算法-目标检测——OverFeat算法解读
推荐 原创论文:OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks
作者:Pierre Sermanet, David Eigen, Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun
链接:https://arxiv.org/abs/1312.6229
文章目录
1、算法概述
OverFeat算法同时实现图像分类、定位及检测任务,也证明了采用一个网络同时做三种任务可以提高分类、定位、检测的准确率。文章介绍了一种通过累积预测边界框来定位和检测的方法。通过结合许多定位预测,可以在没有背景样本训练的情况下进行检测任务,不进行背景训练也可以让网络只关注正面类,以获得更高的准确性。文中报道的结果是基于ILSVRC2013的,分类报道TOP5(分类概率前5个包含groundTruth就算正确);定位也是报道TOP5但是需加上TOP5各自对应目标的bounding box预测且bounding box与groundTruth矩形框标注的iou大于50%才能算bounding box预测正确;检测任务就需要预测图像中的每个目标了(类别加定位,包括背景类)并以mAP的指标报道结果。
2、OverFeat细节
2.1 分类
OverFeat仿照AlexNet设计,但是对网络结构和推理步骤进行了改进;文中分类网络分为两种:速度和精度,结构如下:
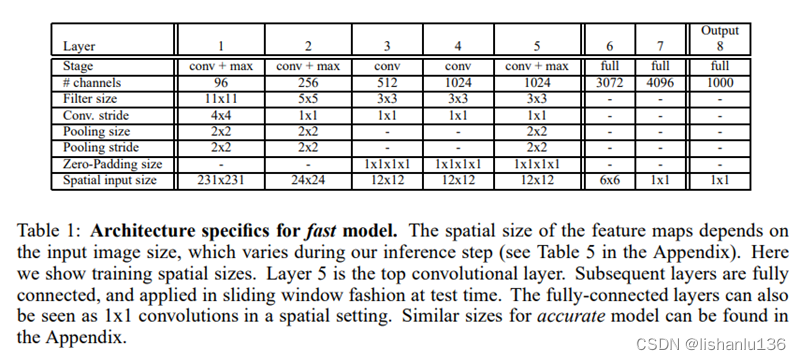
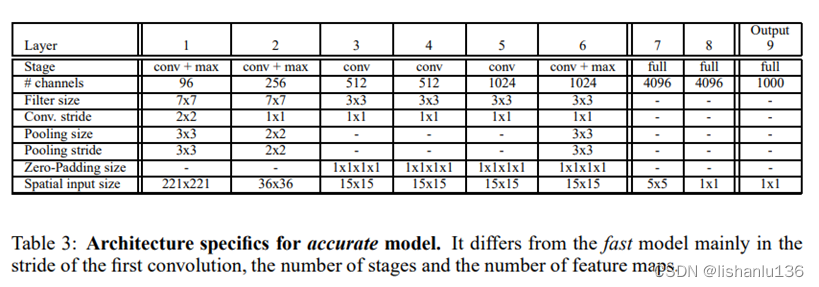
相对于AlexNet,它没有采用对比度归一化,没有用带重叠的池化层,网络前两层使用了小的stride从而保留了比较大的特征图,因为大的stride虽然能快速减小特征图从而对网络推理提速但是对精度有损害。最终精度模型比速度模型的TOP5错误率少了2.21%(14.18%对16.39%)。
- 多尺度分类
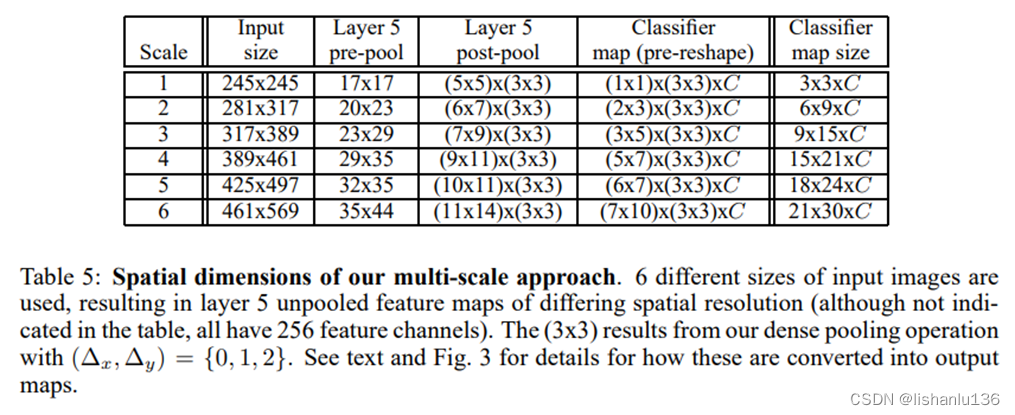
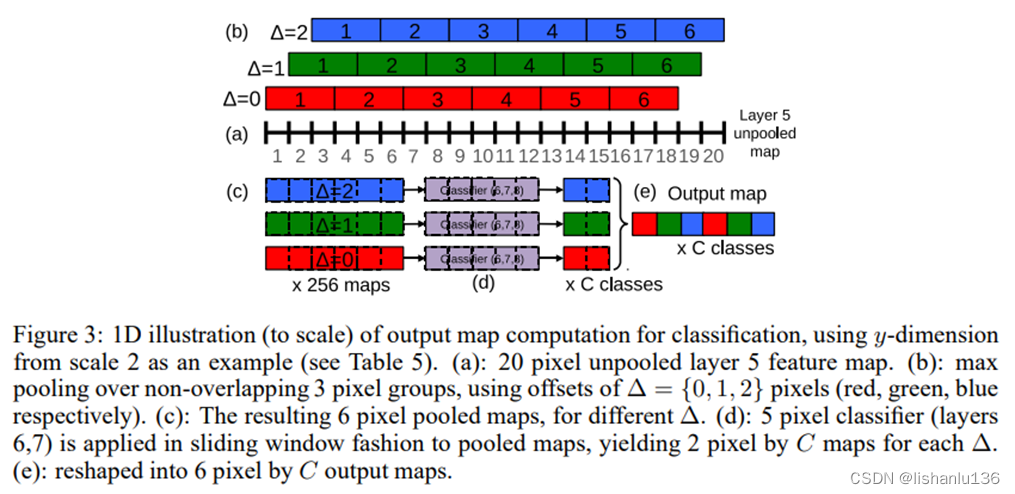
