IoT安全- Intel 酷睿 CPU Management Engine 固件研究与分析逆向 (一) 前置准备与解包
推荐 原创【IoT安全- Intel 酷睿 CPU Management Engine 固件研究与分析逆向 (一) 前置准备与解包】此文章归类为:IoT安全。
前言
此帖是记录笔者研究Intel Management Engine 以及 Intel-SA-00086 安全漏洞的记录笔记。笔者也不知道能研究多深入,所以研究一点是一点,顺便发出来也给各位大佬参考以及讨论。(也是下班给自己找点事做,上班一直做Agent开发太无聊了)
平台选择与前置准备
基于之前Kaokao那篇文章(具体可以去看github或者其他平台由相关参考)。Github仓公开爆料的是TXE平台,并没有我们常规的酷睿平台。由于在国内外网站没找到一模一样的硬件并且Intel和华硕官网都找不到相关硬件的固件和资料想要复现极难。
我的平台的选择:
主板:华硕 Rog Z370 -F Game
Cpu:i7 8700k
Management Engine 版本:11.7.4 (根据Intel-SA-00086 说明影响最后一个版本是 11.8.50.3399)
CH341A Pro编程器(华硕有8Ping接口可以不用买夹子)
线缆:Usb3.0 A to A 线 或 Intel SVT DCI DbC2/3 A-to-A
展示一下我的硬件平台实验台:

AMD散热器散热Intel CPU HHH:

Dump Bios
CH341A Pro编程器组装:

抬起拉杆把转接器按照顺序插入最后压下压杆就行了,非常简单。
找到SPI芯片接口
首先我们需要找到SPI芯片,并且Dump当前Bios中的数据。

这里需要注意的是,如果是华硕的主板是自带8PING接口的,所以可以直接使用转8Pin线来dump。如果是其他匹配则需要夹子夹在主板上。华硕主板接口顺序0号位是有一个白色角的,这一点要注意别接反了烧。

主板Bios Dci解锁
使用我们的NeoProgrammer工具Dump下来我们的文件
点击这个位置进行时保存就可以保存
Bios解包
首先我们需要对dump数据进行解包,并且拿到我们的bios分区。在主板中并没有开启DCI接口的选项,所以我们需要通过魔改Bios来做到。
首先根据 Intel SPI Flash 规范可以写一个检查脚本。规范可以查询文档:Intel® 100 Series and Intel® C230
Series Chipset Family Platform Controller Hub (PCH)。这里我用AI和我自己写的PDF MCP 让AI扫描了一下快速了解了一下内存布局。
┌─────────────────────┬───────────┬──────────────────────────────────────────────────────┐
│ 字段 │ 偏移 │ 内容 │
