r语言-StarRocks——Stream Load 事务接口实现原理
推荐 原创目录
前言
StarRocks 支持通过 Stream Load 方式实时写入数据,为进一步提升导入效率,从 2.4 版本实现了新的事务接口,本文阐述Stream Load 事务接口实现原理
官网文章地址:
使用 Stream Load 事务接口导入 | StarRocks
一、StarRocks 数据导入
StarRocks丰富的导入方式为业务在报表推送、实时数据分析、数据湖分析等场景提供了助力。目前支持的四种数据导入方式,分别是 Stream Load, Broker Load, Routine Load,Spark Load。此外,为了支持和Flink、Kafka等其他系统之间实现跨系统的两阶段提交(预提交事务、提交事务),提升高并发Stream Load导入场景下的性能,StarRocks 自 2.4 版本起提供 Stream Load 事务接口。
二、StarRocks 事务写入原理
StarRocks事务写入基于典型的两阶段提交事务实现,客户端使用事务主要包含以下几个接口:
-
/api/transaction/begin:开启一个新事务。
- /api/transaction/prepare:预提交当前事务,临时持久化变更。预提交一个事务后,可以继续提交或者回滚该事务。在这种机制下,如果在事务预提交成功后StarRocks发生了宕机,仍然可以在系统恢复后继续执行提交。
- /api/transaction/commit:提交当前事务,持久化变更。
- /api/transaction/rollback:回滚当前事务,回滚变更。
- /api/transaction/load:发送数据,可以使用已有的事务,如果没有指定事务label,会随机生成一个label进行数据写入。
ps:事务去重:复用StarRocks现有的label标签机制,通过标签绑定事务,实现事务的“至多一次(At-Most-Once)”语义。
不同阶段对应的StarRocks内部流程如下:
- begin + load 阶段
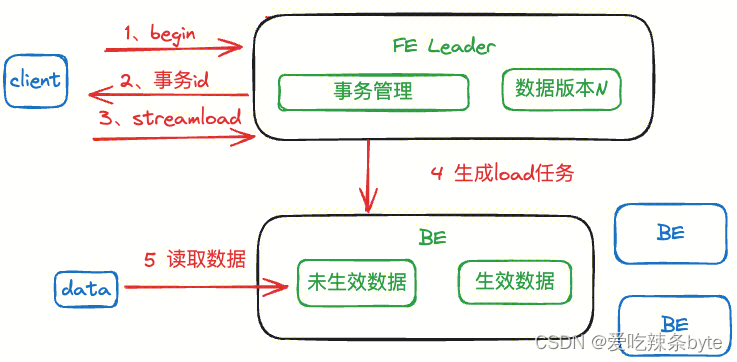
开始数据导入时,客户端通过begin transaction接口开启一个新的事务,提交给FE leader中的事务管理模块,事务管理模块充当了两阶段提交中的事务管理者,用来管理事务的原子性、事务的回滚等。每一个事务可以设置一个label,StarRocks FE会检查本次begin transaction 请求的label是否已经存在,如果label在系统中不存在,则会为当前label开启一个新的事务。begin阶段之后可以使用该label对StarRocks进行Stream Load导入,Stream Load返回成功的条件是数据的副本数量超过了tablet数据分片的副本数的一半,剩下的一本由StarRocks的副本机制保证完整写入。
-
Commit 阶段
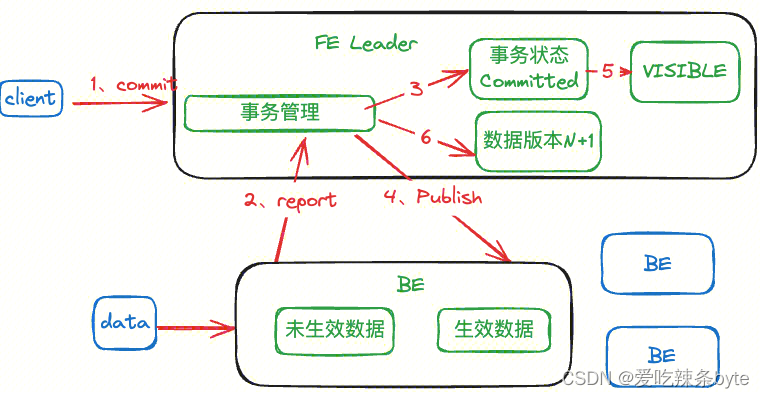