AlexNet中,应用了多视角(multi-view)投票技术用来提升最后预测类别的精度,即通过4次corner_crop加一次center_crop,同时应用水平翻转共计10次分类结果来投票出最终的类别;然而这种方式还是忽略了大量图片区域,也在图片重叠区域存在计算冗余,此外,这种方式也只是图片的单一尺度,不一定是卷积神经网络最合适的推理尺度。所以作者采用了6种不同尺度的测试图像作为输入(每个尺度图像还增加了水平翻转),而且作者认为在特征提取最后一层(conv 5)直接做 max pooling,将导致最终输入图像的检测粒度不足,提出用偏移池化(offset pooling)操作实现让分类器的视角窗口在特征图上滑动,最终将偏移池化得到的特征图组合在一起输出结果。如下表、下图所示:
- 卷积和高效的滑窗
在此之前,很多滑动窗口技术都是为每个窗口重复进行所有的计算,这对计算资源的消耗是巨大的。而卷积天然就带有滑窗的方式,如下图所示,因为卷积操作是共享卷积核滑动操作,所以计算非常高效,作者最后在测试阶段,将最后的全连接层替换成了1x1卷积层,这样就能适应比训练图像大的图片测试了。
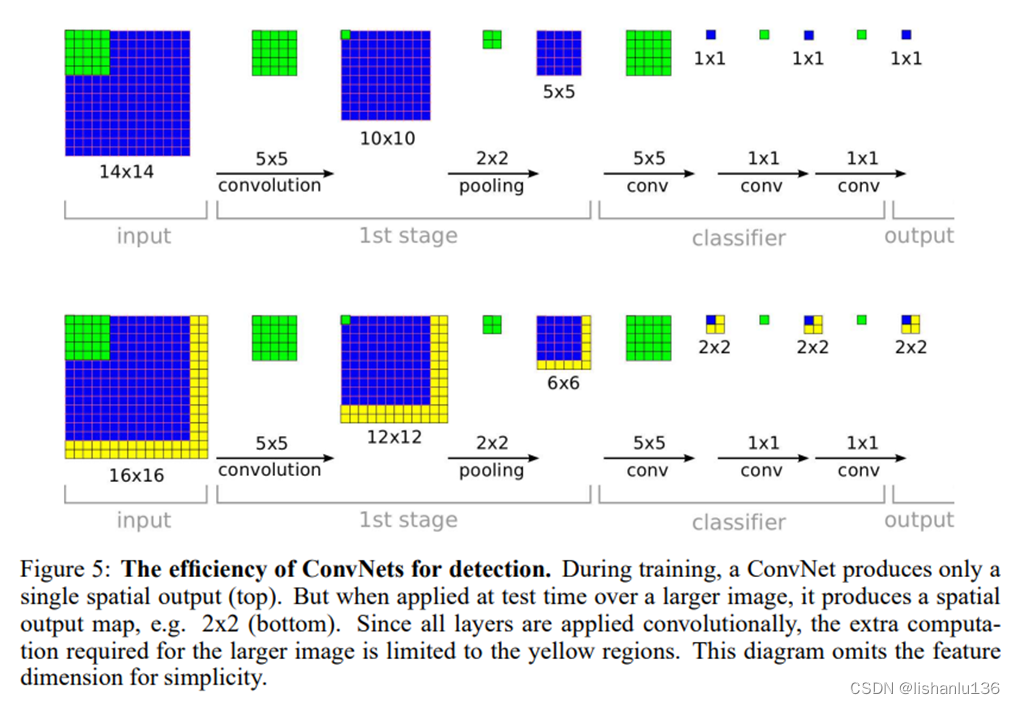
2.2 定位
由分类到定位,基于之前的分类网络,把网络的分类器替换成回归器,训练这个网络预测每个位置和尺度的物体边界框,就可以实现定位任务。回归器也取网络的前5层的feature map输出作为bounding box的输入,该feature map也用作分类器训练,所以分类器和回归器共用前面的特征。回归器的输出是4个值,代表bounding box的坐标,每个类都有对应的bounding box预测。训练回归器时,前5层不参与训练;如果样本和真实标签的重叠小于50%,则样本不参与回归器的训练。(由于样本预处理和增强的原因,可能导致样本的范围和真实标签已经重叠较小)。下面看看定位/检测具体的工作步骤:




3、创新点
采用multiscale、sliding window、offset pooling实现多尺度滑窗采样,基于卷积高效实现滑窗思想,在同一网络框架下实现分类、定位、检测。
更多【算法-目标检测——OverFeat算法解读】相关视频教程:www.yxfzedu.com
相关文章推荐
- java-Maven的总结 - 其他
- 学习-【Azure 架构师学习笔记】-Azure Storage Account(5)- Data Lake layers - 其他
- 人工智能-高校为什么需要大数据挖掘平台? - 其他
- 数码相机-立体相机标定 - 其他
- java-java计算 - 其他
- python-前端面试题 - 其他
