【深度优先-利用Spark将Kafka数据流写入HDFS】此文章归类为:[ "深度优先", "linq", "spark", "kafka", "大数据" ]。 利用Spark将Kafka数据流写入HDFS
原创 周杰伦 24天前 阅读: 20 阅读时长: 9分钟
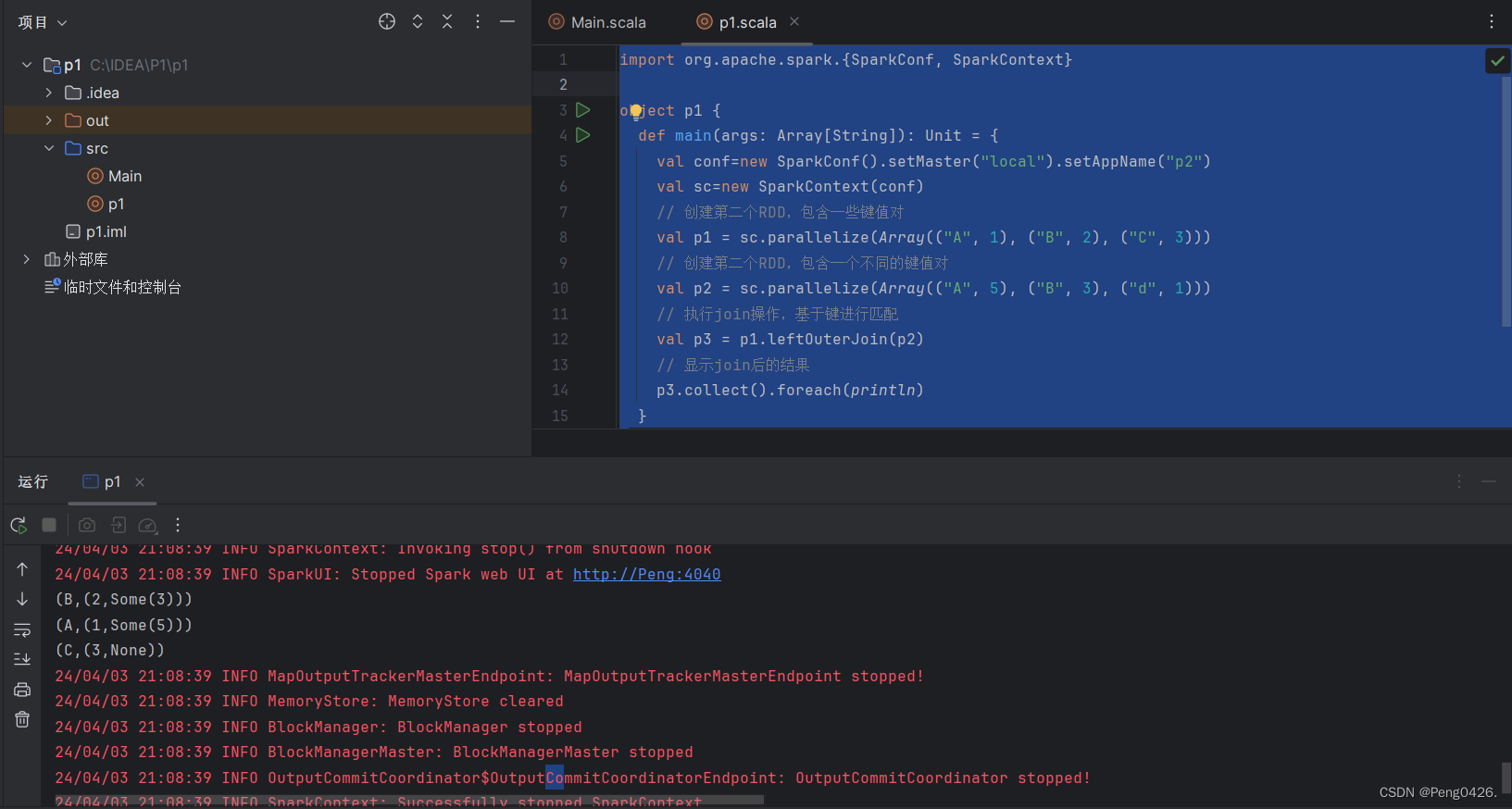
【spark-Spark-Scala语言实战(11)】此文章归类为:[ "spark", "分布式", "大数据" ]。 在之前的文章中,我们学习了如何在spark中使用RDD中的cartesian,subtract最终两种方法。想了解的朋友可以查看这篇文章。同时,希望我的文章能帮助到你,如果觉得我的文章
原创 周杰伦 25天前 阅读: 26 阅读时长: 9分钟
【python-Spark GraphX 图操作】此文章归类为:[ "python", "spark", "分布式", "大数据", "开发语言" ]。 Spark GraphX 图操作 在GraphX中