FE接受commit信息之后,会将事务状态改成commited。之后事务管理器会向BE节点发送publish version信息,BE收到publish中的版本信息后,会将本地的消息版本改成本次事务对应的版本;同时会向FE上报,表示数据版本已经成功修改,之后FE会将事务状态改成VISIBLE。此时数据对用户可见,客户端执行查询的时候,会比较版本号,从而解决读写版本冲突;
-
Rollback 阶段
如果写入过程或者commit过程失败,则事务abort,清理事务的任务在BE节点异步执行,将数据导入过程中生成的批次数据标记为不可用,这些数据之后会从BE上被删除。
总结:
- StarRocks可以通过给数据设置版本控制(rowset version)来解决读写冲突。
- StarRocks通过引入FE中的事务管理实现了两阶段导入,保证了导入的原子性。
三、InLong 实时写入StarRocks原理
3.1 InLong概述
Apache InLong(应龙) 提供自动、安全、可靠和高性能的数据传输能力,方便业务快速构建基于流式的数据分析、建模和应用。该模块阐述 InLong基于事务接口,实现数据实时写入 StarRocks的技术原理,主要对写入过程中的精准一次性保证进行阐述。
3.2 基本原理
InLong实时写入StarRocks如下图所示,实时写入通过 Flink实时任务来实现,Flink任务写入侧的具体执行逻辑如下:
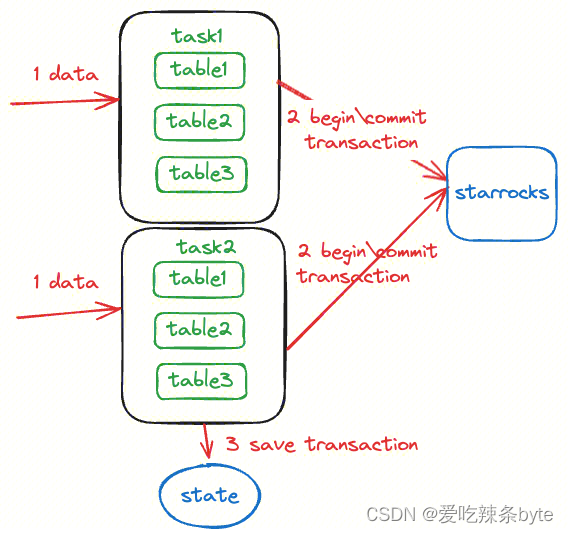
- 根据Flink并行度配置生成多个Task执行写入;
- 每一个Task基于StarRocks提供的Stream Load机制进行写入,每一个Flink checkpoint周期会使用相同的StarRocks事务label;
- Flink开始做checkpoint时,当前写入的table以及对应的StarRocks事务label会一并存入到state状态中;
- Flink写入算子收到checkpoint完成的消息时,将所有的table对应的事务进行commit,此时数据才会对用户可见;
3.3 详细流程
3.3.1 任务写入数据
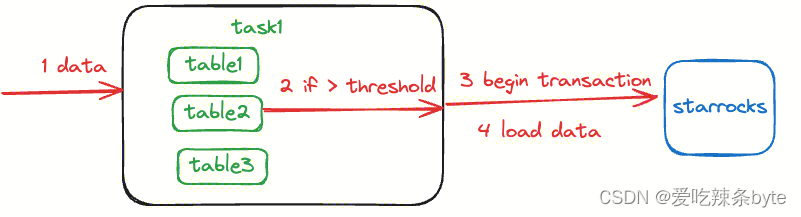
在写入数据时,首先不会直接将数据写入到StarRocks中,而是将每个table对应的数据进行缓存。当批次数据达到一定大小之后才会调用一次刷新flush操作,flush操作包括以下流程:
- 启动一个事务,每一个Flink checkpoint周期会使用相同的StarRocks事务label,调用/api/transaction/begin
- 使用该label进行数据写入,调用 /api/transaction/load 实际写入数据
这种写入流程保证了:
- 每次写入相同的事务label,提交时可以提交一整个checkpoint周期的所有的数据,单个checkpointh只会提交一次,重复提交StarRocks不会生效。
- 每次写入都是批次写入,缓解StarRocks写入压力。(内存攒批+flush)
3.3.2 任务保存检查点