├─────────────────────┼───────────┼──────────────────────────────────────────────────────┤
│ FD Signature │ 0x10 │ 固定 4 字节 5A A5 F0 0F │
├─────────────────────┼───────────┼──────────────────────────────────────────────────────┤
│ FLMAP0 │ 0x14 │ 中间字节 << 4 = FRBA(Region 表偏移) │
├─────────────────────┼───────────┼──────────────────────────────────────────────────────┤
│ Region Table (FRBA) │ 通常 0x40 │ 5 条 ×4 字节,分别描述 FD / BIOS / ME / GbE / PDR 区 │
└─────────────────────┴───────────┴──────────────────────────────────────────────────────┘
整理一下就如上表格,主要有魔术字段和FLMAP0偏移以及Region Table组成。有这些才能把Bios从Bin中切出来。
解析一下拷贝出来的固件:
魔术字:
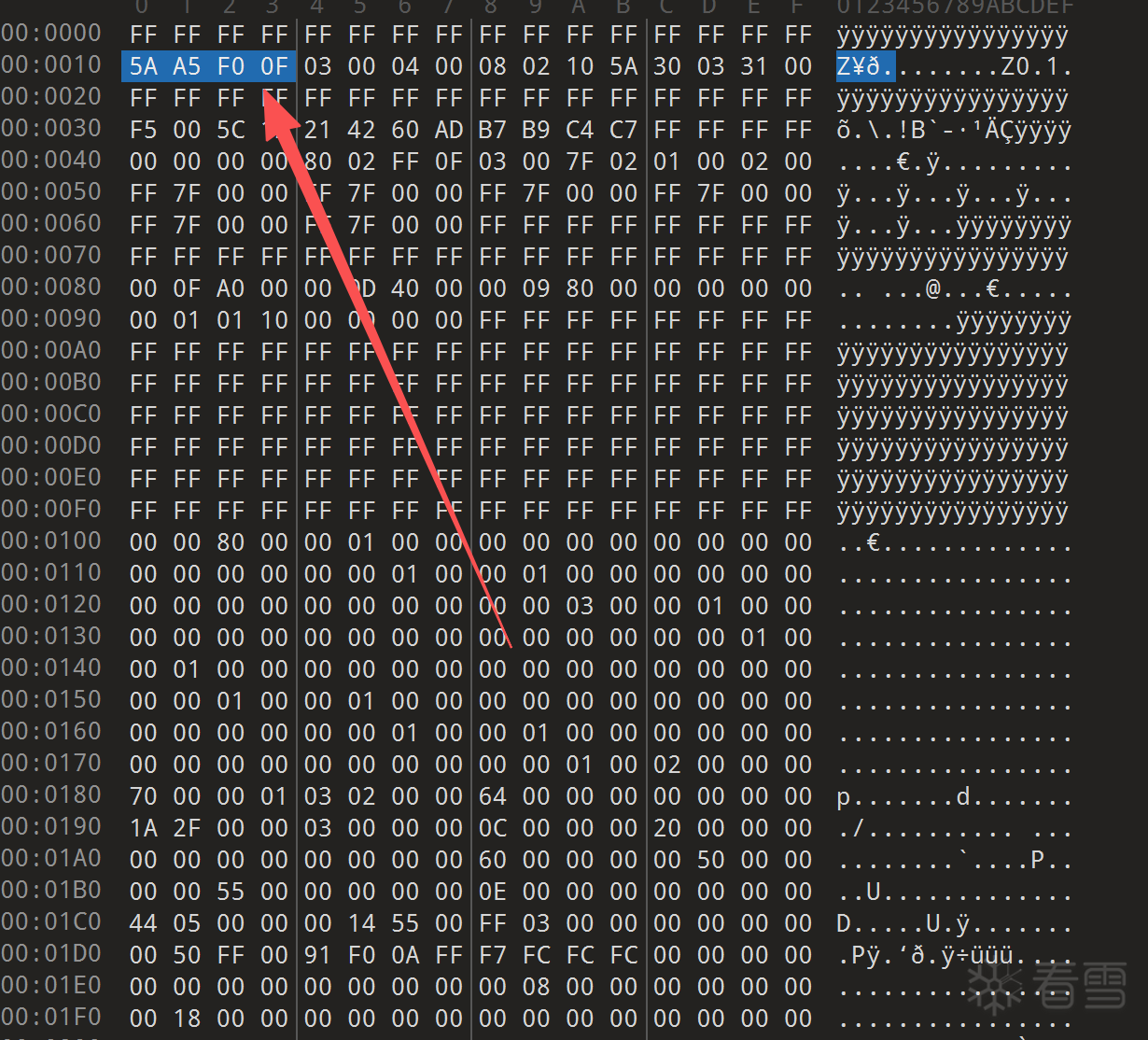
FLMAP0:

说一下如何解析:
00 04 00 03
注意这个04实际上就是Offset指向 Region Table表。算法就是 0x04 << 4 = 0x40

根据顺序来说第一个是FD,从00开始,第二个是Bios区域,第三个是ME, 第四个是GbE。在白皮书中可以找到对应的解释:
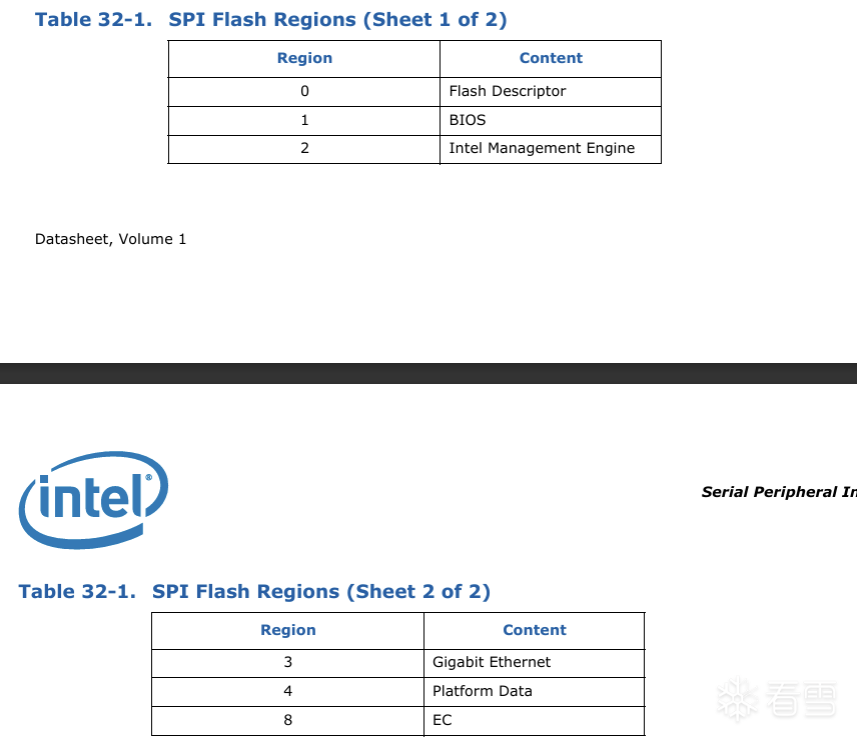
Region Table 解析规则如下:
base_enc = 0x0280 << 12
limit_enc = 0x0FFF << 12 OR 0xFFF
所以地址就是0X280000,范围是 0XFFFFFF:
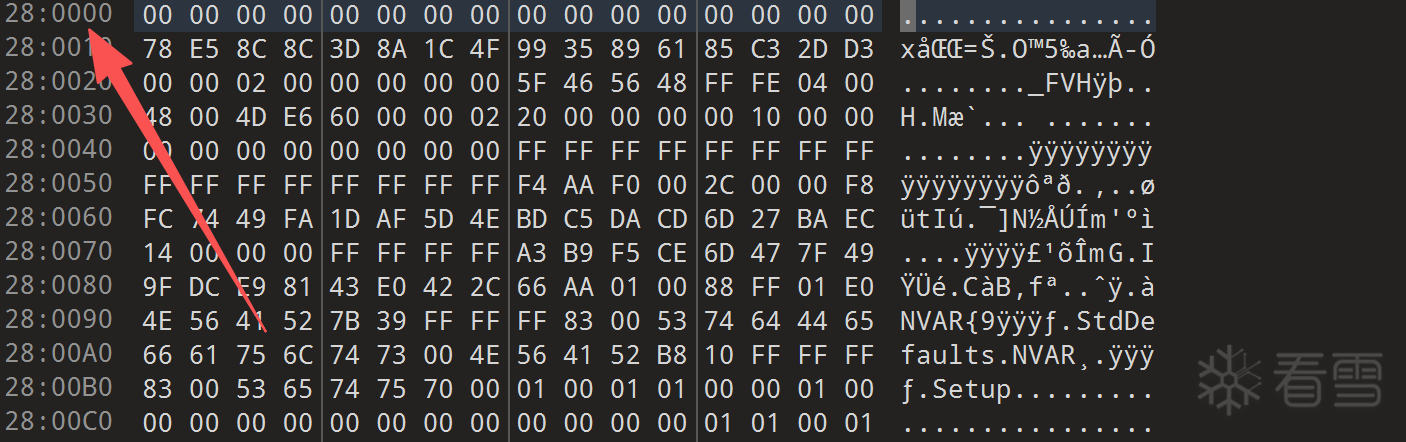
接下来使用 uefi-firmware-parser 将 我们的固件进行解包,注意是整个固件,不需要手动切块:
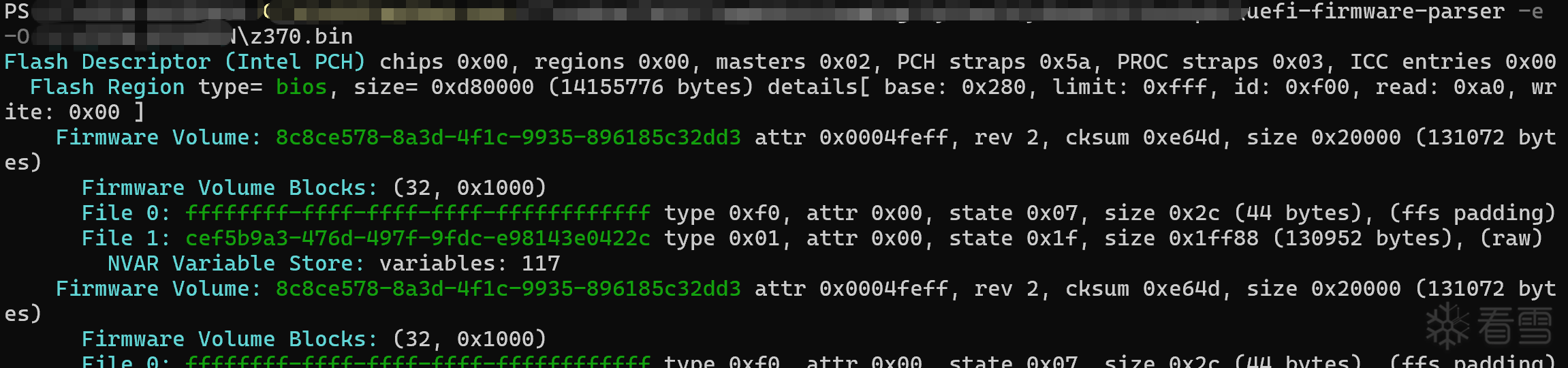

ME和Bios区:
FFS介绍:
SPI Flash 物理芯片
└── Region 1 = BIOS 区 (我们关心的部分, 13.5MB)
└── Firmware Volume (FV) ← UEFI 标准的容器格式, 一个 BIOS 区可能有多个 FV
└── Firmware File (FFS) ← FV 里的"文件"
└── Section (节) ← FFS 里再分若干节, 可能有压缩
└── PE32 代码 / 数据 / IFR / 字符串 ...
