今天闲的没事,突然在想,有没有可能做一个文件,既可以作为图片看,又可以用 C++ 编译器编译?
图片格式
C++ 编译器在遇到不认识的字符时会直接报错,所以我们需要一个纯文本的图片格式,至少 Header 部分一定要是纯文本的,因为后面的用户数据我们可以通过各种方法来绕过(比如加上 /* */,使用 #if 0 等),但 Header 除了使用预处理器以外,我们几乎没法控制。
在查找了一番以后,我发现一个图片格式,它完美符合我的要求:PAM——Portable Arbitrary Map
根据它的 spec,一个 PAM 格式的图片,它的 Header 可以是这样的:
P7
WIDTH 100
HEIGHT 100
DEPTH 4
MAXVAL 255
TUPLTYPE RGB_ALPHA
ENDHDR
[二进制图片数据,RRGGBBAA]
同时,Header 部分还可以使用 # 开头进行注释。嗯?这不正好就是 C++ 的预处理器的开头吗?
构造图片
于是在此基础上,我们就有两种构造可以编译的图片的思路了。首先,我们可以把源码全部塞进 Header 里面,图片还是图片;其次,我们可以把源码作为二进制图片数据的一部分,把 Header 部分用 #if 0 忽略掉,让他可以过编译。
随便找张测试图片吧:

Approch 1
首先来实现把源码全部塞进 Header 里面的思路:我们大概需要构造一个这样的 PAM Header:
P7
_src_line1
WIDTH 100
HEIGHT 100
DEPTH 3
MAXVAL 255
TUPLTYPE RGB
ENDHDR
用 Node.JS 实现如下:
import * as fs from 'fs';
import * as path from 'path';
import { PNG } from 'pngjs';
function createPolyglot1(imagePath: string, cppCode: string, outputPath: string) {
const imageData = fs.readFileSync(imagePath);
const png = PNG.sync.read(imageData);
const width = png.width;
const height = png.height;
const hasAlpha = png.data.length === width * height * 4;
const depth = hasAlpha ? 4 : 3;
const bytesPerPixel = depth;
const imageBytes = Buffer.alloc(width * height * bytesPerPixel);
for (let i = 0; i < width * height; i++) {
for (let j = 0; j < bytesPerPixel; j++) {
imageBytes[i * bytesPerPixel + j] = png.data[i * 4 + j];
}
}
const lines = cppCode.split('\n');
const preprocessor: string[] = [];
const code: string[] = [];
for (const line of lines) {
if (line.trim().startsWith('#')) {
preprocessor.push(line);
} else {
code.push(line);
}
}
const header = `P7
${preprocessor.join('\n')}
#define _src ${code.join(' ')}
_src
#if 0
WIDTH ${width}
HEIGHT ${height}
DEPTH ${depth}
MAXVAL 255
TUPLTYPE ${hasAlpha ? 'RGB_ALPHA' : 'RGB'}
ENDHDR
`;
const footer = Buffer.from('\n#endif\n');
const output = Buffer.concat([
Buffer.from(header),
imageBytes,
footer
]);
fs.writeFileSync(outputPath, output);
console.log(`Generated: ${outputPath}`);
}
const imagePath = process.argv[2] || 'input.png';
const cppPath = process.argv[3] || 'input.cpp';
const outputPath = process.argv[4] || 'output1.pam';
const cppCode = fs.readFileSync(cppPath, 'utf-8');
createPolyglot1(imagePath, cppCode, outputPath);
测试一下:
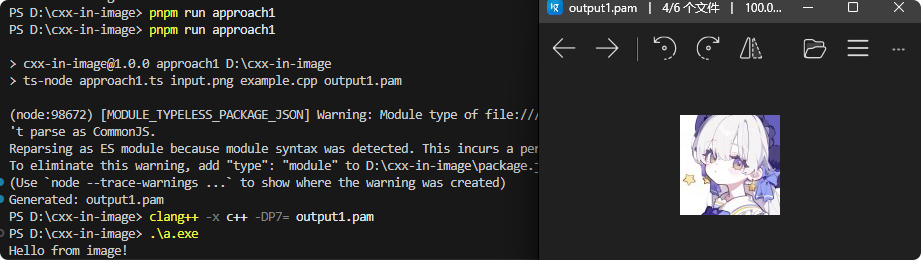
可以看到,我们成功获得了一张既可以编译,又可以查看的图片!