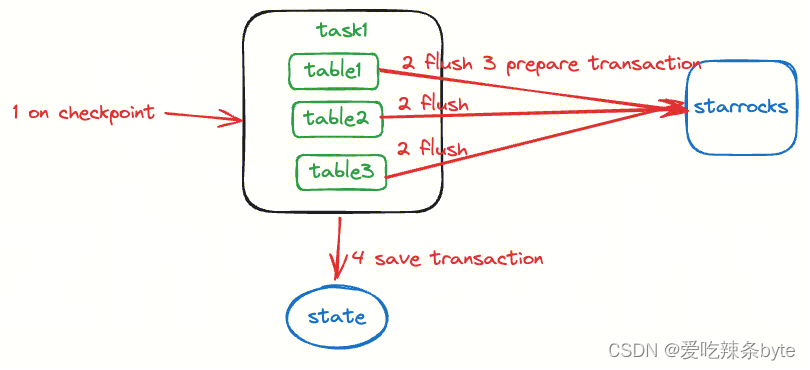
任务保存检查点的时候会进行以下流程:
- 对目前内存中保存的所有表数据都进行flush,确保内存中所有的数据已经导入到StarRocks,当前数据在StarRocks中不可见
- 对所有的表对应的导入事务,进行prepare调用(预提交事务) ,如果prepare失败,则表示当前StarRocks不支持该事务的提交,调用abort接口,并失败重试
- 对于prepare成功的事务,保存在当前flink状态信息中state
3.3.3 任务如何确认保存点成功
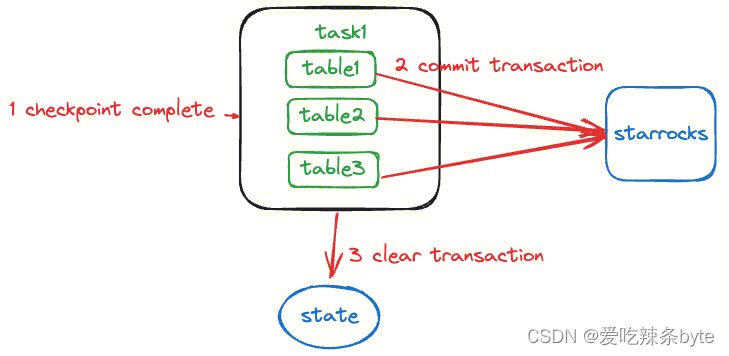
当Flink Task收到checkpoint检查点已经完成的确认信息后,对checkpoint过程中保存的事务信息进行commit,如果commit失败,则重启任务。commit成功的事务会在checkpoint中删除。
3.3.4 任务如何初始化
当任务启动时,Task拿到上一个保存点的状态信息,恢复版本暂时未commit的事务信息,对checkpoint id小于等于当前checkpoint id的事务进行提交。
3.4 Exactly Once 保证
要保证流式写入的 Exactly once语义等同于:需要保证数据的不重复以及不丢失。
Exactly once语义的实现需要合理的定义checkpoint间隔,优点是在各种异常情况下保障数据不丢失不重复,缺点是数据可见时间取决于checkpoint间隔(flink将所有的table对应的事务进行commit,此时数据才会对用户可见)
3.4.1 数据不重复保证
基于Flink的流式任务产生数据重复的原因主要是Flink从某一个checkpoint启动时,重复提交之前已经提交过的数据。InLong实时写入中,状态中会记录本checkpoint下prepare成功的事务id,故障恢复时,会提交该事务id,如果该事务id在之前的流程中被提交过,StarRocks会返回报错信息表示该事务id已经提交过,该次提交会被忽略,通过这种机制保证了数据的不重复。
3.4.2 数据不丢失保证
假设在数据写入过程中,有部分数据写入失败,Flink checkpoint机制会保证任务重启后从上一个保存点启动,Source端会从上次保存消费位置开始消费,这样能够保证数据的不丢失,之前写入失败的数据会在重启后继续执行写入。
四、Stream Load事务接口使用
4.1 事务接口优势
4.1.1 Exactly-once语义
- 通过“预提交事务”,“提交事务”,方便实现跨系统的两阶段提交。例如配合在Flink实现“精确一次(Exactly-once)”语义。
4.1.2 提升导入性能
在通过程序提交Stream Load作业的场景中,Stream Load事务接口允许在一个导入作业中按需合并发送多次小批量的数据后“提交事务”,从而能减少数据导入的版本,提升导入性能。
4.2 事务接口使用限制
事务接口当前具有如下使用限制:
-
只支持单库单表事务,未来将会支持跨库多表事务。
-