解包出来就是这个:
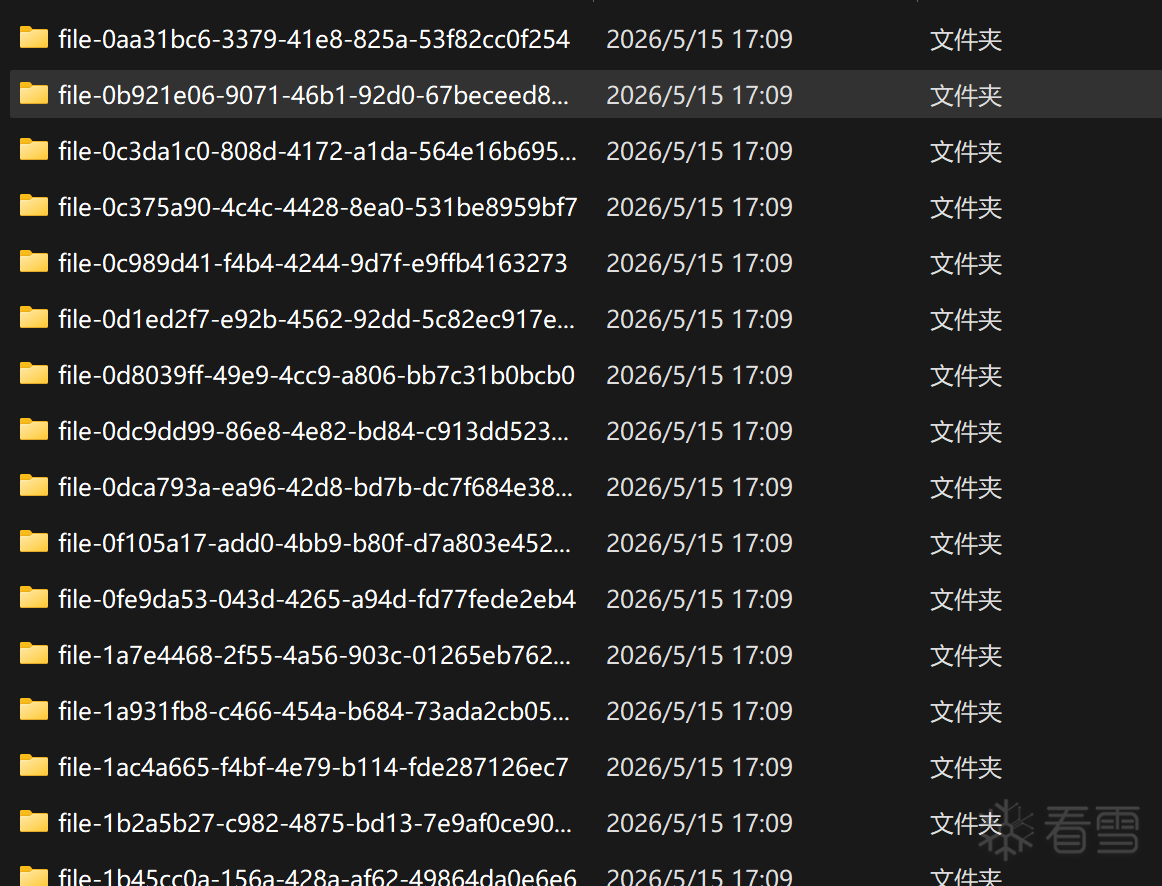
FFS的命名是GUID标注,也就是不同厂家里面的GUID都是一样的属于标准了。FFS说白了就是Bios的各种模块的标准,主板厂太多了,标准必须要统一。
899407d7-99fe-43d8-9a21-79ec328cac21 这个GUID 是 AMI Setup FFS的,我们需要的DCI的选项就在这个里面。
AMI FFS结构如下:
file-899407d7-.../
├── file.obj ← FFS 原始内容 (含 24B FFS header)
├── section0.dxe.depex ← Section 0: DXE 依赖描述
├── section1.guid ← Section 1 的 GUID (告诉你 section1 用什么算法封装)
├── section1/ ← Section 1 解开后的子目录
│ ├── guided.certs
│ ├── guided.preamble
│ ├── section0.pe ← 解出来的 PE32 (1.4MB)
│ └── section1.version
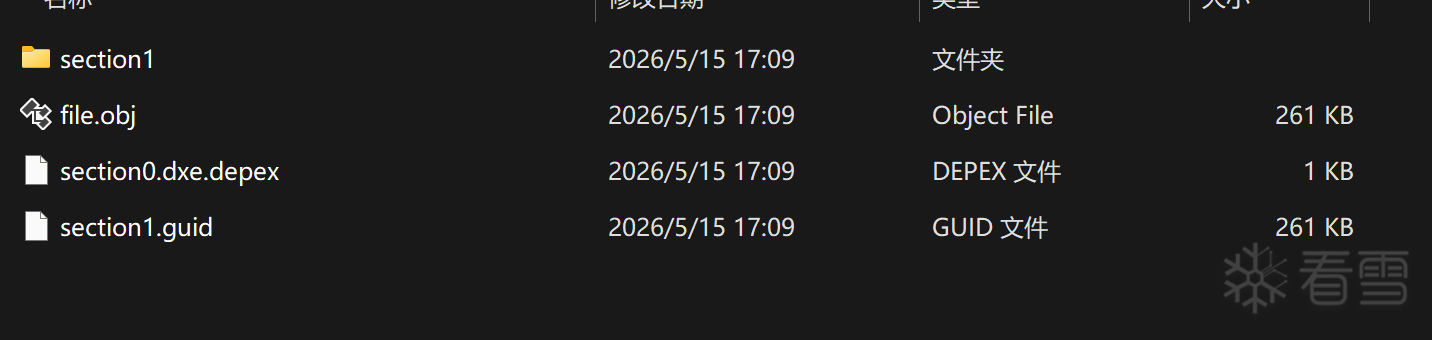
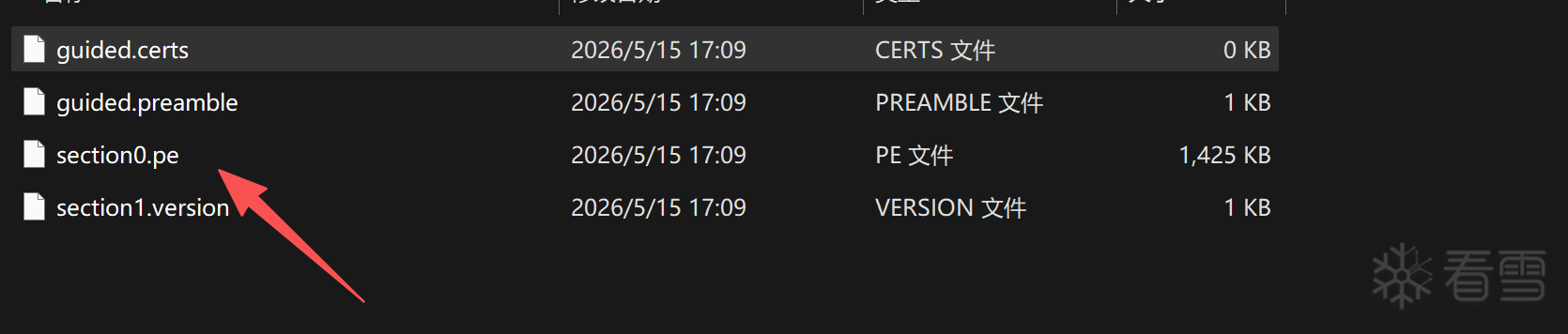
FFS 里有 2 个 section:
| Section | 类型 | 内容 |
|---|---|---|
| section0 | DXE Dependency Expression | 一段几字节的小数据,告诉 BIOS "我这个 Setup 模块依赖 PCH_INIT 完成后才能加载"。 |
| section1 | GUID-Defined Section | 这里是个被特定 GUID 算法 压缩的容器,里面又套了一层 PE32 |
核心实际上就是这个:section0.pe
标准的4D5A PE头。
section0.pe (1.4MB)
├── PE Header ← 标准 PE 头
├── .text 段 ← Setup 模块的 x86 机器码 (BIOS 启动时跑的)
├── .data / .rdata 段 ← 静态数据
└── HII Resource 区 ← 重点
├── HII Package List Header
├── String Package (类型 0x04) ← 8000+ 个菜单字符串
└── Forms Package (类型 0x02) ← 4000+ 个 IFR Question 定义
我们的核心就是解析 String Package 和 Forms Package 并且将他们映射起来,就能找到我们想要的开关。
解析所有字符串找到和DCI有关系的字符串:
这里就让Ai给我写了一个解析脚本:
import re, struct, json, sys, io, os
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace')
SETUP_PE = r'D:\Z370_DICOPEN\z370.bin_output\regions\region-bios\volume-0\file-899407d7-99fe-43d8-9a21-79ec328cac21\section1\section0.pe'
OUTPUT_JSON = r'D:\Z370_DICOPEN\setup_strings.json'
if not os.path.isfile(SETUP_PE):
print(f"[ERR] Setup PE not found: {SETUP_PE}")
print("Did you run uefi-firmware-parser on z370.bin yet?")