- git-IntelliJ IDEA 2023.2.1 (Ultimate Edition) 版本 Git 如何合并多次的本地提交进行 Push - 其他
- 音视频-中文编程软件视频推荐,自学编程电脑推荐,中文编程开发语言工具下载 - 其他
- node.js-npm install:sill idealTree buildDeps - 其他
- 编辑器-vscode 访问本地或者远程docker环境 - 其他
- git-IntelliJ IDEA 2023.2.1 (Ultimate Edition) 版本 Git 如何找回被 Drop Commit 的提交记录 - 其他
- 算法-力扣第1035题 不相交的线中等 c++ (最长公共子序列) 动态规划 附Java代码 - 其他
- java-JavaWeb课程复习资料——idea创建JDBC - 其他
- python-Python---列表的循环遍历,嵌套 - 其他
- python-Python的版本如何查询? - 其他
- java-IDEA 函数下边出现红色的波浪线,提示报错 - 其他
- 算法-算法通关村第八关|白银|二叉树的深度和高度问题【持续更新】 - 其他
- 算法-C现代方法(第19章)笔记——程序设计 - 其他
- git-IntelliJ Idea 撤回git已经push的操作 - 其他
- c#-html导出word - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- r语言-gpt支持json格式的数据返回(response_format: ‘json_object‘)
- pdf-pdf.js不分页渲染(渲染完整内容)
- 自动驾驶-自动驾驶学习笔记(八)——路线规划
- pdf-Word转PDF简单示例,分别在windows和centos中完成转换
- spring boot-java 企业工程管理系统软件源码+Spring Cloud + Spring Boot +二次开发+ MybatisPlus + Redis
- python-利用 Google Artifact Repository 构建maven jar 存储仓库
- python-PyCharm因安装了illuminated Cloud插件导致加载项目失败
- list-list复制出新的list后修改元素,也更改了旧的list?
- 语言模型-论文导读 | 融合大规模语言模型与知识图谱的推理方法
- spring-springboot引入外部jar,package打包报错找不到程序包XXX