Approch 2
我们也可以把源码塞进图片数据;感觉这种方式的可玩性更高一些,应该可以通过某种算法实现把源码均匀的隐写在所有 bytes 里面,不过为了实现简单,我直接做成覆盖最后几个 bytes 了:
import * as fs from 'fs';
import { PNG } from 'pngjs';
function createPolyglot2(imagePath: string, cppCode: string, outputPath: string) {
const imageData = fs.readFileSync(imagePath);
const png = PNG.sync.read(imageData);
const width = png.width;
const height = png.height;
const hasAlpha = png.data.length === width * height * 4;
const depth = hasAlpha ? 4 : 3;
const bytesPerPixel = depth;
const totalBytes = width * height * bytesPerPixel;
const header = `P7
#if 0
WIDTH ${width}
HEIGHT ${height}
DEPTH ${depth}
MAXVAL 255
TUPLTYPE ${hasAlpha ? 'RGB_ALPHA' : 'RGB'}
ENDHDR
`;
const imageBytes = Buffer.alloc(totalBytes);
for (let i = 0; i < width * height; i++) {
for (let j = 0; j < bytesPerPixel; j++) {
imageBytes[i * bytesPerPixel + j] = png.data[i * 4 + j];
}
}
const codeSection = `\n#endif\n${cppCode}\n/*`;
const codeSectionBytes = Buffer.from(codeSection);
const closingComment = Buffer.from('*/');
const codeLen = codeSectionBytes.length + closingComment.length;
if (codeLen > totalBytes) {
throw new Error('C++ code too long for image size');
}
const bodyBytes = Buffer.alloc(totalBytes);
imageBytes.copy(bodyBytes, 0);
codeSectionBytes.copy(bodyBytes, totalBytes - codeLen);
closingComment.copy(bodyBytes, totalBytes - closingComment.length);
const output = Buffer.concat([Buffer.from(header), bodyBytes]);
fs.writeFileSync(outputPath, output);
console.log(`Generated: ${outputPath}`);
}
const imagePath = process.argv[2] || 'input.png';
const cppPath = process.argv[3] || 'input.cpp';
const outputPath = process.argv[4] || 'output2.pam';
const cppCode = fs.readFileSync(cppPath, 'utf-8');
createPolyglot2(imagePath, cppCode, outputPath);
效果也是一样的。不过可以看到图片的最后一节有一块黑点,那就是代码的数据: 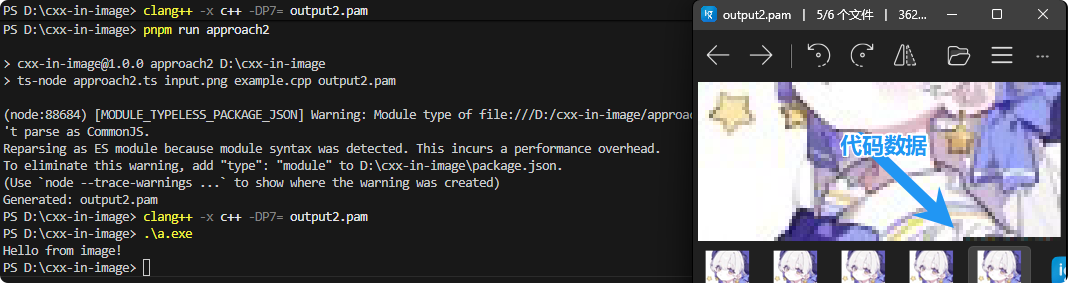
Summary
可以看出,“一个既可以编译又可以打开看的图片”确实是可行的,虽然我也不知道为什么我要研究这个。
或许日后可以整点 CTF 题,把图片做成可以编译的来隐写,就看谁能想到了(笑