off+4, 2) dex_base_addr = read_mem_to_Int(x10 + 0x58, 8) dex_type_off = read_mem_to_Int(x10 + 0x18, 8) dex_string_list_off = read_mem_to_Int(x10 + 0x10, 8) class_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, class_index) filed_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, filed_type_index) name_string = byIndexGet_dex_string_name(dex_base_addr,dex_string_list_off,name_string_index) # print("iput-object ",v_arg_0,v_arg_1,class_type_string,"->",name_string,";",filed_type_string,"filed_index:",filed_index) print("iput-object v%d, v%d, %s"%(v_arg_1,v_arg_0,class_type_string+"->"+name_string+":"+filed_type_string+" filed_index: "+filed_index)) return 4def aget_object(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) arg_1 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) arg_v2 = read_mem_to_Int(instr_addr+2, 1) arg_v3 = read_mem_to_Int(instr_addr+3, 1) print("aget-object v%d, v%d, v%d"%(arg_1,arg_v2,arg_v3)) return 4def iget_object(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) filed_index = read_mem_to_Int(instr_addr+2, 2) v_arg_0 = translator_12_16[instr_0_2 >> 12] v_arg_1 = translator_8_12[(instr_0_2 >> 8) & 0xF] dex_filed_off = read_mem_to_Int(x10 + 0x20, 8) class_index = read_mem_to_Int(8 * filed_index + dex_filed_off, 2) filed_type_index = read_mem_to_Int(8 * filed_index + dex_filed_off+2, 2) name_string_index = read_mem_to_Int(8 * filed_index + dex_filed_off+4, 2) dex_base_addr = read_mem_to_Int(x10 + 0x58, 8) dex_type_off = read_mem_to_Int(x10 + 0x18, 8) dex_string_list_off = read_mem_to_Int(x10 + 0x10, 8) class_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, class_index) filed_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, filed_type_index) name_string = byIndexGet_dex_string_name(dex_base_addr,dex_string_list_off,name_string_index) print("iget-object v%d, v%d, %s"%(v_arg_1,v_arg_0,class_type_string+"->"+name_string+":"+filed_type_string+" filed_index: "+filed_index)) return 4def check_cast(instr_addr,x10): type_index = read_mem_to_Int(instr_addr+2, 2) dex_base_addr = read_mem_to_Int(x10 + 0x58, 8) dex_type_off = read_mem_to_Int(x10 + 0x18, 8) dex_string_list_off = read_mem_to_Int(x10 + 0x10, 8) type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, type_index) instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) print("check-cast v%d, %s"%(v_arg,type_string)) return 4def sget_object(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) filed_index = read_mem_to_Int(instr_addr+2, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) dex_filed_off = read_mem_to_Int(x10 + 0x20, 8) class_index = read_mem_to_Int(8 * filed_index + dex_filed_off, 2) filed_type_index = read_mem_to_Int(8 * filed_index + dex_filed_off+2, 2) name_string_index = read_mem_to_Int(8 * filed_index + dex_filed_off+4, 2) dex_base_addr = read_mem_to_Int(x10 + 0x58, 8) dex_type_off = read_mem_to_Int(x10 + 0x18, 8) dex_string_list_off = read_mem_to_Int(x10 + 0x10, 8) class_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, class_index) filed_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, filed_type_index) name_string = byIndexGet_dex_string_name(dex_base_addr,dex_string_list_off,name_string_index) print("sget-object v%d, %s"%(v_arg_0,class_type_string+"->"+name_string+":"+filed_type_string)) return 