只支持单客户端并发数据写入,未来将会支持多客户端并发数据写入。
-
支持在单个事务中多次调用数据写入接口
/api/transaction/load来写入数据,但是要求所有/api/transaction/load接口中的参数设置必须保持一致。 -
导入CSV格式的数据时,需要确保每行数据结尾都有行分隔符。
4.3 事务接口使用案例
具体使用案例见官网:
使用 Stream Load 事务接口导入 | StarRocks
参考文章:
更多【r语言-StarRocks——Stream Load 事务接口实现原理】相关视频教程:www.yxfzedu.com
相关文章推荐
- jvm-JVM在线分析-监控工具(jps, jstat, jstatd) - 其他
- 交友-如何设计开发一对一交友App吸引更多活跃用户 - 其他
- 学习-深度学习/pytoch/pycharm学习过程中遇到的问题 - 其他
- jvm-在GORM中使用并发 - 其他
- aws-aws亚马逊:什么是 Amazon EC2? - 其他
- aws-aws亚马逊云:置以使用 Amazon EC2!!! - 其他
- 人工智能-创新功能点展望:探索未来一对一交友App开发的趋势和可能性 - 其他
- jvm-JVM详解 - 其他
- mysql-mysql基础 --子查询 - 其他
- jvm-JVM-虚拟机的故障处理与调优案例分析 - 其他
- 前端-TypeScript深度剖析:TypeScript 中枚举类型应用场景? - 其他
- jvm-JavaEE初阶学习:JVM(八股文) - 其他
- 云原生-k8s笔记资源限制,亲和和性 污点和容忍 - 其他
- jvm-学习笔记4——JVM运行时数据区梳理 - 其他
- jvm-【面经】讲一下你对jvm和jmm的了解 - 其他
- rabbitmq-RabbitMQ的高级特性 - 其他
- 数据库-长安链可验证数据库,保证数据完整性的可信存证方案 - 其他
- 前端框架-React Hooks为什么要在顶层使用? - 其他
- flink-Flink之Java Table API的使用 - 其他
- c#-C# List<T>.IndexOf()方法的使用 - 其他
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
- 编程技术-Python标准库有哪些
- 软件逆向-记Github上下载到的WinExplorer夹带私货
- 编程技术-读取W25Q64的设备ID时输出0xff
- 金融-可以写进简历的软件测试项目(银行/金融/电商/商城......)
- 百度-想要创建百度百科词条怎么做?
- c#-C#基于inpoutx64读写ECRAM硬件信息
- java-JavaScript如何实现钟表效果,时分秒针指向当前时间,并显示当前年月日,及2024春节倒计时,源码奉上
- c++-Linux驱动应用层与内核层之间的数据传递
- 人工智能-读书笔记:彼得·德鲁克《认识管理》第11章 若干例外及经验教训
- 运维-短时间不点击云服务器,自动化断开连接,怎么设置长时间