sys.exit(1)
blob = open(SETUP_PE, 'rb').read()
print(f"PE32 size: {len(blob)} bytes ({len(blob)/1024:.1f} KB)")
# --- Step 1: Locate HII String Package ---
# Strategy: scan for ASCII "en-US\0", back up 46 bytes to find package header start.
# Package header (after 4-byte common header):
# HdrSize (4B), StringInfoOffset (4B), LanguageWindow (32B), LanguageName StringId (2B), Language ASCII null-term
# So Language ASCII starts at package_start + 46.
print("\n[Step 1] Locate HII String Package (type 0x04) via 'en-US\\0' marker")
candidates = []
for m in re.finditer(rb'en-US\x00', blob):
p = m.start()
cand = p - 46
if cand < 0: continue
plen = int.from_bytes(blob[cand:cand+3], 'little')
ptype = blob[cand+3]
if ptype != 0x04: continue # 0x04 = Strings package
if not (0x80 <= plen <= 0x800000): continue
hdr_sz = struct.unpack('<I', blob[cand+4:cand+8])[0]
info_off = struct.unpack('<I', blob[cand+8:cand+12])[0]
candidates.append((cand, plen, hdr_sz, info_off))
if not candidates:
print("[ERR] no HII string package found")
sys.exit(1)
for c in candidates:
print(f" candidate @ blob_offset=0x{c[0]:x} pkg_len=0x{c[1]:x} HdrSize={c[2]} InfoOffset=0x{c[3]:x}")
# Use the first/largest candidate
sp, splen, hdr_sz, info_off = candidates[0]
print(f"\n[Step 2] Parsing SIBT blocks from package @ 0x{sp:x}")
# --- Step 2: Parse SIBT blocks ---
# SIBT block types (UEFI Spec ch 33):
# 0x00 END
# 0x14 STRING_UCS2 (1B type + UCS2 nul-term)
# 0x16 STRINGS_UCS2 (1B type + 2B count + count of UCS2 nul-term)
# 0x20 DUPLICATE (1B type + 2B StringId reference)
# 0x21 SKIP2 (1B type + 2B count)
# 0x22 SKIP1 (1B type + 1B count)
# 0x30 EXT1 (1B type + 1B subtype + 1B length)
# 0x31 EXT2 (1B type + 1B subtype + 2B length)
# 0x32 EXT4 (1B type + 1B subtype + 4B length)
# 0x40 FONT (1B type + 4B size + font data)
p = sp + info_off
end = sp + splen
strings = {}
sid = 1 # StringId starts at 1, 0 is reserved
while p < end:
t = blob[p]
if t == 0x00:
break
elif t == 0x14: # SIBT_STRING_UCS2
s_start = p + 1
s_end = s_start
while s_end + 1 < end and blob[s_end:s_end+2] != b'\x00\x00':
s_end += 2
strings[sid] = blob[s_start:s_end].decode('utf-16-le', errors='replace')
sid += 1
p = s_end + 2
elif t == 0x16: # SIBT_STRINGS_UCS2
cnt = struct.unpack('<H', blob[p+1:p+3])[0]
p += 3
for _ in range(cnt):
s_end = p
while s_end + 1 < end and blob[s_end:s_end+2] != b'\x00\x00':
s_end += 2
strings[sid] = blob[p:s_end].decode('utf-16-le', errors='replace')
sid += 1
p = s_end + 2
elif t == 0x20: # SIBT_DUPLICATE
ref = struct.unpack('<H', blob[p+1:p+3])[0]
strings[sid] = strings.get(ref, '?dup?')
sid += 1
p += 3
elif t == 0x21: # SIBT_SKIP2
sid += struct.unpack('<H', blob[p+1:p+3])[0]
p += 3
elif t == 0x22: # SIBT_SKIP1
sid += blob[p+1]
p += 2
elif t == 0x30: # EXT1
p += blob[p+2]
elif t == 0x31: # EXT2
p += struct.unpack('<H', blob[p+2:p+4])[0]
elif t == 0x32: # EXT4
p += struct.unpack('<I', blob[p+2:p+6])[0]
elif t == 0x40: # FONT
p += struct.unpack('<I', blob[p+1:p+5])[0]
else:
print(f"[WARN] unknown SIBT type {t:#x} @ 0x{p:x}")
break
print(f" parsed {len(strings)} strings, last StringId = {sid-1}")
# --- Step 3: Find DCI-related StringIds ---
print("\n[Step 3] Searching for DCI / Debug menu strings")
KEYWORDS = ['DCI enable', 'Direct Connect', 'Debug Interface', 'JTAG C10', 'HDCIEN',
'Platform Debug', 'Debug Consent']
found = []
for sid, txt in strings.items():
if any(kw in txt for kw in KEYWORDS):
found.append((sid, txt))
print(f" found {len(found)} DCI/debug-related strings:")
for sid, txt in found:
safe = ''.join(c if c.isascii() and c.isprintable() else '.' for c in txt)
print(f" StringId = 0x{sid:04X} ({sid:>4}) '{safe[:80]}'")
# --- Step 4: Save full map ---
with open(OUTPUT_JSON, 'w', encoding='utf-8') as f:
json.dump(strings, f, ensure_ascii=False)
print(f"\nSaved {len(strings)} strings → {OUTPUT_JSON}")
找到对应的dci的偏移值:
import re, struct, json, sys, io, os
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace')
SETUP_PE = r'D:\Z370_DICOPEN\z370.bin_output\regions\region-bios\volume-0\file-899407d7-99fe-43d8-9a21-79ec328cac21\section1\section0.pe'
STRINGS_JSON = r'D:\Z370_DICOPEN\setup_strings.json'
OUTPUT_JSON = r'D:\Z370_DICOPEN\all_questions.json'
if not os.path.isfile(SETUP_PE):
print(f"[ERR] need {SETUP_PE}"); sys.exit(1)
if not os.path.isfile(STRINGS_JSON):
print(f"[ERR] run phase3 first to produce {STRINGS_JSON}"); sys.exit(1)
blob = open(SETUP_PE, 'rb').read()
strings = {int(k):v for k,v in json.load(open(STRINGS_JSON, encoding='utf-8')).items()}
print(f"PE32 size: {len(blob)} bytes, {len(strings)} strings loaded")