原创 周杰伦 25天前 阅读: 17 阅读时长: 9分钟
【算法-大数据主要组件HDFS Iceberg Hadoop spark介绍】此文章归类为:[ "算法", "深度优先", "spark", "hadoop", "大数据" ]。 HDFS
原创 周杰伦 1个月前 阅读: 23 阅读时长: 9分钟
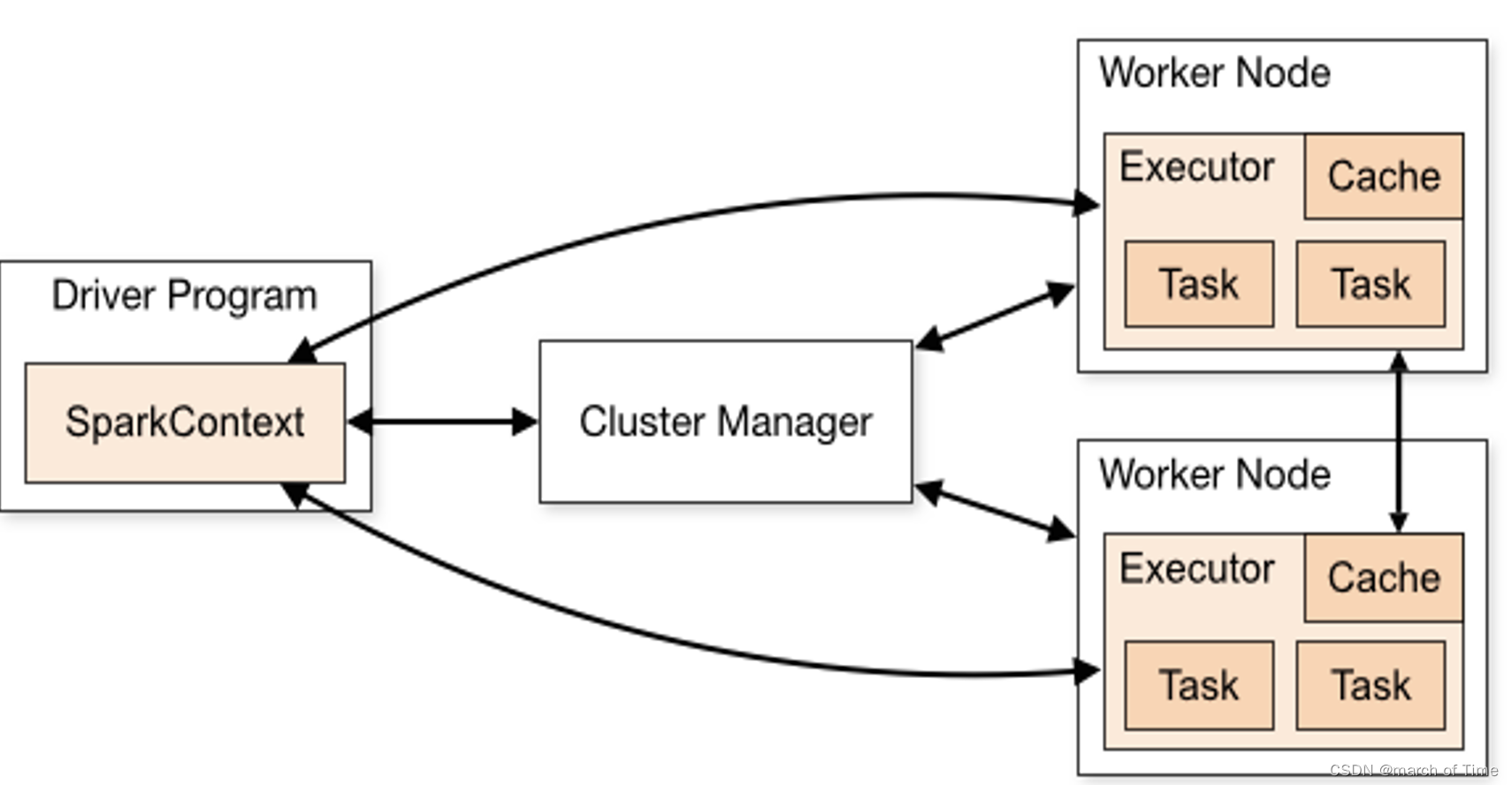
【spark-Spark 安装(集群模式)】此文章归类为:[ "spark", "分布式", "大数据" ]。 Spark 安装(集群模式) 实际生产环境一般不会用本地模式搭建Spar
原创 周杰伦 1个月前 阅读: 25 阅读时长: 9分钟
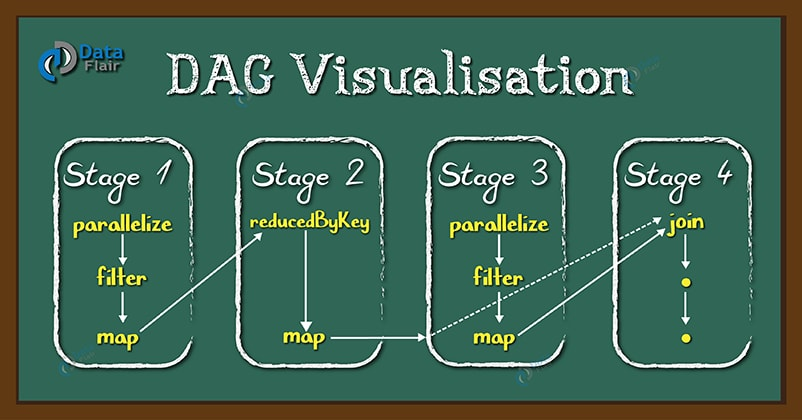