4def sget_boolean(instr_addr, x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) filed_index = read_mem_to_Int(instr_addr+2, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) dex_filed_off = read_mem_to_Int(x10 + 0x20, 8) class_index = read_mem_to_Int(8 * filed_index + dex_filed_off, 2) filed_type_index = read_mem_to_Int(8 * filed_index + dex_filed_off+2, 2) name_string_index = read_mem_to_Int(8 * filed_index + dex_filed_off+4, 2) dex_base_addr = read_mem_to_Int(x10 + 0x58, 8) dex_type_off = read_mem_to_Int(x10 + 0x18, 8) dex_string_list_off = read_mem_to_Int(x10 + 0x10, 8) class_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, class_index) filed_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, filed_type_index) name_string = byIndexGet_dex_string_name(dex_base_addr,dex_string_list_off,name_string_index) print("sget-boolean v%d, %s"%(v_arg_0,class_type_string+"->"+name_string+":"+filed_type_string)) return 4def nop(instr_addr,x10): print("nop") return 2def return_void(instr_addr,x10): print("return-void") return 2def throw(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) print("throw v%d"%v_arg_0) return 2def throw_2(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) v_arg_0 = translator_8_12[(instr_0_2 >> 8) & 0xF] & 0xF | (16 * (translator_12_16[instr_0_2 >> 12] & 0xF)) print("move-exception v%d"%v_arg_0) return 2def array_length(instr_addr,x10): instr_0_2 = read_mem_to_Int(instr_addr, 2) arg_0 = translator_12_16[instr_0_2 >> 12] arg_1 = translator_8_12[(instr_0_2 >> 8) & 0xF] print("array-length v%d, v%d"%(arg_1,arg_0)) return 2switch = {0x0:iput, 0x1:invoke_super, 0x2:aget, 0x3:xor, 0x4:move_16, 0x5:iput_object, 0x5a:nop, 0xd:goto, 0xda:aput_object , 0x7:rsub, 0x8:cmp, 0x1e:if_lez, 0x2b:if_nez, 0x3e:if_eqz, 0x3c:if_gt,0x21:if_lt,0x44:const_16, 0xc3:const, 0x5e:move_result , 0x68:invoke_direct, 0xA6:invoke_virutal, 0xAA:new_instance, 0xc7:move_result_object, 0xbb:return_object, 0x92:return_void, 0xfc:move_object, 0x79:invoke_interface, 0xf9:check_cast, 0xf0:const_4, 0xfa:if_ne, 0x93:sget_object, 0xc2:sget_boolean, 0x9a:invoke_static, 0x9b:const_string, 0x1f:new_array, 0x19:iget_object, 0x9d:MonitorEnter,0xc4:array_length,0x6b:aget_object,0xf5:throw,0xee:throw_2}def ByFunIDgetFunAddr(id): offset_mem = int.from_bytes(idaapi.dbg_read_memory(4*id+global_table,4),byteorder='little') method_addr = global_table+offset_mem print("fun_id:",hex(id),"method_addr:",hex(offset_mem),"method_addr:",hex(method_addr)) return method_addrdef read_mem_to_String(addr,size): mem = idaapi.dbg_read_memory(addr,size) return memdef read_mem_to_Int(addr, size): mem = int.from_bytes(idaapi.dbg_read_memory(addr,size),byteorder='little') return memdef get_proto_type_name(x10, type_index): dex_method_off = read_mem_to_Int(x10 + 0x28, 8) dex_string_list_off = read_mem_to_Int(x10 + 0x10, 8) dex_type_off = read_mem_to_Int(x10 + 0x18, 8) dex_base_addr = read_mem_to_Int(x10 + 0x58, 8) dex_proto_off = read_mem_to_Int(x10 + 0x30, 8) proto_index = read_mem_to_Int(8 * type_index + dex_method_off + 2, 2) return_type_index = read_mem_to_Int(dex_proto_off + 12 * proto_index + 4,4) pararm_off = read_mem_to_Int(dex_proto_off + 12 * proto_index + 8,4) sign_type_string_list = "(" if pararm_off != 0: pararm_size = read_mem_to_Int(dex_base_addr+pararm_off,4) # pararm_mem_total = pararm_size * 2 # for i in pararm_size: for i in range(pararm_size): pararm_type_index = read_mem_to_Int(dex_base_addr + pararm_off+4+i*2, 2) pararm_type_string = byIndexGet_dex_type_name(dex_base_addr, dex_type_off, dex_string_list_off, pararm_type_index) sign_type_string_list =sign_type_string_list+pararm_type_string return_type_string = byIndexGet_dex_type_name(dex_base_addr,dex_type_off,dex_string_list_off,return_type_index) sign_type_string_list=sign_type_string_list+")"+return_type_string return sign_type_string_listdef byIndexGet_dex_type_name(dex_base_addr,dex_type_off,dex_string_list_off,pararm_type_index): string_index = read_mem_to_Int(pararm_type_index * 4 + dex_type_off, 4) type_string = byIndexGet_dex_string_name(dex_base_addr,dex_string_list_off,string_index) return type_stringdef byIndexGet_dex_string_name(dex_base_addr,dex_string_list_off,string_index): v3 = read_mem_to_Int(string_index * 4 + dex_string_list_off, 4) cla_len = read_mem_to_Int(dex_base_addr+v3,1) class_str = idaapi.dbg_read_memory(dex_base_addr+v3+1, cla_len).decode('utf-8') print("byIndexGet_dex_string_name:",hex(dex_base_addr+v3)) return class_strdef get_class_name(x10,class_index): a38_index_5 = read_mem_to_Int(x10 + 0x28, 8) a38_index_2 = read_mem_to_Int(x10 + 0x10, 8) a38_index_3 = read_mem_to_Int(x10 + 0x18, 8) a38_index_11 = read_mem_to_Int(x10 + 0x58, 8) v1 = read_mem_to_Int(8 * class_index + a38_index_5, 2) v2 = read_mem_to_Int(v1 * 4 + a38_index_3, 4) v3 = read_mem_to_Int(v2 * 4 + a38_index_2, 4) class_str_addr = v3+a38_index_11 cla_len = read_mem_to_Int(class_str_addr, 1) class_str = idaapi.dbg_read_memory(class_str_addr+1, cla_len).decode('utf-8') # print("classname len:",cla_len) return class_strdef get_method_name(x10, method_index): a38_index_5 = read_mem_to_Int(x10 + 0x28, 8) a38_index_2 = read_mem_to_Int(x10 + 0x10, 8) a38_index_3 = read_mem_to_Int(x10 + 0x18, 8) a38_index_11 = read_mem_to_Int(x10 + 0x58, 8) v1 = read_mem_to_Int(8 * method_index + a38_index_5 + 4, 2) v3 = read_mem_to_Int(v1 * 4 + a38_index_2, 4) method_name_str_addr = v3 + a38_index_11 method_name_str_len = read_mem_to_Int(method_name_str_addr, 1) method_name_str = idaapi.dbg_read_memory(method_name_str_addr+1, method_name_str_len).decode('utf-8') return method_name_strdef get_method_arg(x10, index): # (v70 + * (v69 + 4LL * * (v68 + 4LL * * (v81 + v84 + 2)))); a38_index_5 = read_mem_to_Int(x10 + 0x28, 8) a38_index_2 = read_mem_to_Int(x10 + 0x10, 8) a38_index_3 = read_mem_to_Int(x10 + 0x18, 8) a38_index_11 = read_mem_to_Int(x10 + 0x58, 8) a38_index_6 = read_mem_to_Int(x10 + 0x30, 8) v0 = read_mem_to_Int(8 * index + a38_index_5 + 2, 2) v80 = read_mem_to_Int(a38_index_6 + 12 * v0 + 8,4) print("arg_addr a38_index_5:",hex(a38_index_5)) print("arg_addr a38_index_2:",hex(a38_index_2)) print("arg_addr a38_index_3:",hex(a38_index_3)) print("arg_addr a38_index_11:",hex(a38_index_11)) print("arg_addr a38_index_6:",hex(a38_index_6)) print("arg_addr v80:",v80) v81 = v80 + a38_index_11 # print("arg_addr v81:",v81) v1 = read_mem_to_Int(v81+2, 4) v2 = read_mem_to_Int(v1 * 4 + a38_index_3, 4) v3 = read_mem_to_Int(v2 * 4 + a38_index_2, 4) return_type = v3+a38_index_11 # cla_len = read_mem_to_Int(return_type, 