# --- Step 1: Locate Forms Package (type 0x02) ---
# Header: 4 bytes -- 3B length + 1B type=0x02
# Right after header should be a FormSet opcode (0x0E).
print("\n[Step 1] Locate Forms Package (type 0x02)")
forms_pkgs = []
for i in range(0, len(blob) - 32):
plen = int.from_bytes(blob[i:i+3], 'little')
ptype = blob[i+3]
if ptype != 0x02: continue
if plen < 0x100 or plen > 0x800000: continue
if blob[i+4] == 0x0E and blob[i+5] >= 0x18 and i+plen <= len(blob):
forms_pkgs.append((i, plen))
for fp in forms_pkgs:
print(f" candidate @ 0x{fp[0]:x}, length 0x{fp[1]:x}")
if not forms_pkgs:
print("[ERR] no forms package found"); sys.exit(1)
fp_pos, fp_len = max(forms_pkgs, key=lambda x: x[1])
print(f"using Forms package @ 0x{fp_pos:x} (length 0x{fp_len:x})")
# --- Step 2: Walk IFR opcodes ---
print("\n[Step 2] Walk IFR opcode stream (with 7-bit length masking)")
OP_NAMES = {0x01:'Form',0x05:'OneOf',0x06:'CheckBox',0x07:'Numeric',0x09:'OneOfOpt',
0x0A:'SuppressIf',0x0E:'FormSet',0x19:'GrayOutIf',0x1E:'DisableIf',
0x23:'OrderedList',0x24:'VarStore',0x29:'End',0x5A:'Default'}
varstores = {}
questions = []
form_stack = []
p = fp_pos + 4 # skip 4-byte package header
end = fp_pos + fp_len
while p < end:
if p + 2 > len(blob): break
op = blob[p]
raw_len = blob[p+1]
ln = raw_len & 0x7F # <-- critical
scope = (raw_len >> 7) & 1
if ln < 2: break
body = blob[p+2:p+ln]
if op == 0x24: # VarStore
guid = body[:16].hex()
vsid = struct.unpack('<H', body[16:18])[0]
vsz = struct.unpack('<H', body[18:20])[0]
ne = body.find(b'\x00', 20)
nm = body[20:ne].decode('ascii','replace') if ne>=0 else '?'
varstores[vsid] = {'name':nm, 'size':vsz, 'guid':guid}
elif op == 0x01: # Form
fid = struct.unpack('<H', body[:2])[0]
ttl = struct.unpack('<H', body[2:4])[0]
form_stack.append({'fid':fid, 'title':strings.get(ttl,'?')})
elif op in (0x05, 0x06, 0x07, 0x23):
# Question: prompt(2) help(2) qid(2) vsid(2) voff(2) flags(1)
if len(body) >= 11:
prompt = struct.unpack('<H', body[0:2])[0]
help_ = struct.unpack('<H', body[2:4])[0]
qid = struct.unpack('<H', body[4:6])[0]
vsid = struct.unpack('<H', body[6:8])[0]
voff = struct.unpack('<H', body[8:10])[0]
flags = body[10]
questions.append({
'op': op, 'opname': OP_NAMES.get(op,'?'),
'prompt': prompt, 'help': help_, 'qid': qid,
'vsid': vsid, 'voff': voff, 'flags': flags,
'len': ln, 'pos': p,
'form': form_stack[-1]['title'] if form_stack else None,
})
elif op == 0x29 and form_stack: # End closes form scope
form_stack.pop()
p += ln
print(f" walked OK: {len(varstores)} VarStores, {len(questions)} Questions")
# --- Step 3: Show key VarStores (especially Setup) ---
print("\n[Step 3] VarStores discovered (showing first 10)")
for vsid, vs in sorted(varstores.items())[:10]:
print(f" VsId=0x{vsid:04X} name={vs['name']!r:30s} size={vs['size']:>5} guid={vs['guid'][:16]}...")
# --- Step 4: Find Questions referencing our target StringIds ---
print("\n[Step 4] Match Questions to DCI/Debug menu StringIds")
TARGETS = {
0x07BE: 'DCI enable (HDCIEN)',
0x033D: 'Debug Interface',
0x033F: 'Debug Interface Lock',
0x019C: 'JTAG C10 Power',
}
print(f"{'Target StringId':<16} {'Menu Text':<28} {'VsId':<8} {'VarOffset':<15} {'Form'}")
print('-'*100)
for sid, name in TARGETS.items():
matches = [q for q in questions if q['prompt'] == sid]
for q in matches:
vs = varstores.get(q['vsid'], {'name':'?'})
print(f" 0x{sid:04X} {name:<28} VsId=0x{q['vsid']:x} 0x{q['voff']:04X} ({q['voff']:>4}) {q['form']}")
# Save all questions for Phase 5
with open(OUTPUT_JSON, 'w', encoding='utf-8') as f:
json.dump(questions, f, ensure_ascii=False)
print(f"\nSaved {len(questions)} questions → {OUTPUT_JSON}")
