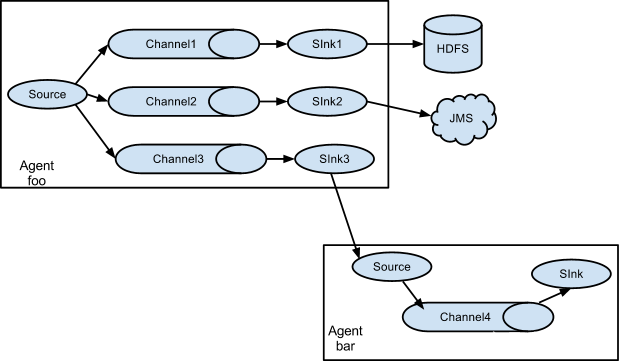



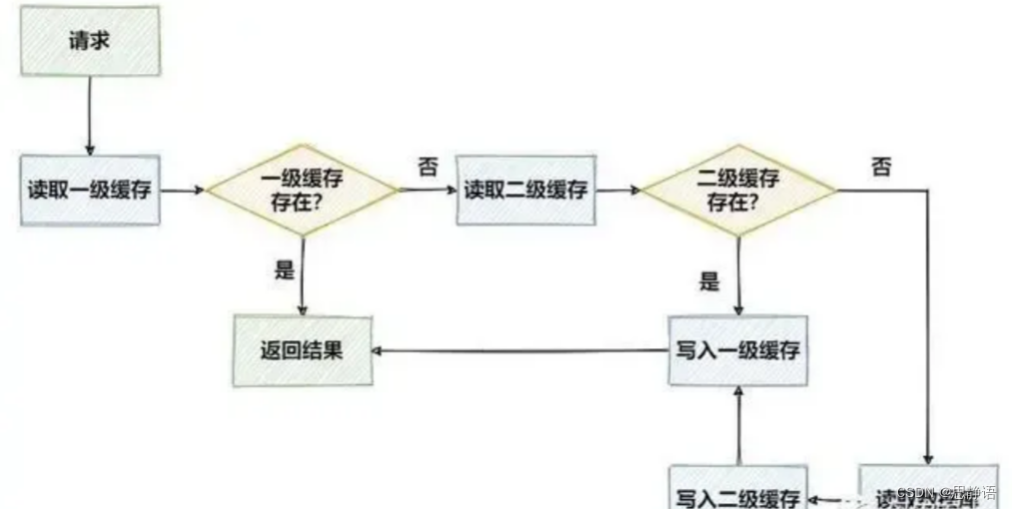

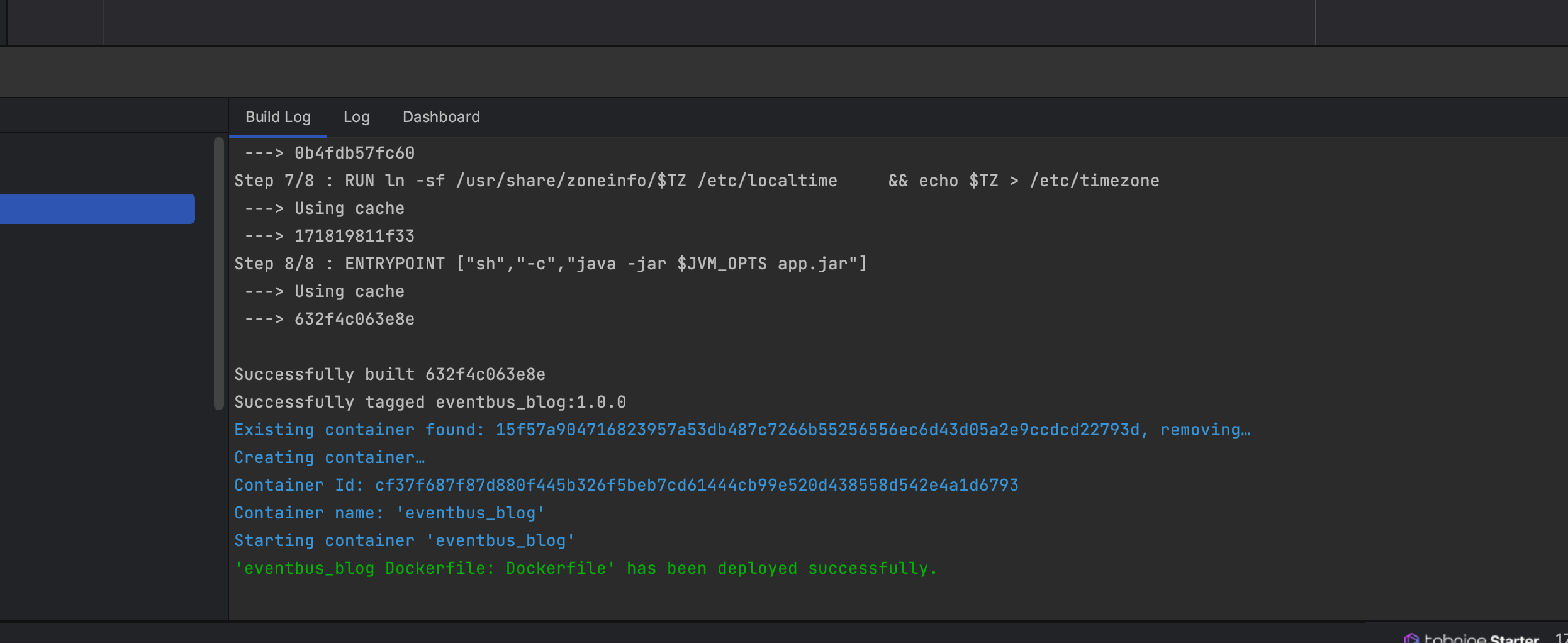
共 24 条
- 1
- 2
- 3
记录自己的技术轨迹
文章规则:
1):文章标题请尽量与文章内容相符
2):严禁色情、血腥、暴力
3):严禁发布任何形式的广告贴
4):严禁发表关于中国的政治类话题
5):严格遵守中国互联网法律法规
6):有侵权,疑问可发邮件至service@yxfzedu.com
近期原创 更多
- html5-1.2 HTML5
- hive-项目实战:抽取中央控制器 DispatcherServlet
- kafka-Kafka(消息队列)--简介
- github-github 上传代码报错 fatal: Authentication failed for ‘xxxxxx‘
- matlab-【MATLAB源码-第69期】基于matlab的LDPC码,turbo码,卷积码误码率对比,码率均为1/3,BPSK调制。
- 爬虫-Python 爬虫基础
- ui-Qt6,使用 UI 界面完成命令执行自动化的设计
- 软件逆向-分析运行过的反汇编代码
- 企业安全-Rootkit病毒利用“天龙八部”私服传播,可劫持网页
- 物联网-基于STM32的设计智慧超市管理系统(带收银系统+物联网环境监测)