【spark-Spark DAG】此文章归类为:[ "spark", "分布式", "大数据" ]。 Spark DAG 什么是DAG DAG 是一组顶点和边的组合。顶点代表了 RDD, 边代表了
原创 周杰伦 1个月前 阅读: 23 阅读时长: 5分钟
【分布式-分布式简介】此文章归类为:[ "分布式" ]。 来简单介绍一下分布式 文章目录 目录 一、分布式是什么? 二、分布式的特点 三、常见的后端分布式框架 总结 一、分布式是什么? 分布式系统(Distributed System)是由一组相互
原创 周杰伦 1个月前 阅读: 29 阅读时长: 8分钟
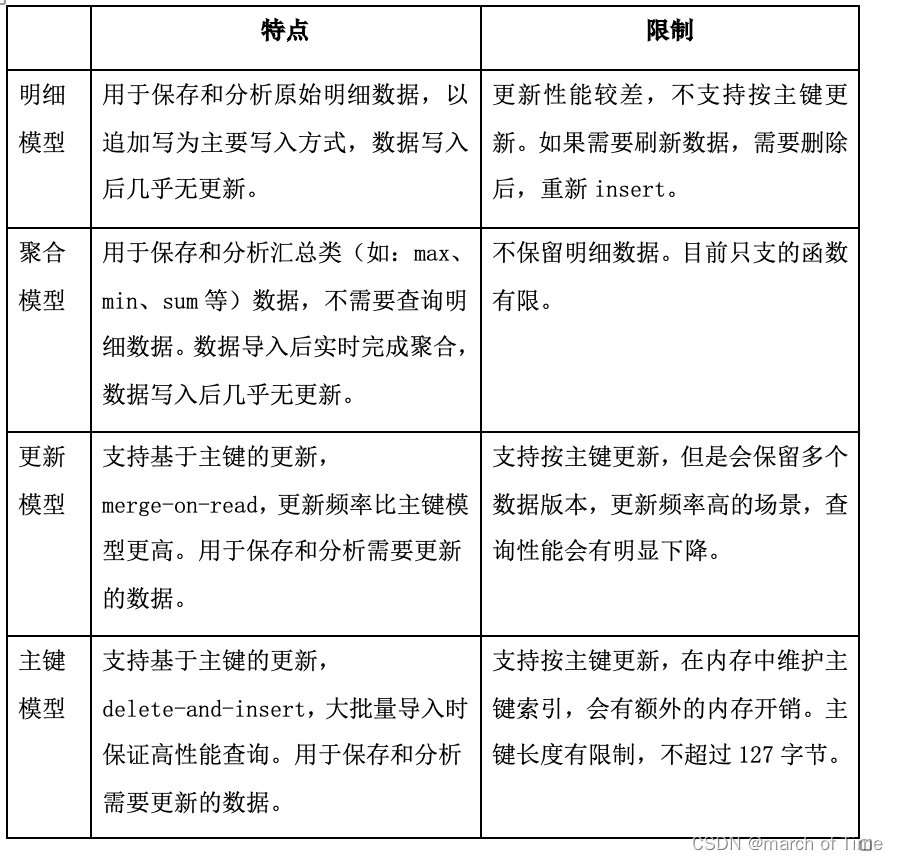
【学习-StarRocks学习笔记】此文章归类为:[ "学习", "笔记", "r语言", "开发语言" ]。 介绍场景建表明细模型聚合模型更新模型主键模型 介绍 StarR