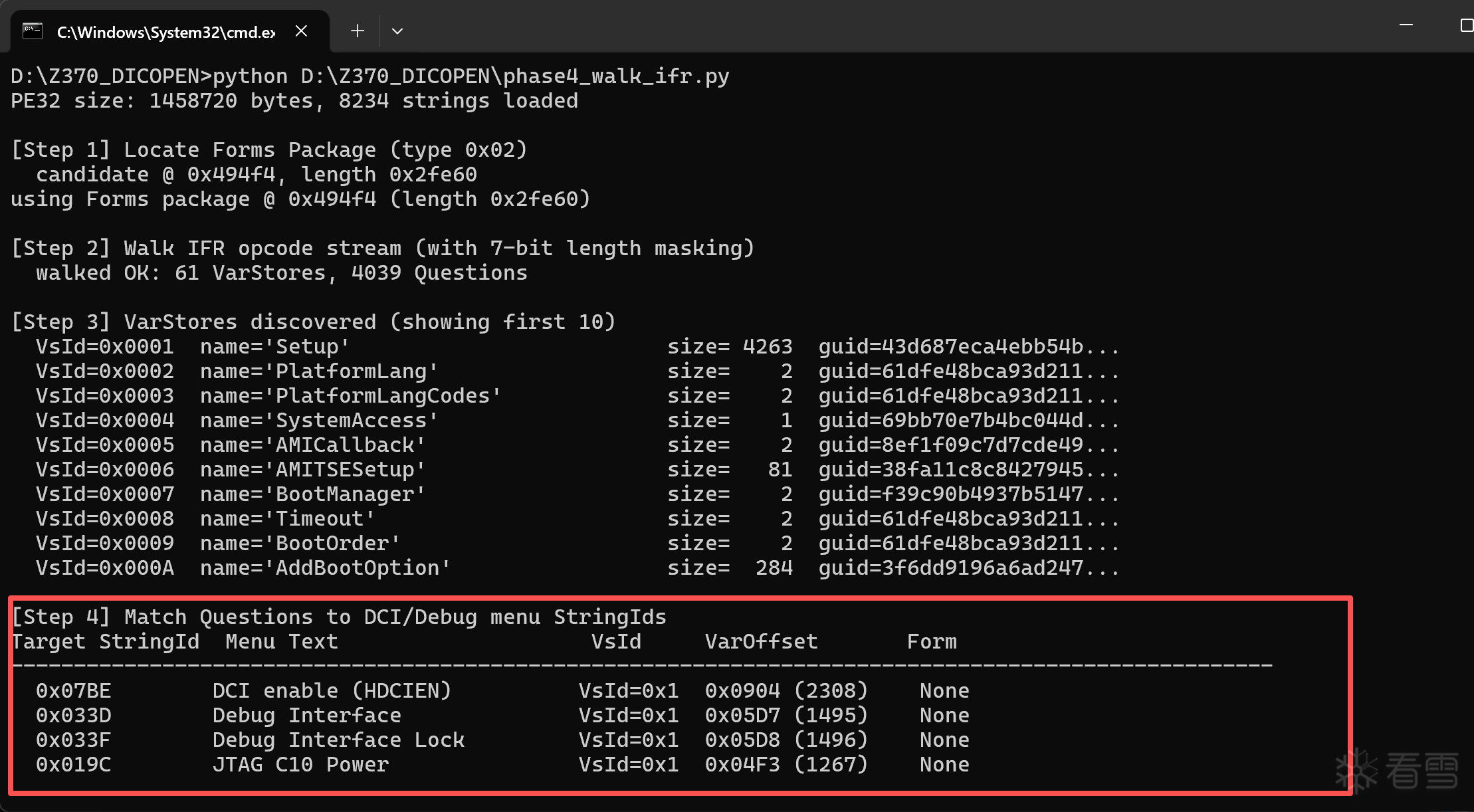
具体如何解析的可以看代码。
接下来就需要找到 0x904 在哪,这个解析出来的不是 文件office,是NVRAM容器格式的偏移。
NVRAM 容器的Guid是: cef5b9a3-476d-497f-9fdc-e98143e0422c。而我们需要修改的是他出厂的默认设置:
NVRAM 容器
└── NVAR 记录 "StdDefaults" (14715 字节) ← 包所有 Setup 变量的出厂默认值
└── 嵌套 NVAR "Setup" (4263 字节) ← 我们的 Setup 变量默认值就这里
└── 这 4263 字节里第 0x904 个就是 DciEn 字节
首先需要解析 AMI NVAR 的私有格式。好在通过Ai搜寻 UEFITool 源码中是有参考的。这里写了一个脚本来寻找并且Patch一下:
解析代码如下:
import struct, sys, io, os
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8', errors='replace')
DUMP = r'D:\Z370_DICOPEN\z370.bin'
NVRAM_FFS = r'D:\Z370_DICOPEN\z370.bin_output\regions\region-bios\volume-0\file-cef5b9a3-476d-497f-9fdc-e98143e0422c\file.obj'
if not os.path.isfile(NVRAM_FFS):
print(f"[ERR] {NVRAM_FFS} not found — did uefi-firmware-parser finish?")
sys.exit(1)
blob = open(NVRAM_FFS, 'rb').read()
dump = open(DUMP, 'rb').read()
print(f"NVRAM FFS file.obj: {len(blob)} bytes")
print(f"Full dump z370.bin: {len(dump)} bytes")
# ---- AMI NVAR record format (community-reverse-engineered, no official doc) ----
# Header layout:
# +0..+3: Signature "NVAR" (4 bytes)
# +4..+5: Size (2 bytes, includes header + data)
# +6..+8: Next offset (3 bytes)
# +9: Attributes (1 byte)
# bit 0 (0x01) = Runtime
# bit 1 (0x02) = ASCII Name
# bit 2 (0x04) = Use GUID (instead of GuidIdx)
# bit 3 (0x08) = Data Only (no name, references previous)
# bit 4 (0x10) = Extended Header
# bit 7 (0x80) = Valid
# Then if NOT data-only:
# +10: GuidIdx (1 byte) OR GUID (16 bytes) if Attr.UseGuid
# +N.. Name (ASCII null-term, or UCS-2 if not Attr.AsciiName)
# Then data until +Size
def parse_nvar(buf, start, end):
"""Walk NVAR records, return list of dicts."""
records = []
p = start
while p < end:
if buf[p:p+4] != b'NVAR':
nxt = buf.find(b'NVAR', p+1, end)
if nxt < 0: break
p = nxt
continue
sz = struct.unpack('<H', buf[p+4:p+6])[0]
if sz < 12 or sz == 0xFFFF: break
attr = buf[p+9]
ASCII_NAME = bool(attr & 0x02)
USE_GUID = bool(attr & 0x04)
DATA_ONLY = bool(attr & 0x08)
cursor = p + 10
if DATA_ONLY:
name = '(data_only)'
else:
cursor += 16 if USE_GUID else 1
if ASCII_NAME:
ne = buf.find(b'\x00', cursor, p+sz)
name = buf[cursor:ne].decode('ascii','replace')
cursor = ne + 1
else:
ne = cursor
while ne+1 < p+sz and buf[ne:ne+2] != b'\x00\x00':
ne += 2
name = buf[cursor:ne].decode('utf-16-le','replace')
cursor = ne + 2
records.append({'pos':p, 'sz':sz, 'attr':attr, 'name':name,
'data_start':cursor, 'data_end':p+sz})
p = p + sz
return records
# --- Step 1: parse top-level NVARs in file.obj ---
print("\n[Step 1] Walk top-level NVAR records in NVRAM FFS")
tops = parse_nvar(blob, 0x18, len(blob))
for r in tops[:5]:
print(f" NVAR @ 0x{r['pos']:x} size=0x{r['sz']:x} name={r['name']!r}")
sd = next((r for r in tops if r['name'] == 'StdDefaults'), None)
if not sd:
print("[ERR] StdDefaults NVAR not found"); sys.exit(1)
print(f"\nStdDefaults found @ file.obj offset 0x{sd['pos']:x}")
print(f" data 0x{sd['data_start']:x} - 0x{sd['data_end']:x} ({sd['data_end']-sd['data_start']} bytes)")
# --- Step 2: parse INNER NVARs inside StdDefaults data ---
print("\n[Step 2] Walk INNER NVAR records inside StdDefaults")
inner = parse_nvar(blob, sd['data_start'], sd['data_end'])
print(f" found {len(inner)} inner records")
for r in inner[:5]:
print(f" {r['name']!r:30s} data_len={r['data_end']-r['data_start']}")
setup = next((r for r in inner if r['name'] == 'Setup'), None)
if not setup:
print("[ERR] inner 'Setup' NVAR not found"); sys.exit(1)
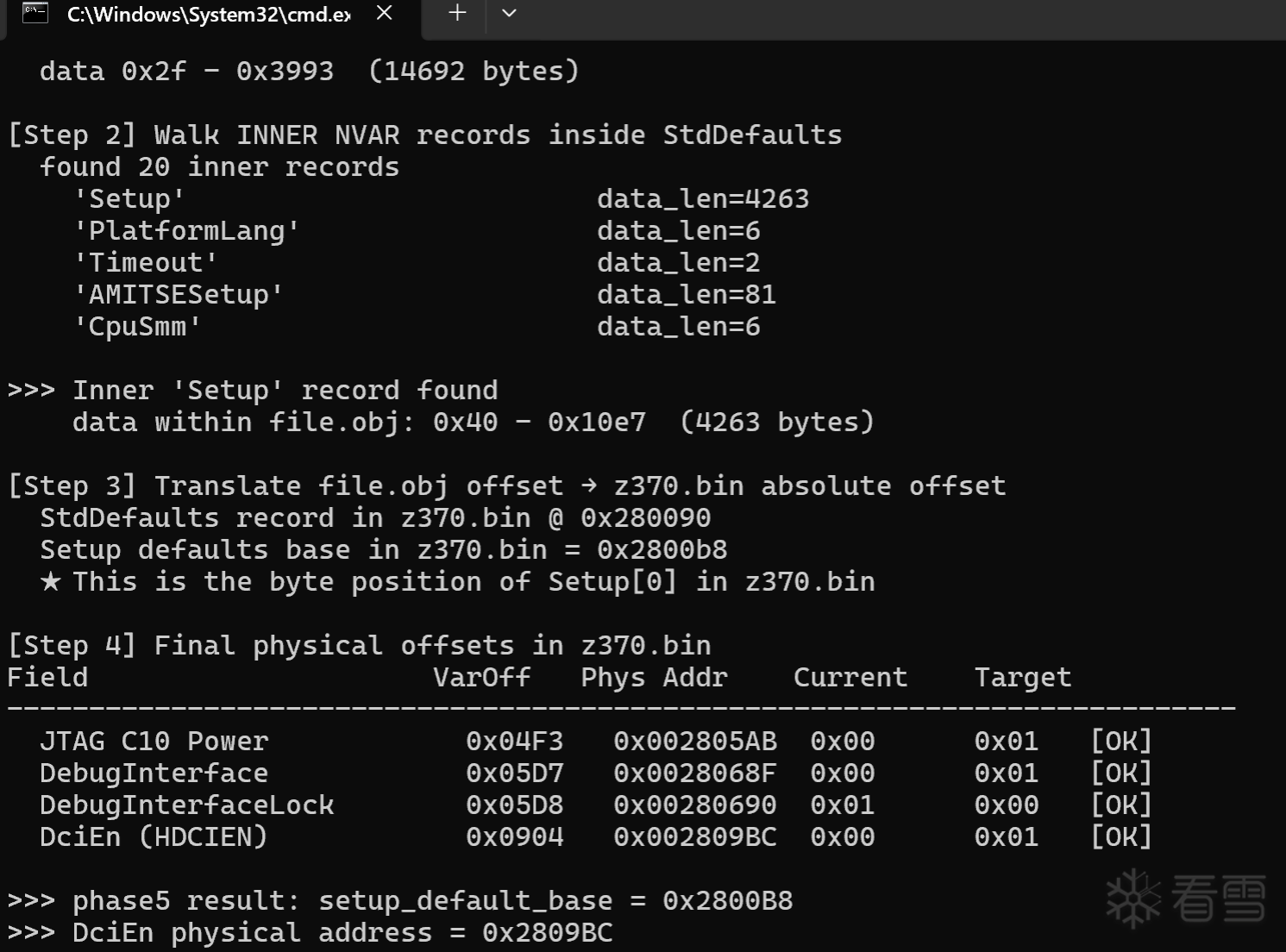
print(f"\n>>> Inner 'Setup' record found")