1) # return_type = idaapi.dbg_read_memory(return_type+1, cla_len).decode('utf-8') print("arg_addr:",return_type) return return_type# def instr_handle(instr_addr,x10):# offset_mem = read_mem(instr_addr,2) & 0xff# instr_len = dexinstr[offset_mem](instr_addr,x10)## return instr_lendef get_segment_address(segment_name): seg = idaapi.get_segm_by_name(segment_name) if seg is not None: return seg.start_ea, seg.end_ea else: return None# 使用方法def main(): method_addr = ByFunIDgetFunAddr(fun_id) register_size = read_mem_to_Int(method_addr, 2) ins_size = read_mem_to_Int(method_addr+2, 2) insns_size = read_mem_to_Int(method_addr+12, 4) print("method registers_size:",hex(register_size)) print("method ins_size:",hex(ins_size)) print("method insns_size:",hex(insns_size)) method_addr_2 = ByFunIDgetFunAddr(fun_id+1) funSize = method_addr_2 - method_addr print("method_size:",hex(funSize)) instr_addr = method_addr+0x10 print("method_end:",hex(instr_addr+insns_size*2 )) while(1): offset = read_mem_to_Int(instr_addr, 2) & 0xff #第一个字节 instr_fun_addr = instr_fun_table+offset*8 print("-----------------------------------") print("instr_fun_addr:", hex(instr_fun_addr),hex(offset)) instr_handle = switch[offset] print("instr_addr:", hex(instr_addr)) print(hex(offset)) if(instr_handle == None): break instr_len = instr_handle(instr_addr, fun_addr_ref) instr_addr = instr_addr + instr_len print(hex(offset))def init_var(): global global_table global instr_fun_table global fun_addr_ref bss_start, bss_end = get_segment_address(".bss") qword_78B9BFCDC8 = read_mem_to_Int(bss_start + 0x2B8, 8) global_table = read_mem_to_Int(bss_start + 0x270, 8) yaq2__sec = read_mem_to_Int(bss_start + 0x2B0, 8) v6 = yaq2__sec+ fun_id *12 v6_index_1 = read_mem_to_Int(v6 + 4, 4) v6_index_2 = read_mem_to_Int(v6 + 8, 4) fun_addr_ref = read_mem_to_Int(8 * (v6_index_2 - 1) + qword_78B9BFCDC8, 8) instr_fun_table, data_rel_end = get_segment_address(".data.rel.ro") print("qword_78B9BFCDC8", hex(qword_78B9BFCDC8)) print("global_table", hex(global_table)) print("v6_index_1", hex(v6_index_1)) print("v6_index_2", hex(v6_index_2)) print("fun_addr_ref", hex(fun_addr_ref))if __name__ == '__main__': init_var() main() |
效果图,我就不贴
大致讲一下这个脚本原理思路和使用
这个脚本需要在vmp已经装载完成以后调用,找到还原的dex和对应的vmp指令地址,可以直接循环翻译成smali指令
- dex文件的骨架(内存地址),来解析辅助davlik指令反编译
- 具体某个函数的vmp指令,进行转化,通过函数index和vmp规则进行计算
- 函数长度,人工分析+寻找return类指令
这个脚本需要在vmp已经装载完成以后调用,找到还原的dex和对应的vmp指令地址,可以直接循环翻译成smali指令。具体的指令是有具体的长度写在代码里的。smali函数结束都有smali指令的返回指令(return类指令),可以随便找个smali工程看一下,函数结束都有一个return类指令.也有可能是其中的一个返回,通过跳转指令结合分析
dex vmp安全性论述
易攻击的缺点
dex vmp 虽然跟二进制vmp的原理一样,但是他的逆向难度和vmp却不是一个量级的。为什么会出现这种情况
- dex vmp的基础支撑其实是jni函数,而这些函数熟悉人的人过于的多,能进行分析和追踪的方法也很多,有经验和耐心的甚至可以通过jni方法追踪来分析代码。
- dex vmp的框架设计和运行原理跟我早起读过的dvm虚拟机的解释模式基本差不多。
- dex vmp的指令设计是跟davlik指令有着一对一的关系,可以说只是一个简单的对照关系,这导致如果对于davlik指令足够熟悉,相当于对于dex vmp的指令熟悉。
对于一个vmp虚拟机,如果你熟悉他的程序,熟悉他的指令,知道如何测试他(通过jni将dex vmp当作黑河测试),这种情况下,即使不去完全的人肉分析每一条指令,完全通过测试分析,也是可以慢慢进行还原的。
已知的保护措施
这个已知保护措施是dex vmp在可被逆向的情况下,如果提高一些安全性
- 指令对照加密进行动态版本变更
- 指令参数再加一层对照加密
目前就知道这两个,如果dex vmp对照表已经被破解,如果有这两种保护措施,也无法被自动换还原。
不知道有没有一种通讯协议进行加解密破解的感觉,而dex vmp是一种拥有一定规律,可被暴力分析和破解的算法
易分析的davlik指令
分析vmp指令,对他进行还原的时候,并没有非常具体的写。在这里一切写,这是一些写davlik指令,或者说反编译分析davlik的一些经验。
davlik指令是非常容易分析的,基本不太存在保护的价值,因为一般的防护扛不住静态分析工具的分析,这个他的设计是有很大关系的。
上下文关联性强,基本都是编译器自动生成,不存在dalvik底层对抗问题