原创 周杰伦 1个月前 阅读: 20 阅读时长: 9分钟
【rpc-Netty核心原理剖析与RPC实践0--5】此文章归类为:[ "rpc", "网络", "网络协议" ]。 Netty核心原理剖析与RPC实践 0、为什么要学习 Netty? https
原创 周杰伦 1个月前 阅读: 36 阅读时长: 9分钟
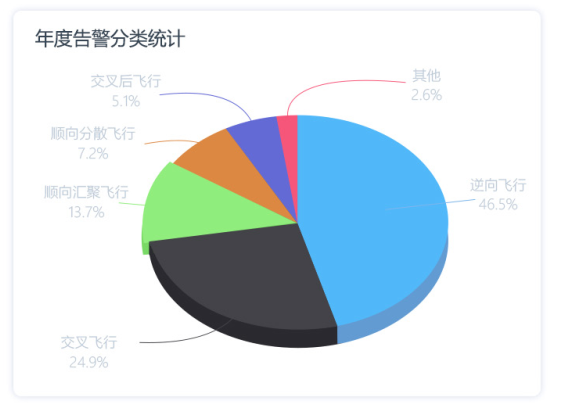
【前端-年度告警分类统计】此文章归类为:["前端","javascript","ecmascript","开发语言","分类"]。 1、打开前端Vue项目kongguan_web,完成前端src/components/echart/YearWarningChart.vue页面设计 在YearWarningChart.vue页面添加div设计 <template>
原创 周杰伦 1个月前 阅读: 29 阅读时长: 9分钟