print(f" data within file.obj: 0x{setup['data_start']:x} - 0x{setup['data_end']:x} ({setup['data_end']-setup['data_start']} bytes)")
assert setup['data_end'] - setup['data_start'] == 4263, "Setup size mismatch"
# --- Step 3: translate file.obj offset → z370.bin absolute offset ---
print("\n[Step 3] Translate file.obj offset → z370.bin absolute offset")
# Strategy: find a fingerprint (40 bytes of StdDefaults record header) in z370.bin
fingerprint = blob[sd['pos']:sd['pos']+40]
abs_sd_pos = dump.find(fingerprint)
if abs_sd_pos < 0:
print("[ERR] cannot locate StdDefaults fingerprint in z370.bin")
sys.exit(1)
print(f" StdDefaults record in z370.bin @ 0x{abs_sd_pos:x}")
offset_within_sd = setup['data_start'] - sd['pos']
setup_default_base = abs_sd_pos + offset_within_sd
print(f" Setup defaults base in z370.bin = 0x{setup_default_base:x}")
print(f" ★ This is the byte position of Setup[0] in z370.bin")
# --- Step 4: compute physical patch addresses for each target ---
print("\n[Step 4] Final physical offsets in z370.bin")
TARGETS = [
(0x4F3, 'JTAG C10 Power', 0x00, 0x01),
(0x5D7, 'DebugInterface', 0x00, 0x01),
(0x5D8, 'DebugInterfaceLock', 0x01, 0x00), # unlock
(0x904, 'DciEn (HDCIEN)', 0x00, 0x01),
]
print(f"{'Field':<25} {'VarOff':<8} {'Phys Addr':<12} {'Current':<10} {'Target':<10}")
print('-' * 75)
for voff, name, expected_old, new_val in TARGETS:
phys = setup_default_base + voff
current = dump[phys]
mark = 'OK' if current == expected_old else 'MISMATCH'
print(f" {name:<25} 0x{voff:04X} 0x{phys:08X} 0x{current:02X} 0x{new_val:02X} [{mark}]")
print()
print(f">>> phase5 result: setup_default_base = 0x{setup_default_base:X}")
print(f">>> DciEn physical address = 0x{setup_default_base + 0x904:X}")
这里已经解析并且计算出真实的偏移是多少,由于NVRAM 容器是没有被压缩,就可以在对应文件中进行patch就完事了这里具体不展开了。
接下来就是刷入固件然后启动。到现在为止,我们才有资格调试ME.在KAOKAO中由于他那个设备是默认就开启了这些接口所以不需要任何Patch技术就可以解锁了。
刷入:
Usb线缆制作
两个方案:
- 直接买根调试线
- 购买一条公对公的线屏蔽部分触角来做到如图:

我之前是用的胶布缠住的会有点问题,插拔的时候就出问题了。
ME固件解包
因为uefi-firmware-parser 解包出来得缺少body(说白了切得时候少切了内容,这也是我遇到的一个坑)。我们需要使用UEFIExtract 进行解包:
body本身是压缩算法处理过的,这里写一个解密脚本用来解密一下body,代码如下:
def huffman_decompress(module_contents, compressed_size, decompressed_size, print_msg):
chunk_count = int(decompressed_size / CHUNK_SIZE)
header_size = chunk_count * 0x4
module_buffer = bytearray(module_contents)
header_buffer = module_buffer[0:header_size]
compressed_buffer = module_buffer[header_size:compressed_size]
decompressed_array = []
header_entries = struct.unpack('<{:d}I'.format(chunk_count), header_buffer)
start_offsets, flags = zip(*[(x & 0x1FFFFFF, (x >> 25) & 0x7F) for x in header_entries])
end_offsets = itertools.chain(start_offsets[1:], [compressed_size - header_size])
for index, dictionary_type, compressed_position, compressed_limit in zip(range(chunk_count), flags, start_offsets, end_offsets):
if print_msg == 'all' :
print('==Processing chunk 0x{:X} at compressed offset 0x{:X} with dictionary 0x{:X}=='.format(index, compressed_position, dictionary_type))
dictionary = HUFFMAN_SYMBOLS[dictionary_type]
decompressed_position, decompressed_limit = index * CHUNK_SIZE, (index + 1) * CHUNK_SIZE
bit_buffer = 0
available_bits = 0
while decompressed_position < decompressed_limit:
while available_bits <= 24 and compressed_position < compressed_limit:
bit_buffer = bit_buffer | compressed_buffer[compressed_position] << (24 - available_bits)
compressed_position = compressed_position + 1
available_bits = available_bits + 8
codeword_length, base_codeword = 0, 0
for length, shape, base in HUFFMAN_SHAPE:
if bit_buffer >= shape:
codeword_length, base_codeword = length, base
break
if available_bits >= codeword_length:
codeword = bit_buffer >> (32 - codeword_length)