dalvik中的部分指令有很强的关联性。比如
1 2 | 0000: invoke-static {}, Lcom/hepta/davlik/JvmRuntime;->getClassLoaderList()[Ljava/lang/ClassLoader; # method@00120003: move-result-object v0 |
前面这个invoke-static ,如果有返回值,必会跟这后面这条指令,甚至可以说他们是一条指令
1 2 | 001e: const-string v2, "/libjvmRuntime.so" # string@00060020: invoke-virtual {v1, v2}, Ljava/lang/StringBuilder;->append(Ljava/lang/String;)Ljava/lang/StringBuilder; # method@0028 |
变量在定义之后,有大概率在下一条就会使用,当然不是绝对
1 2 | 000b: new-instance v1, Ljava/lang/StringBuilder; # type@001f000d: invoke-direct {v1}, Ljava/lang/StringBuilder;-><init>()V # method@0026 |
这是new一个对象的代码,会立即调用init方法
1 2 3 | return-voidreturn-objectreturn vAA |
函数结束必有return指令,当然遇到return不一定是结束。但是进行人工还原的时候通过上下文分析函数结束位置,还是非常有价值的。
变量类型明确,指令基本很少有歧义性
有很多操作相同,但是操作类型却不同的指令

这一条aget指令,针对于各种不同的类型有不同的指令。在指令中有个对应的索引,我们甚至可以直接查看这个类型来反向推理这个指令操作的是什么类型。这种设计也从侧面给说明了,dalvik一个指令只有一个解释,没有歧义性,不想汇编,c,不知道类型,更不知道操作具体是什么,只是数据进行了操作。即使是一些虚函数,java中你可能分不出来他具体调用的是那个类的,但是在dalvik中,这个类的类型已经写死在索引中了。
真正的功能指令少
虽然dalvik号称256个opcode,但是有很多不用的,还有一些是同一个功能,但是不同类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 | switch (opcode.format) { case Format10t: return new FixDexBackedInstruction10t(dexFile, opcode, instructionStartOffset,reader); case Format10x: return new DexBackedInstruction10x(dexFile, opcode, instructionStartOffset); // case Format11n: return new FixDexBackedInstruction11n(dexFile, opcode, instructionStartOffset,reader); case Format11x: return new FixDexBackedInstruction11x(dexFile, opcode, instructionStartOffset,reader); case Format12x: return new FixDexBackedInstruction12x(dexFile, opcode, instructionStartOffset,reader); case Format20bc: return new FixDexBackedInstruction20bc(dexFile, opcode, instructionStartOffset,reader); case Format20t: return new FixDexBackedInstruction20t(dexFile, opcode, instructionStartOffset,reader); case Format21c: return new FixDexBackedInstruction21c(dexFile, opcode, instructionStartOffset,reader); case Format21ih: return new FixDexBackedInstruction21ih(dexFile, opcode, instructionStartOffset,reader); case Format21lh: return new FixDexBackedInstruction21lh(dexFile, opcode, instructionStartOffset,reader); case Format21s: return new FixDexBackedInstruction21s(dexFile, opcode, instructionStartOffset,reader); case Format21t: return new FixDexBackedInstruction21t(dexFile, opcode, instructionStartOffset,reader); case Format22b: return new FixDexBackedInstruction22b(dexFile, opcode, instructionStartOffset,reader); case Format22c: return new FixDexBackedInstruction22c(dexFile, opcode, instructionStartOffset,reader); case Format22cs: return new FixDexBackedInstruction22cs(dexFile, opcode, instructionStartOffset,reader); case Format22s: return new FixDexBackedInstruction22s(dexFile, opcode, instructionStartOffset,reader); case Format22t: return new FixDexBackedInstruction22t(dexFile, opcode, instructionStartOffset,reader); case Format22x: return new FixDexBackedInstruction22x(dexFile, opcode, instructionStartOffset,reader); case Format23x: return new FixDexBackedInstruction23x(dexFile, opcode, instructionStartOffset,reader); case Format30t: return new FixDexBackedInstruction30t(dexFile, opcode, instructionStartOffset,reader); case Format31c: return new FixDexBackedInstruction31c(dexFile, opcode, instructionStartOffset,reader); case