bit_buffer = (bit_buffer << codeword_length) & 0xFFFFFFFF
available_bits = available_bits - codeword_length
symbol = dictionary[codeword_length][base_codeword - codeword]
symbol_length = len(symbol)
if decompressed_limit - decompressed_position >= symbol_length:
decompressed_array.extend(symbol)
decompressed_position += symbol_length
else:
# Shouldn't ever happen now that the dictionaries are complete
if print_msg in ['all','error'] :
print('Skipping overflowing codeword {: <15s} (dictionary 0x{:X}, codeword length {: >2d}, codeword {: >5s}, symbol length {:d}) at decompressed offset 0x{:X}'.format(
('{:0>' + str(codeword_length) + 'b}').format(codeword), dictionary_type, codeword_length, '0x{:X}'.format(codeword), symbol_length, decompressed_position))
filler = itertools.repeat(0x7F, decompressed_limit - decompressed_position)
decompressed_array.extend(filler)
decompressed_position = decompressed_limit
else:
# Shouldn't ever happen now that the dictionaries are complete
if print_msg in ['all','error'] :
print('Reached end of compressed stream early at decompressed offset 0x{:X}'.format(decompressed_position))
filler = itertools.repeat(0x7F, decompressed_limit - decompressed_position)
decompressed_array.extend(filler)
decompressed_position = decompressed_limit
return bytes(decompressed_array)
def main():
if len(sys.argv) in [5, 6] :
with open(sys.argv[1], 'rb') as file_input:
decompressed = huffman_decompress(file_input.read(), int(sys.argv[3], 0), int(sys.argv[4], 0), (sys.argv[5] if len(sys.argv) == 6 else 'all'))
with open(sys.argv[2], 'wb') as file_output:
file_output.write(decompressed)
else :
print('\nUsage: HuffmanDecompress <compressed file path> <decompressed file path> <compressed file size> <decompressed file size> <info all|error|none>')
print('\nExample: HuffmanDecompress bup.huff bup.mod 0x28E00 0x31000 all')
if __name__ == "__main__":
main()
字典参考:ceeK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6H3N6s2u0W2M7$3g2S2M7X3y4Z5i4K6u0r3N6h3&6y4c8e0p5I4 这个项目。
项目进展
这个项目实际上研究时间大概在一个月,并且中间烧掉了两块主板,包括文中写的这个8700k平台以及废掉了。写文章的时候是两周前,最近才把剩下的坑填完。也是在不停的价钱在咸鱼收集符合版本的设备。
感谢您看到这里了,如果你看到这里觉得好玩,或者对你有帮助请点个赞,有啥建议或者想说的可以留言,文章不做任何限制要求。
剧透
已经对ME的启动流程进行完整分析。从rbe -> bup.以及kaokao 所说的漏洞的定位(分析主要依靠我构建的ai并行逆向框架与手工校对,感兴趣可以看一下我其他的文章,感谢感谢)。

其实酷睿也存在一模一样的洞hhh,不仅仅是低功耗平台。
更多【IoT安全- Intel 酷睿 CPU Management Engine 固件研究与分析逆向 (一) 前置准备与解包】相关视频教程:www.yxfzedu.com
相关文章推荐
- 系统架构-垂直领域对话系统架构 - 其他
- python-pycharm pro v2023.2.4(Python编辑开发) - 其他
- 云原生-修炼k8s+flink+hdfs+dlink(七:flinkcdc) - 其他
- 算法-《深入浅出进阶篇》洛谷P4147 玉蟾宫——悬线法dp - 其他
- 接口隔离原则-ISP图像处理Pipeline - 其他
- 编程技术-WPF中Dispatcher对象的用途是什么 - 其他
- 学习-ARM & Linux 基础学习 / Ubuntu 下的包管理 / apt工具 - 其他
- 编程技术-【ROS】RViz2源码分析(一):介绍 - 其他
- 计算机视觉-Pytorch实战教程(五)-计算机视觉基础 - 其他
- 编程技术-【Java 进阶篇】JQuery 案例:qq表情选择,表达情感的小黄脸 - 其他
- java-Jenkins入门——安装docker版的Jenkins & 配置mvn,jdk等 & 使用案例初步 & 遇到的问题及解决 - 其他
- 学习-科研学习|科研软件——有序多分类Logistic回归的SPSS教程! - 其他
- 编程技术-如何在 Linux 上部署 RabbitMQ - 其他
- 编程技术-WPF路由事件 - 其他
- 算法-通信信道:无线信道中衰落的类型和分类 - 其他
- 编程技术-复杂度分析 - 其他
- 编程技术-ReentrantLock通过Condition实现锁对象的监视器功能 - 其他
- 编程技术-如何在3DMax中使用超过16个材质ID通道? - 其他
- 安全-OpenAtom OpenHarmony三方库创建发布及安全隐私检测 - 其他
- elasticsearch-Elasticsearch docker-compose 使用 Logstash 从 JSON 文件中预加载数据 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- CTF对抗-CSAW-CTF-Web部分题目
- CTF对抗-2022MT-CTF Re
- 编程技术-逆向IoRegisterPlugPlayNotification获取即插即用回调地址,配图加注释超级详细
- 软件逆向-针对百度旗下的一个会议软件,简单研究其CEF框架
- Android安全-逆向篇三:解决Flutter应用不能点击问题
- Android安全-Android - 系统级源码调试
- Android安全-逆向分析某软件sign算法
- 软件逆向-APT 双尾蝎样本分析
- 编程技术-利用GET请求从微软符号服务器下载PDB
- 编程技术-NtSocket的稳定实现,Client与Server的简单封装,以及SocketAsyncSelect的一种APC实现