Format31i: return new FixDexBackedInstruction31i(dexFile, opcode, instructionStartOffset,reader); case Format31t: return new FixDexBackedInstruction31t(dexFile, opcode, instructionStartOffset,reader); case Format32x: return new FixDexBackedInstruction32x(dexFile, opcode, instructionStartOffset,reader); case Format35c: return new FixDexBackedInstruction35c(dexFile, opcode, instructionStartOffset,reader); case Format35ms: return new FixDexBackedInstruction35ms(dexFile, opcode, instructionStartOffset,reader); case Format35mi: return new FixDexBackedInstruction35mi(dexFile, opcode, instructionStartOffset,reader); case Format3rc: return new FixDexBackedInstruction3rc(dexFile, opcode, instructionStartOffset,reader); case Format3rmi: return new FixDexBackedInstruction3rmi(dexFile, opcode, instructionStartOffset,reader); case Format3rms: return new FixDexBackedInstruction3rms(dexFile, opcode, instructionStartOffset,reader); case Format45cc: return new FixDexBackedInstruction45cc(dexFile, opcode, instructionStartOffset,reader); case Format4rcc: return new FixDexBackedInstruction4rcc(dexFile, opcode, instructionStartOffset,reader); case Format51l: return new FixDexBackedInstruction51l(dexFile, opcode, instructionStartOffset,reader); case PackedSwitchPayload: return new FixDexBackedPackedSwitchPayload(dexFile, instructionStartOffset,reader); case SparseSwitchPayload: return new FixDexBackedSparseSwitchPayload(dexFile, instructionStartOffset,reader); case ArrayPayload: return new FixDexBackedArrayPayload(dexFile, instructionStartOffset,reader); default: throw new ExceptionWithContext("Unexpected opcode format: %s", opcode.format.toString()); |
这是smali解析的dalvik指令,就上面这些功能,不算多。
指令以方法为单位,封闭性好
dalvik的指令如果想要运行,必须在一个method里,不可能超出一个函数的范围,更不可能先汇编语言那样全局的大跳,动态跳转地址,每一个函数都是一个密封的黑盒,当然可能会有一些类变量什么的,但是就代码含义分析这一块基本没问题。
Future
一般在这个位置都是要吹牛逼的,但是我发现牛逼可能成真,就留个悬念。
最后
如果真的觉得可以就关注一下公众号吧。也不发图推广了。
哦,对了,我这脚本配合人工半自动换,是可以做到一个函数一个函数还原的,我经过测试了,图,就不贴,怕人找,虽然目前没人找过。
我随便找的其中的某个样本,发的照片,很多样本好像都差不多,都是这个逆向思路
更多【Android安全-vmp入门(一):android dex vmp还原和安全性论述】相关视频教程:www.yxfzedu.com
相关文章推荐
- 软件逆向- PE格式:分析IatHook并实现 - Android安全CTF对抗IOS安全
- Android安全-安卓API自动化安全扫描 - Android安全CTF对抗IOS安全
- 二进制漏洞- Chrome v8 Issue 1307610漏洞及其利用分析 - Android安全CTF对抗IOS安全
- iOS安全-IOS 脱壳入坑经验分享 - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows UAF 漏洞分析CVE-2014-4113 - Android安全CTF对抗IOS安全
- CTF对抗-lua 逆向学习 & RCTF picstore 还原代码块 - Android安全CTF对抗IOS安全
- Android安全-如何修改unity HybridCLR 热更dll - Android安全CTF对抗IOS安全
- 软件逆向-浅谈编译器对代码的优化 - Android安全CTF对抗IOS安全
- 二进制漏洞-年终CLFS漏洞汇总分析 - Android安全CTF对抗IOS安全
- 软件逆向-自动化提取恶意文档中的shellcode - Android安全CTF对抗IOS安全
- 二进制漏洞-铁威马TerraMaster CVE-2022-24990&CVE-2022-24989漏洞分析报告 - Android安全CTF对抗IOS安全
- 4-seccomp-bpf+ptrace实现修改系统调用原理(附demo) - Android安全CTF对抗IOS安全
- 二进制漏洞-Windows内核提权漏洞CVE-2018-8120分析 - Android安全CTF对抗IOS安全
- CTF对抗-Hack-A-Sat 2020预选赛 beckley - Android安全CTF对抗IOS安全
- CTF对抗-]2022KCTF秋季赛 第十题 两袖清风 - Android安全CTF对抗IOS安全
- CTF对抗-kctf2022 秋季赛 第十题 两袖清风 wp - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 4 动态链接 - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 3 静态链接 - Android安全CTF对抗IOS安全
- CTF对抗-22年12月某春秋赛题-Random_花指令_Chacha20_RC4 - Android安全CTF对抗IOS安全
- Pwn-(pwn零基础入门到进阶)第一章 二进制文件 & 2 ELF文件格式 - Android安全CTF对抗IOS安全
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com